Sqoop介绍
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
1.sqoop下载
https://mirrors.tuna.tsinghua.edu.cn/apache/sqoop/1.4.7/
2.sqoop上传到服务器 并解压到相应的目录
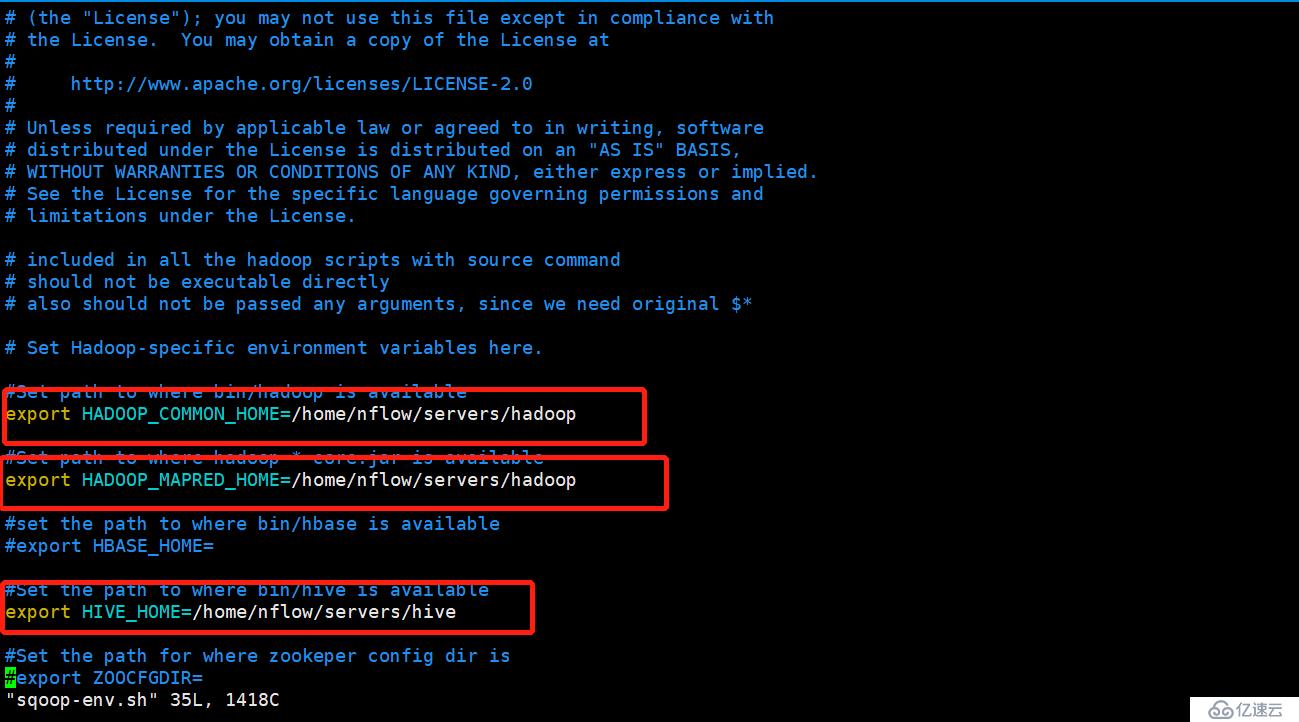
3.修改sqoop的配置文件

4.修改配置文件
5.拷贝sqoop需要的mysql 数据库驱动
cp /home/nflow/servers/hive/lib/mysql-connector-java-5.1.26-bin.jar /home/nflow/servers/sqoop-1.4.7/lib/6.启动sqoop测试 (可以看出连接数据库了)
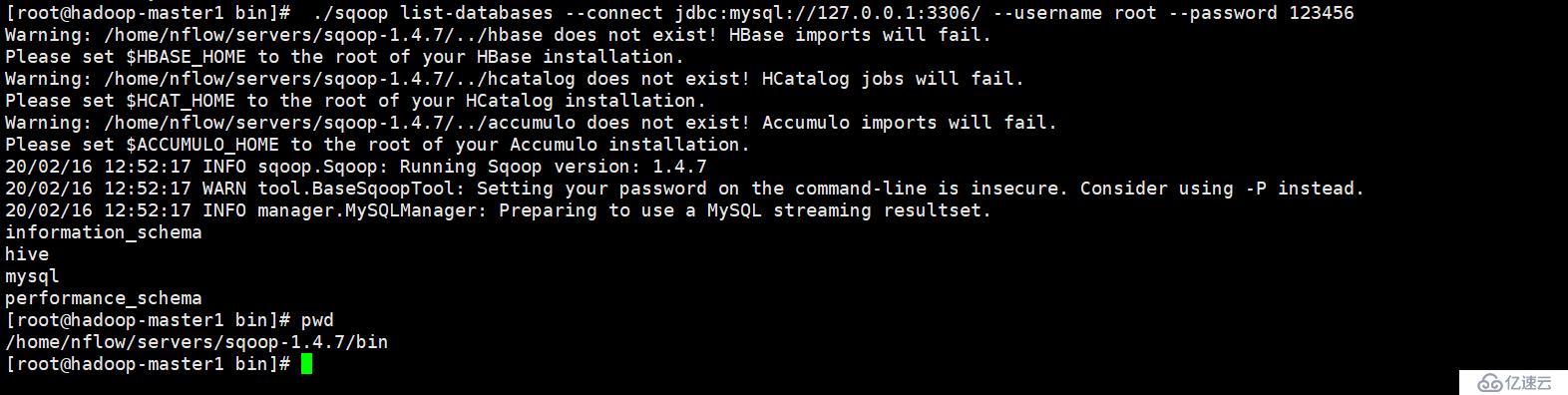
./sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root --password 1234567.sqoop导入数据
从博主拿过来的sql
drop database if exists userdb;
create database userdb;
use userdb;
drop table if exists emp;
drop table if exists emp_add;
drop table if exists emp_conn;
CREATE TABLE emp(
id INT NOT NULL,
name VARCHAR(100),
deg VARCHAR(100),
salary BIGINT,
dept VARCHAR(50)
);
CREATE TABLE emp_add(
id INT NOT NULL,
hno VARCHAR(50),
street VARCHAR(50),
city VARCHAR(50)
);
CREATE TABLE emp_conn(
id INT NOT NULL,
phno VARCHAR(50),
email VARCHAR(50)
);
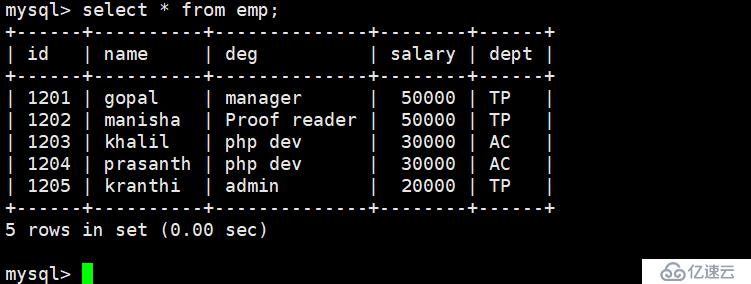
insert into emp values(1201,'gopal','manager','50000','TP');
insert into emp values(1202,'manisha','Proof reader','50000','TP');
insert into emp values(1203,'khalil','php dev','30000','AC');
insert into emp values(1204,'prasanth','php dev','30000','AC');
insert into emp values(1205,'kranthi','admin','20000','TP');
insert into emp_add values(1201,'288A','vgiri','jublee');
insert into emp_add values(1202,'108I','aoc','sec-bad');
insert into emp_add values(1203,'144Z','pgutta','hyd');
insert into emp_add values(1204,'78B','old city','sec-bad');
insert into emp_add values(1205,'720X','hitec','sec-bad');
insert into emp_conn values(1201,'2356742','gopal@tp.com');
insert into emp_conn values(1202,'1661663','manisha@tp.com');
insert into emp_conn values(1203,'8887776','khalil@ac.com');
insert into emp_conn values(1204,'9988774','prasanth@ac.com');
insert into emp_conn values(1205,'1231231','kranthi@tp.com');
————————————————
####感谢此博主 版权为别人的版权 我只是试用下 版权声明:本文为CSDN博主「记录每一份笔记」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yumingzhu1/article/details/80678525从mysql 到 hdfs
#/bin/bash
./bin/sqoop import \
--connect jdbc:mysql://192.168.249.10:3306/userdb \
--username root \
--password 123456 \
--table emp \
--m 1
[nflow@hadoop-master1 sqoop-1.4.7]$ pwd
/home/nflow/servers/sqoop-1.4.7
[nflow@hadoop-master1 sqoop-1.4.7]$
默认导出的位置为 /usr/用户/表名 数据库不能用localhost或者127.0.0.1 不然会报错 必须要用IP地址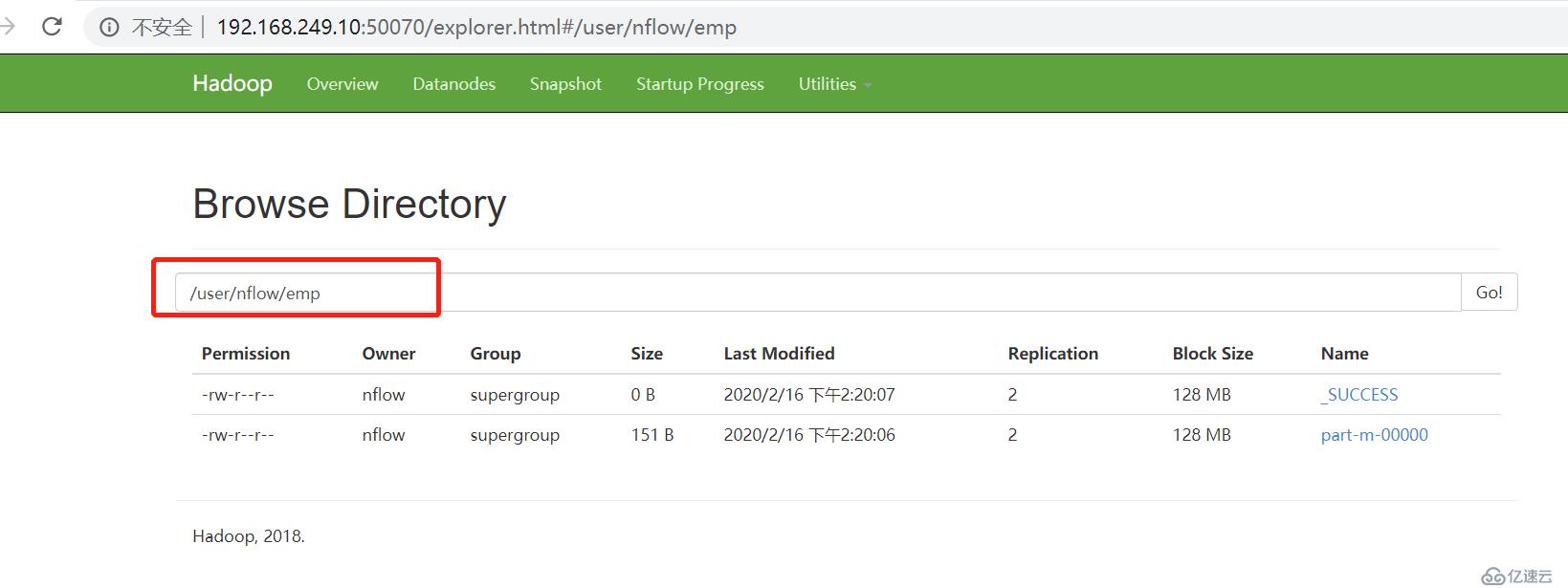

HDFS 目录下次在导入不能重复
重新修改脚本如下 这样每次都可以生成新的


mysql数据导入到hive里面
数据库数据

./sqoop import \
--connect jdbc:mysql://192.168.249.10:3306/userdb \ ##userdb
--username admin \ #数据库admin用户
--password 123456 \ #数据库admin用户的密码
--table emp_add \ #数据库admin里面的emp_add表
--delete-target-dir \ #每次删除
--num-mappers 1 \ ##mapreduce 进程个数
--hive-import \ ##指定hive
--hive-database default \ ##hive的默认数据库
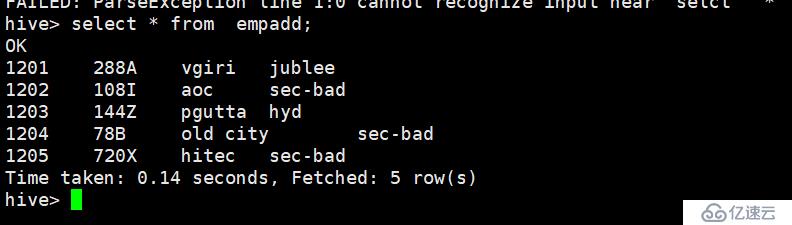
--hive-table empadd \ ##hive里面 default 数据的表名称
--fields-terminated-by '\t' ###换行 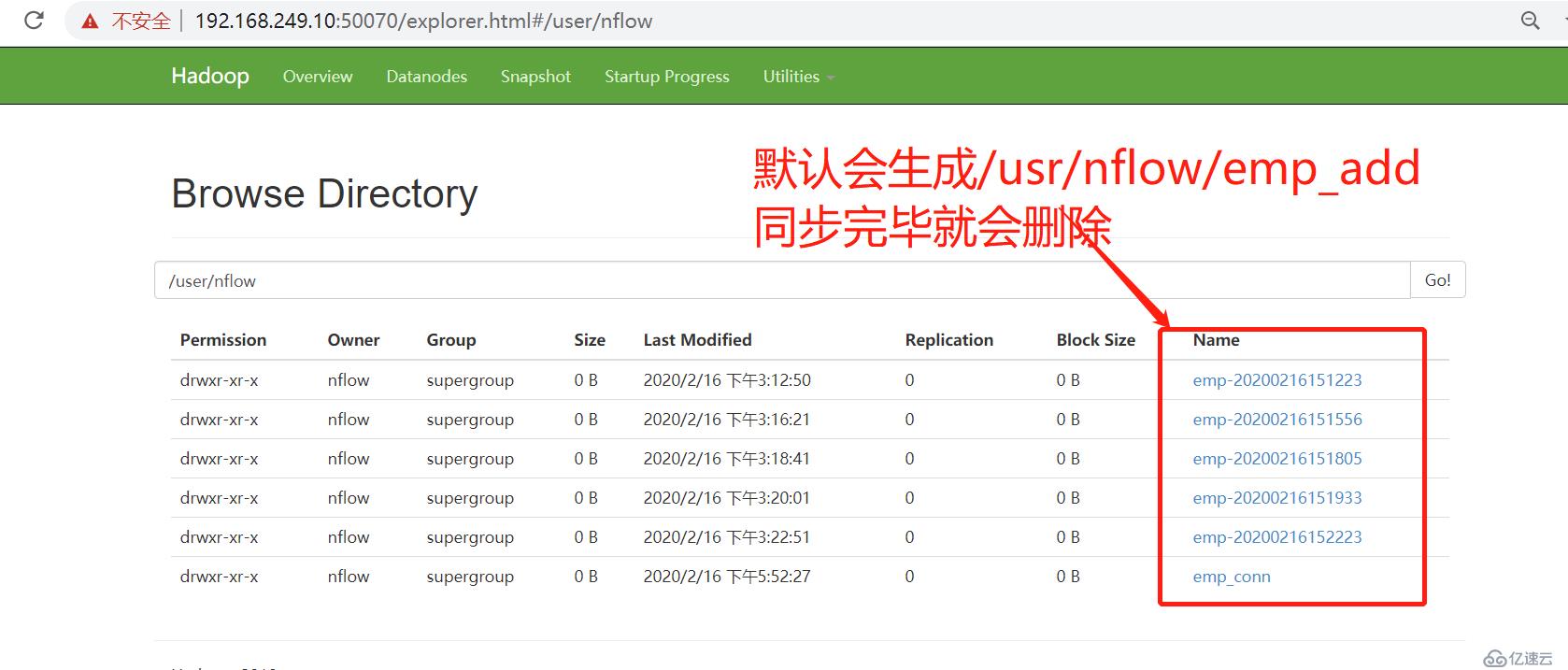
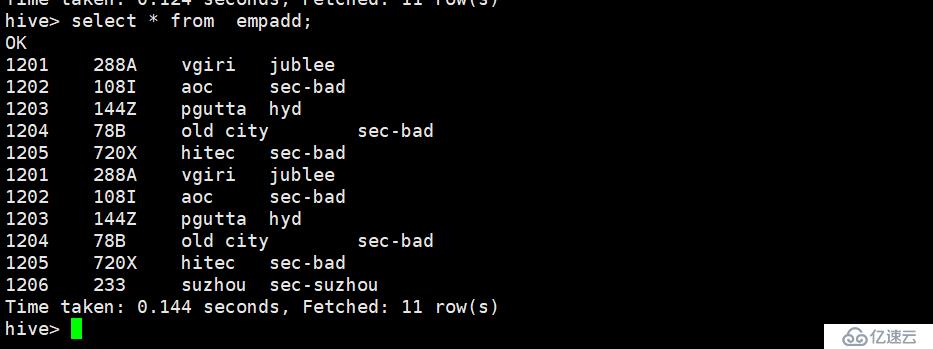
sqoop再次导入同一张表测试 测试结果为 如果数据库有新增的数据 那么hive将会也会拿过来,导致重复 如下图,如何避免这个问题呢 sqoop的增量同步
#######sqoop增量同步到hive
id大于1207 的会同步 不会导致重复
./sqoop import \
--connect jdbc:mysql://192.168.249.10:3306/userdb \
--username admin \
--password 123456 \
--table emp_add \
--num-mappers 1 \
--hive-import \
--hive-database default \
--hive-table empadd \
--fields-terminated-by '\t' \
--incremental append \
--check-column id \
--last-value 1207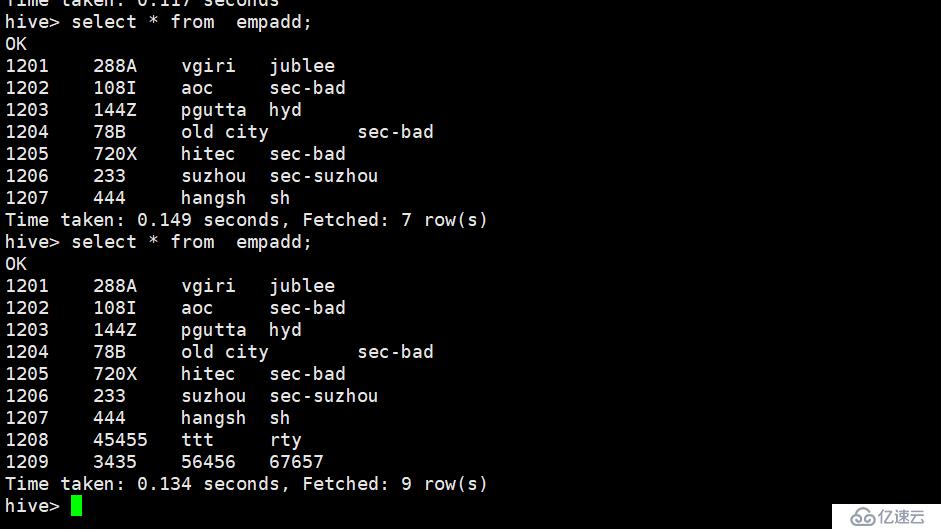
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



