阅读目录:
1.开篇介绍
2.NET并行计算基本介绍
3.并行循环使用模式
3.1并行For循环
3.2并行ForEach循环
3.3并行LINQ(PLINQ)
最近这几天在捣鼓并行计算,发现还是有很多值得分享的意义,因为我们现在很多人对它的理解还是有点不准确,包括我自己也是这么觉得,所以整理一些文章分享给在使用.NET并行计算的朋友和将要使用.NET并行计算的朋友;
NET并行编程推出已经有一段时间了,在一些项目代码里也时不时会看见一些眼熟的并行计算代码,作为热爱技术的我们怎能视而不见呢,于是捣鼓了一番跟自己的理解恰恰相反,看似一段能提高处理速度的并行代码为能起效果,跟直接使用手动创建的后台线程处理差不多,这不太符合我们对.NET并行的强大技术的理解,所以自己搞了点资料看看,实践了一下,发现在使用.NET并行技术的时候需要注意一些细节,这些细节看代码是看不出来的,所以我们看到别人这么用我们就模仿这么用,我们需要自己去验证一下到底能提高多少处理速度和它的优势在哪里;要不然效率上不去反而还低下,查看代码也不能很好的断定哪里出了问题,所以还是需要系统的学习总结才行;
现在的系统已经不在是以前桌面程序了,也不是简单的WEB应用系统,而是大型的互联网社区、电子商务等大型系统,具有高并发,大数据、SOA这些相关特性的复杂体系的综合性开放平台;.NET作为市场占有率这么高的开发技术,有了一个很强大的并行处理技术,目的就是为了能在高并发的情况下提高处理效率,提高了单个并发的处理效率也就提高了总体的系统的吞吐量和并发数量,在单位时间内处理的数据量将提高不是一个系数两个系数;一个处理我们提高了两倍到三倍的时间,那么在并发1000万的顶峰时时不时很客观;
既然是.NET并行计算,那么我们首先要弄清楚什么叫并行计算,与我们以前手动创建多线程的并行计算有何不同,好处在哪里;我们先来了解一下什么是并行计算,其实简单形容就是将一个大的任务分解成多个小任务,然后让这些小任务同时的进行处理,当然纯属自己个人理解,当然不是很全面,但是我们使用者来说足够了;
在以前单个CPU的情况下只能靠提高CPU的时钟频率,但是毕竟是有极限的,所以现在基本上是多核CPU,个人笔记本都已经基本上是4核了,服务器的话都快上20了;在这样一个有利的计算环境下,我们的程序在处理一个大的任务时为了提高处理速度需要手动的将它分解然后创建Thread来处理,在.NET中我们一般都会自己创建Thread来处理单个子任务,这大家都不陌生,但是我们面临的问题就是不能很好的把握创建Thread的个数和一些参数的控制,毕竟.NET并行也是基于以前的Thread来写的,如何在多线程之间控制参数,如何互斥的执行的线程顺序等等问题,导致我们不能很好的使用Thread,所以这个时候.NET并行框架为我们提供了一个很好的并行开发平台,毕竟大环境就是多核时代;
下面我们将接触.NET并行计算中的第一个使用模式,有很多并行计算场景,归结起来是一系列使用模式;
并行循环模式就是将一个大的循环任务分解成多个同时并行执行的小循环,这个模式很实用;我们大部分处理程序的逻辑都是在循环和判断之间,并行循环模式可以适当的改善我们在操作大量循环逻辑的效率;
我们看一个简单的例子,看到底提升了多少CPU利用率和执行时间;
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
using System.Diagnostics;
namespace ConsoleApplication1.Data
{
public class DataOperation
{
private static List<Order> orders = new List<Order>();
static DataOperation()
{
for (int i = 0; i < 9000000; i++)
{
orders.Add(new Order() { Oid = Guid.NewGuid().ToString(), OName = "OrderName_" + i.ToString() });
}
}
public void Operation()
{
Console.WriteLine("Please write start keys:");
Console.ReadLine();
Stopwatch watch = new Stopwatch();
watch.Start();
orders.ForEach(order =>
{
order.IsSubmit = true;
int count = 0;
for (int i = 0; i < 2000; i++)
{
count++;
}
});
watch.Stop();
Console.WriteLine(watch.ElapsedMilliseconds);
}
public void TaskOperation()
{
Console.WriteLine("Please write start keys:");
Console.ReadLine();
Stopwatch watch = new Stopwatch();
watch.Start();
Parallel.ForEach(orders, order =>
{
order.IsSubmit = true;
int count = 0;
for (int i = 0; i < 2000; i++)
{
count++;
}
});
watch.Stop();
Console.WriteLine(watch.ElapsedMilliseconds);
}
}
}这里的代码其实很简单,在静态构造函数中我初始化了九百万条测试数据,其实就是Order类型的实例,这在我们实际应用中也很常见,只不过不是一次性的读取这么多数据而已,但是处理的方式基本上差不多的;然后有两个方法,一个是Operation,一个是TaskOperation,前者顺序执行,后者并行执行;
在循环的内部我加上了一个2000的简单空循环逻辑,为什么要这么做后面会解释介绍(小循环并行模式不会提升性能反而会降低性能);这里是为了让模拟场景更真实一点;
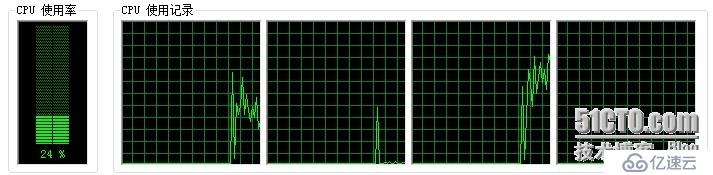
我们来看一下测试相关的数据:i5、4核测试环境,执行时间为42449毫秒,CPU使用率为25%左右,4核中只使用了1和3的,而其他的都属于一般处理状态;
图1:
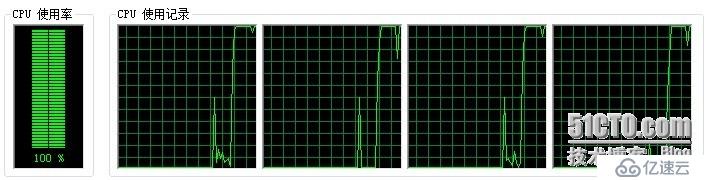
我们再来看一下使用并行计算后的相关数据:i5、4核测试环境,执行时间为19927毫秒,CPU利用率为100%,4核中全部到达顶峰;
图2:
这一个简单的测试例子,当然我只测试了两三组数据,基本上并行计算的速度要快于单线程的处理速度的2.1倍以上,当然还有其他因素在里面这里就不仔细分析了,起到抛砖引玉的作用;
在使用for循环的时候有相应的Parallel方式使用for循环,我们直接看一下示例代码,还是以上面的测试数据为例;
Parallel.For(0, orders.Count, index =>
{
//
});第一个参数是索引的开始,第二个参数是循环总数,第三个是执行体,参数是索引值;使用起来其实很简单的;
同样ForEach也是很简单的,还是使用上面的测试数据为例;
Parallel.ForEach(orders, order =>
{
order.IsSubmit = true;
int count = 0;
for (int i = 0; i < 2000; i++)
{
count++;
}
});在Parallel类中有ForEach方法,第一个参数是迭代集合,第二个是每次迭代的item;
其实Parallel为我们封装了一个简单的调用入口,其实是依附于后台的Task框架的,因为我们常用的就是循环比较多,毕竟循环是任务的入口调用,所以我们使用并行循环的时候还是很方便的;
首先PLINQ是只针对Linq to Object的,所以不要误以为它也可以使用于Linq to Provider,当然自己可以适当的封装;现在LINQ的使用率已经很高了,我们在做对象相关的操作时基本上都在使用LINQ,很方便,特别是Select、Where非常的常用,所以.NET并行循环也在LINQ上进行了一个封装,让我们使用LINQ的时候很简单的使用并行特性;
LINQ核心原理的文章:http://www.cnblogs.com/wangiqngpei557/category/421145.html
根据LINQ的相关原理,知道LINQ是一堆扩展方法的链式调用,PLINQ就是扩展方法的集合,位于System.Linq.ParallelEnumerable静态类中,扩展于ParallelQuery<TSource>泛型类;
System.Linq.ParallelQuery<TSource>类:
using System.Collections;
using System.Collections.Generic;
namespace System.Linq
{
// 摘要:
// 表示并行序列。
//
// 类型参数:
// TSource:
// 源序列中的元素的类型。
public class ParallelQuery<TSource> : ParallelQuery, IEnumerable<TSource>, IEnumerable
{
// 摘要:
// 返回循环访问序列的枚举数。
//
// 返回结果:
// 循环访问序列的枚举数。
public virtual IEnumerator<TSource> GetEnumerator();
}
}System.Linq.ParallelEnumerable类:
// 摘要:
// 提供一组用于查询实现 ParallelQuery{TSource} 的对象的方法。 这是 System.Linq.Enumerable 的并行等效项。
public static class ParallelEnumerable我们在用的时候只需要将它原本的类型转换成ParallelQuery<TSource>类型就行了;
var items = from item in orders.AsParallel() where item.OName.Contains("1") select item;Linq 的扩展性真的很方便,可以随意的封装任何跟查询相关的接口;
作者:王清培
出处:http://wangqingpei557.blog.51cto.com/
本文版权归作者和51CTO共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





