本篇内容介绍了“Redis哈希分片原理是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
如果Redis只用复制功能做主从,那么当数据量巨大的情况下,单机情况下可能已经承受不下一份数据,更不用说是主从都要各自保存一份完整的数据。在这种情况下,数据分片是一个非常好的解决办法。
Redis的Cluster正是用于解决该问题。它主要提供两个功能:
自动对数据分片,落到各个节点上
即使集群部分节点失效或者连接不上,依然可以继续处理命令
对于第二点,它的功能有点类似于Sentienl的故障转移(可以了解下之前Sentinel的文章),在这里不细说。下面详细了解下Redis的槽位分片原理,在此之前,先了解下分布式简单哈希算法和一致性哈希算法,以帮助理解槽位的作用。
假设有三台机,数据落在哪台机的算法为
c = Hash(key) % 3
例如key A的哈希值为4,4%3=1,则落在第二台机。Key ABC哈希值为11,11%3=2,则落在第三台机上。
利用这样的算法,假设现在数据量太大了,需要增加一台机器。A原本落在第二台上,现在根据算法4%4=0,落到了第一台机器上了,但是第一台机器上根本没有A的值。这样的算法会导致增加机器或减少机器的时候,引起大量的缓存穿透,造成雪崩。
在1997年,麻省理工学院的Karger等人提出了一致性哈希算法,为的就是解决分布式缓存的问题。
在一致性哈希算法中,整个哈希空间是一个虚拟圆环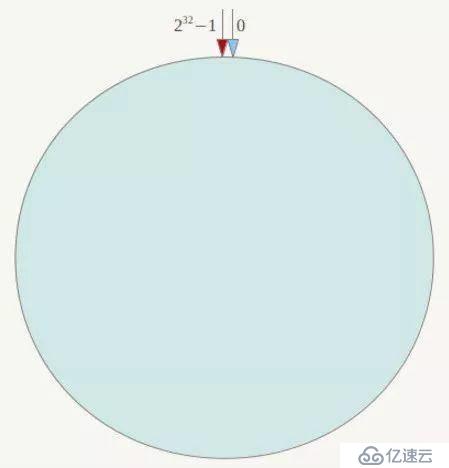
假设有四个节点Node A、B、C、D,经过ip地址的哈希计算,它们的位置如下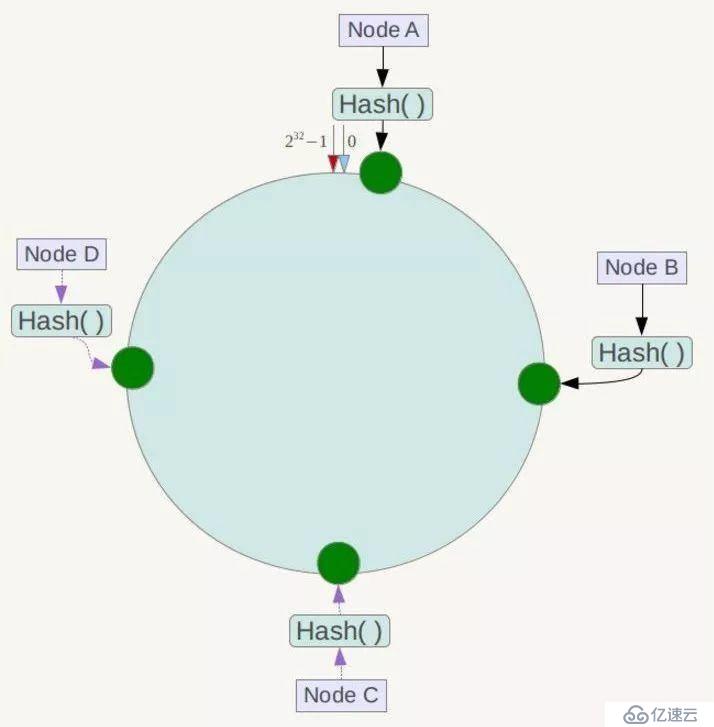
有4个存储对象Object A、B、C、D,经过对Key的哈希计算后,它们的位置如下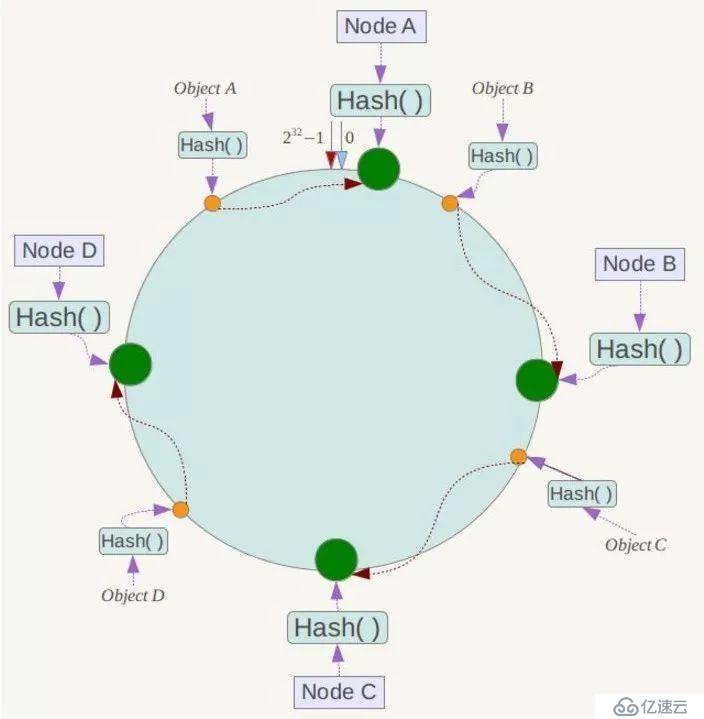
对于各个Object,它所真正的存储位置是按顺时针找到的第一个存储节点。例如Object A顺时针找到的第一个节点是Node A,所以Node A负责存储Object A,Object B存储在Node B。
一致性哈希算法大概如此,那么它的容错性和扩展性如何呢?
假设Node C节点挂掉了,Object C的存储丢失,那么它顺时针找到的最新节点是Node D。也就是说Node C挂掉了,受影响仅仅包括Node B到Node C区间的数据,并且这些数据会转移到Node D进行存储。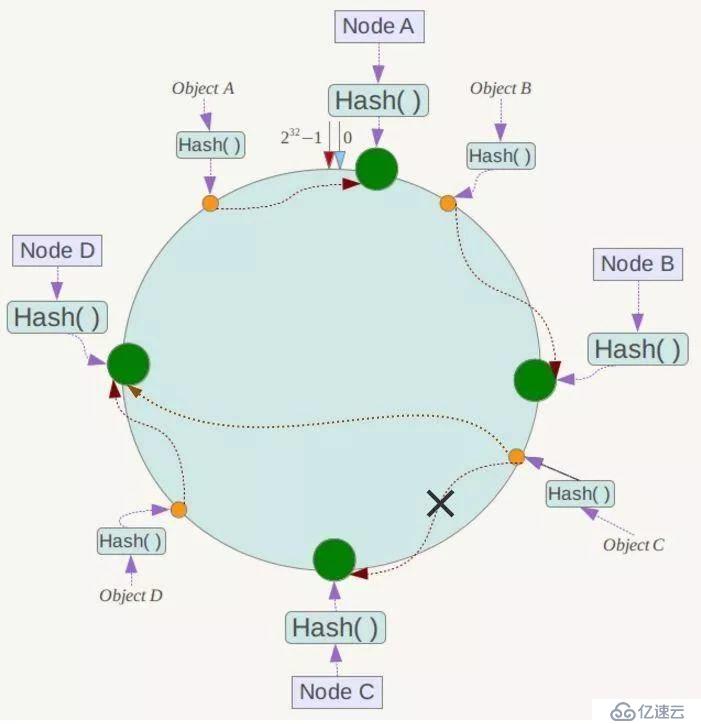
同理,假设现在数据量大了,需要增加一台节点Node X。Node X的位置在Node B到Node C直接,那么受到影响的仅仅是Node B到Node X间的数据,它们要重新落到Node X上。
所以一致性哈希算法对于容错性和扩展性有非常好的支持。但一致性哈希算法也有一个严重的问题,就是数据倾斜。
如果在分片的集群中,节点太少,并且分布不均,一致性哈希算法就会出现部分节点数据太多,部分节点数据太少。也就是说无法控制节点存储数据的分配。如下图,大部分数据都在A上了,B的数据比较少。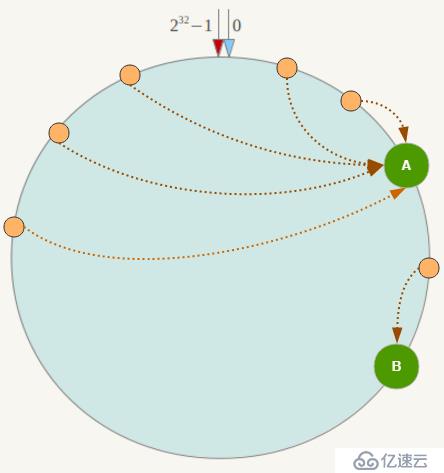
Redis集群(Cluster)并没有选用上面一致性哈希,而是采用了哈希槽(SLOT)的这种概念。主要的原因就是上面所说的,一致性哈希算法对于数据分布、节点位置的控制并不是很友好。
首先哈希槽其实是两个概念,第一个是哈希算法。Redis Cluster的hash算法不是简单的hash(),而是crc16算法,一种校验算法。
另外一个就是槽位的概念,空间分配的规则。其实哈希槽的本质和一致性哈希算法非常相似,不同点就是对于哈希空间的定义。一致性哈希的空间是一个圆环,节点分布是基于圆环的,无法很好的控制数据分布。而Redis Cluster的槽位空间是自定义分配的,类似于Windows盘分区的概念。这种分区是可以自定义大小,自定义位置的。
Redis Cluster包含了16384个哈希槽,每个Key通过计算后都会落在具体一个槽位上,而这个槽位是属于哪个存储节点的,则由用户自己定义分配。例如机器硬盘小的,可以分配少一点槽位,硬盘大的可以分配多一点。如果节点硬盘都差不多则可以平均分配。所以哈希槽这种概念很好地解决了一致性哈希的弊端。
另外在容错性和扩展性上,表象与一致性哈希一样,都是对受影响的数据进行转移。而哈希槽本质上是对槽位的转移,把故障节点负责的槽位转移到其他正常的节点上。扩展节点也是一样,把其他节点上的槽位转移到新的节点上。
但一定要注意的是,对于槽位的转移和分派,Redis集群是不会自动进行的,而是需要人工配置的。所以Redis集群的高可用是依赖于节点的主从复制与主从间的自动故障转移。
下面以最简单的例子,抛开高可用主从复制级转移的内容,来重点介绍下Redis集群是如何搭建,槽位是如何分配的,以加深对Redis集群原理及概念的理解。
先找到redis.conf,启用cluster功能。
cluster-enabled yes默认是关闭的,要启用cluster,让redis成为集群的一部分,需要手动打开才行。
然后配置cluster的配置文件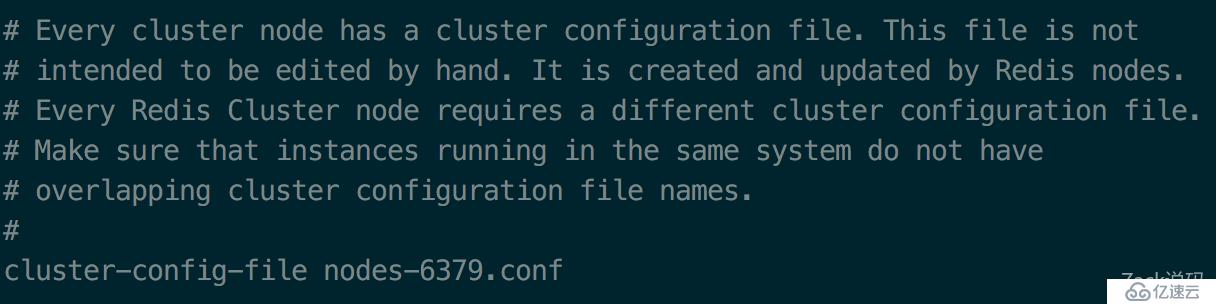
每一个cluster节点都有一个cluster的配置文件,这个文件主要用于记录节点信息,用程序自动生成和管理,不需要人工干预。唯一要注意的是,如果在同一台机器上运行多个节点,需要修改这个配置为不同的名字。
本次为了方便搭建,所有Redis实例都在同一台机器上,所以修改不同的cluster config名字后,复制三份redis.conf配置,以用于启动三个集群实例(cluster至少要三个主节点才能进行)。
> redis-server /usr/local/etc/redis/redis-6379.conf --port 6379 & > redis-server /usr/local/etc/redis/redis-6380.conf --port 6380 & > redis-server /usr/local/etc/redis/redis-6381.conf --port 6381 &
&符号的作用是让命令在后台执行,但程序执行的log依然会打印在console中。也可以通过配置redis.conf中deamonize yes,让Redis在后台运行。
连上6379的Redis实例,然后通过cluster nodes查看集群范围。
连上其他实例也是一样,目前6379、6380、6381在各自的集群中,且集群只有它们自己一个。
在6379上,通过cluster meet命令,与6380、6381建立链接。
127.0.0.1:6379> cluster meet 127.0.0.1 6380 127.0.0.1:6379> cluster meet 127.0.0.1 6381
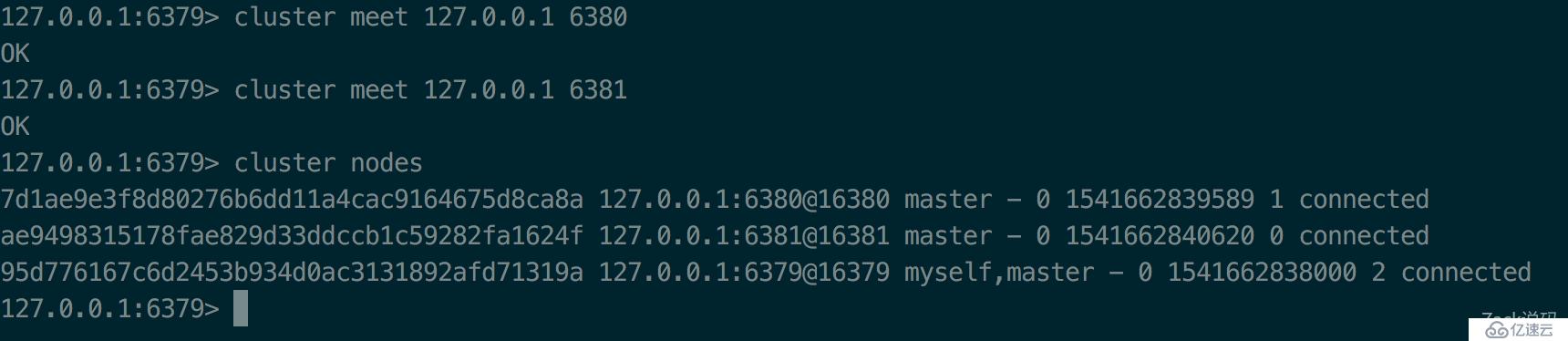
可以看到集群中已经包含了6379、6380、6381三个节点了。登录其他节点查看也是一样的结果。即使6380与6381之间没有直接手动关联,但在集群中,节点一旦发现有未关联的节点,会自动与之握手关联。
通过cluster info命令查看集群的状态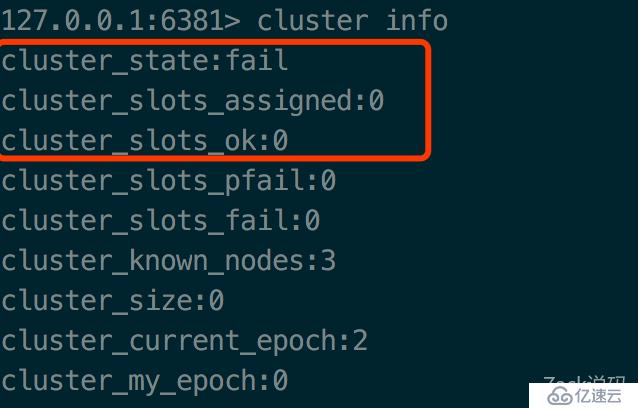
state的状态是fail的,还没启用。看下官方的说明
只有state为ok,节点才能接受请求。如果只要有一个槽位(slot)没有分配,那么这个状态就是fail。而一共需要分配16384槽位才能让集群正常工作。
接下来给6379分配0~5000的槽位,给6380分配5001~10000的槽位,给6381分配10001~16383的槽位。
> redis-cli -c -p 6379 cluster addslots {0..5000}
> redis-cli -c -p 6380 cluster addslots {5001..10000}
> redis-cli -c -p 6381 cluster addslots {10001..16383}再看看cluster info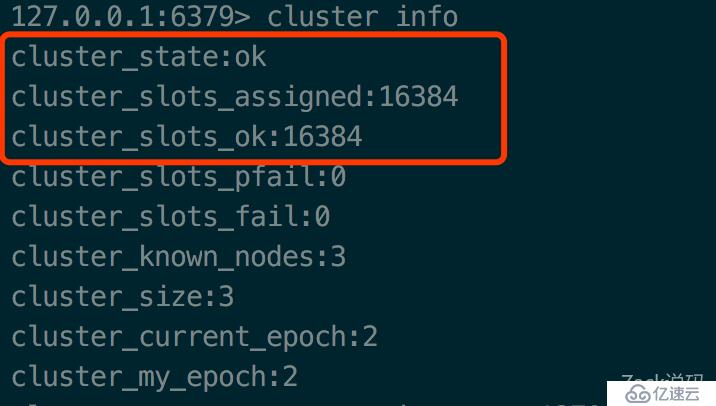
state已经为ok,16384个槽位都已经分配好了。现在集群已经可以正常工作了。
随便登上一个实例,记得加上参数-c,启用集群模式的客户端,否则无法正常运行。
redis-cli -c -p 6380
尝试下set、get操作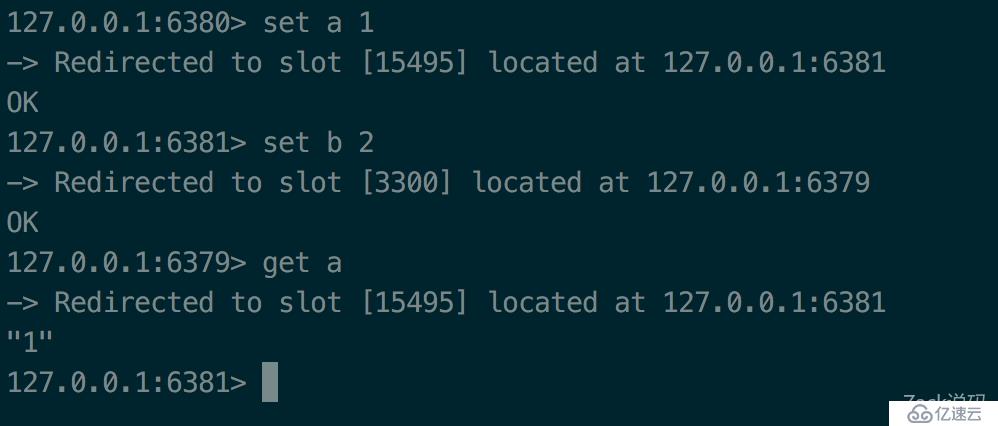
可以看到,Redis集群会计算key落在哪个卡槽,然后会把命令转发到负责该卡槽的节点上执行。
利用cluster keyslot命令计算出key是在哪个槽位上,从而得出会跳转到哪个节点上执行。
“Redis哈希分片原理是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





