翻译自:
https://www.mssqltips.com/sqlservertip/5710/whats-new-in-the-first-public-ctp-of-sql-server-2019/
问题
SQL Server 2019的第一个公共CTP版已经发布,充满了增强和新特性(其中很多也可以在预览形式Azure SQL Database里找到)。我之前有深入了解过,允许我分享一下我的经验。你也可以查看SQL Server团队最新的博文和更新的官方技术文档。
解决方案
我将讨论一些新的引擎特性,分为下五个方面:性能、问题定位、安全、可用性和开发。这次,对于有些特性我有更详细的内容,事实上已经写了完整的博文详述几个。当更多的文档和文章可用时,我将回头更新这些部分。放心,这不是一个详尽的列表,只是直到CTP 2.0版我已了解的内容。还会有更多内容到来。
性能
表变量延迟编译(Table variable deferred compilation)
表变量名声有点不好,大多因为预估。默认,SQL Server预计只有一行会出现在表变量中,当实际有多行时会导致某些有趣的计划选择。避免这种情况的典型变通方案是使用OPTION (RECOMPILE),但这需要修改代码,当行数通常相同时单次重编译很浪费时间。引入了跟踪标志2453来模拟重编译行为,但是需要运行在一个跟踪标志下,只有当发现又很明显行数变化时才会发生。
在兼容级别150,当表变量调用时你可以延迟编译,意思是,直到表变量被填充一次才会构建一个计划。预估将基于表变量的第一次使用,再次之后将没有重编译发生。这是一个在一直重编译以获得实际每次预估,和从不重编译一直预估为1之间的折中。 如果你的行数保持相对稳定就很好,并且这个数远远大于1就更好,但如果这个数大幅波动就没什么用。
在最近发表的博文中,我深入研究了该功能,SQL Server中的表变量延迟编译,Brent Ozar在更快的表变量和新的参数嗅探问题也谈到了它。
行模式内存授予反馈(Row mode memory grant feedback)
SQL Server 2017引入了批模式内存授予反馈,在这里有详细描述。本质上,对于任何与执行计划有关的内存授予牵涉到批模式操作者,SQL Server会预估查询的内存使用,并将它与请求内存相比较。如果请求的内存太低或太高,导致溢出或浪费内存,它会在下次运行的时候调整与执行计划相关的内存授予。这要么会减少授予以允许更高并发量,要么增加授予以提高性能。
现在在兼容级别150下,对于行模式查询我们也获得了该行为。如果一个查询被发现需要访问磁盘,对于后续的执行将会增加内存授予。如果查询的实际内存使用少于内存授予的一半,后续授予请求将会更低。Brent Ozar在这篇文章适当的内存授予中讲得更细。
基于行存储的批模式(Batch mode over rowstore)
自从SQL Server 2012,对带有列存储索引的表查询在批模式的性能增强中收益。性能提升是由于相对一行行执行,查询处理器执行批处理。数据行可以在存储引擎上面以批的形式存储,可以避免并行交换算子。Paul White(Twitter账号@SQL_Kiwi)提醒我如果你使用一个空的列存储表可以执行批模式操作,存储的行由不可见的操作符聚集成批。然而,这个黑 客行为会取消从批模式处理获得的任何提升。在Stack Exchange的回答中有些信息。
在兼容级别150下,SQL Server 2019会在特定的热点案例中自动选择批模式,即使没有出现列存储索引。你会想,为什么不只创建一个列存储索引并使用它?或者使用上面提到的黑 客行为?这种情况扩展到传统的行存储对象,因为列存储索引不总是可能的,由于大量原因,包括缺乏特性支持(例如触发器),大量的更新删除负载下,或者缺乏第三方支持。上面提到的黑 客行为只是一个坏消息。
我创建了一个1千万行的简单表,在整型列上创建了一个单一聚集索引,然后运行如下查询:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*) FROM dbo.FactTable WHERE i1 > 100000 GROUP BY sa5, sa2 ORDER BY sa5, sa2;
这个查询清晰的显示了一个聚集索引查找和并行,但是没有任何列存储索引的迹象(显示在SentryOne执行计划浏览器,一个免费查询调优工具):

如果你深入研究,会发现几乎所有的操作符都以批模式运行,甚至排序和标量计算:
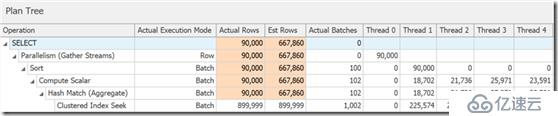
你可以通过保持在一个更低的兼容级别上、通过修改数据库范围配置(在将来的CTP版本会到来),或通过使用DISALLOW_BATCH_MODE查询提示来禁止该功能:
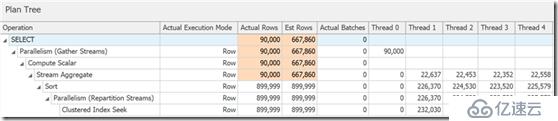
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));在这个案例中以上查询计划有一个额外的交换运算符,所有的运算符以行模式执行,该查询花费了三倍时间去运行:

你可以在这个图上看到,但是在执行计划树的详细信息里,你也可以看到谓词直到排序后才会消除行:
批模式的选择不总是必杀器。而是与行计数的决定,操作符相关的类型和批模式期待收益有关。
APPROX_COUNT_DISTINCT
新的聚合函数为数据仓库场景设计,等价于COUNT(DISTINCT())。替代执行昂贵的排序去重操作以确定实际行数,它依赖于统计信息来获取相对真实的数据。你会发现差距是实际计数的2%,97%的时间,通常用于高级别分析,值用于填充一个报表,或快速预估。
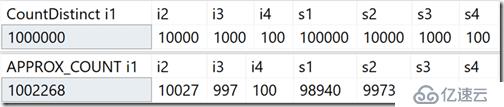
我创建了一个表,有一个值范围在100到1000000之间的唯一值的整型列,和一个值范围在100到100000之间的唯一值的字符串列。除了主要整型列上的聚集索引主键,没有其他索引。针对这些列的COUNT(DISTINCT())和APPROX_COUNT_DISTINCT()的比较结果,你可以看到差异总在2%以内。
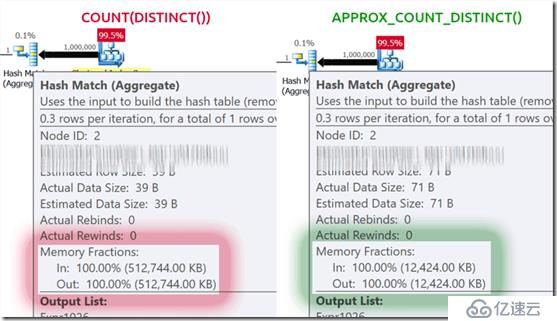
如果你是内存受限的,回报是巨大的,适用于大多数情况。如果你这个案例中查看执行计划,你会看到在哈希匹配操作符上内存占用量的巨大差异:
注意:
如果你已经是内存受限的,你只会看到重要的性能提升。在我的系统上,由于更多CPU被新的函数使用,运行时间稍微更长一些:

如果我有更大的表,更少的可用内存给到SQL Server,更高的并发量,或任何组合,结果很有可能不一样。
查询作用域的兼容级别提示(Query-scoped compatibility level hints)
有一个查询在与当前数据库不同的兼容级别下运行得更好?现在你可以使用新的查询提示支持六个不同的兼容级别和五个不同的基数预估模式。以下显示了在每个案例中使用的可用兼容级别,示例语法和CE模式。你可以看到它如何影响预估,甚至对于系统目录视图:

长话短说:不再需要记录跟踪标志,或怀疑是否仍然需要担心在TF 4199下你的优化修复被覆盖,或被某些服务包或累积更新包所消除。注意,这些额外的提示当前也被添加到SQL Server 2017累积更新10中(查看Pedro Lopes的博文查看更多详细信息)。你也可以看到所有可用提示:
SELECT name FROM sys.dm_exec_valid_use_hints;
但请一直记住提示是最后的依靠。它们让你摆脱困境,但是你不能长期让你的代码像那样,因为随着之后的更新行为会改变。
问题定位
默认开启轻量级跟踪(Lightweight profiling on by default)
这个增强需要一点背景知识。SQL Server 2014引入了DMV sys.dm_exec_query_profiles,允许用户运行查询,同时收集查询执行期间所有操作符的诊断信息。在查询完成后,这个信息可以被用来确定哪个操作符实际做了最多工作并且为什么。没有运行那个特定查询的任何用户,仍然可以对任何会话启用STATISTICS XML或STATISTICS PROFILE,或者对于所有会话通过query_post_execution_showplan扩展事件(通过该事件会对整体性能带来潜在的巨大压力)来获得这个数据的解析。
SSMS 2016添加了功能基于从DMV收集的信息通过执行计划实时显示数据移动,它对于问题定位非常有用。执行计划浏览器也提供了对于查询执行期间可视化数据的实时和重放能力。
从SQL Server 2016 SP1开始,你也可以对于所有会话启用轻量版本的数据收集,通过使用跟踪标志7412或者query_thread_profile扩展事件,以便你可以立即获得任何会话的确切信息而不用在他们的会话中显示启用任何东西(特别是负面影响性能的东西)。与此有关的更多信息在Pedro Lopes的博文中。
在SQL Server 2019,这个进程跟踪默认被启用。所以你不需要运行一个特定扩展事件会话,或者任何跟踪标志,或者在任何独立查询开启STATISTICS选项;你只能对并发会话在任何时候从DMV查看数据。你可以使用一个新的数据库范围配置叫LIGHTWEIGHT_QUERY_PROFILING来关闭它,但该语法不能工作在CTP 2.0(这将会被将来的CTP修复)。
聚集列存储索引统计信息在克隆数据库时可用(Clustered Columnstore Index Statistics Available in Clone Databases)
在当前版本的SQL Server,克隆数据库只会从聚集列存储索引带来原始统计对象,忽略任何在创建后对该表所做的任何更新。如果你对依赖于基数预估的查询调优和其他性能测试使用克隆,这些案例可能无效。Parikshit Savjani在这篇博文描述了限制,并提供了一个工作区:在开始克隆前,生成了一个针对每个对象运行DBCC SHOW_STATISTICS…WITH STATS_STREAM的脚本。这个成本很高,完全容易忘记。
在SQL Server 2019,这些更新的统计信息也只能在克隆时自动可用,因此你可以测试不同的查询场景,并基于真实统计信息获得可靠的计划,不用对所有表运行STATS_STREAM。
对于列存储的压缩预估(Compression estimates for Columnstore)
在当前版本,存储过程sys.sp_estimate_data_compression_savings有如下检查:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))意味着它允许你检查行或页压缩(或去看下移除当前压缩的影响)。在SQL Server 2019,该检查现在像这样:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))这是个好消息,因为它允许你粗略预估添加一个列存储索引到一个表的影响,或者转换一个表或分区到一个更激进的列存储格式,不用存储表到另一个系统并实际尝试它。在我的系统上有一个1千万行的表,提供五个参数运行该存储过程:
EXEC sys.sp_estimate_data_compression_savings @schema_name = N'dbo', @object_name = N'FactTable', @index_id = NULL, @partition_number = NULL, @data_compression = N'NONE'; -- repeat for ROW, PAGE, COLUMNSTORE, COLUMNSTORE_ARCHIVE
结果:

如同其他压缩类型,精确性依赖于行取样,和这些数据在其他数据中的代表性。当然,这是一个猜猜看的很好方式而不用精准数据。
获得页信息的新函数(New function to retrieve page info)
DBCC PAGE和DBCC IND长期用于收集包含分区、索引或表的信息。但它们是未公开的和不支持的命令。关于涉及多个索引或页的问题对于自动化解决方案是相当乏味的。
随着sys.dm_db_database_page_allocations的到来,DMF返回特定对象的所有页的一个集合。仍然是未公开的,该功能展示了在大表上的实际问题--谓词下推:即使获得单页的信息,也得读取整个结构,这可能是颇为忌讳的。
SQL Server 2019引入了另一个DMF sys.dm_db_page_info。它基本返回了一页上的所有信息,没有分配DMF的开销。在当前版本,你得已经知道使用这个函数的页号。这可能是有意的,因为这样是唯一确保性能的方法。因此如果你尝试确定一个索引或表里的所有页,你仍然需要使用分配DMF。之后我会写些关于这个函数的博文。
安全
始终使用安全包加密敏感数据(Always Encrypted using Secure Enclaves)
今天,在传输中始终使用安全包加密敏感数据,和在每个进程端在内存中加密和解密。不幸的是,这通常会引入关键的处理约束,这样不能执行运算和过滤。意味着为了执行一个范围查找,整个数据集得被发送。
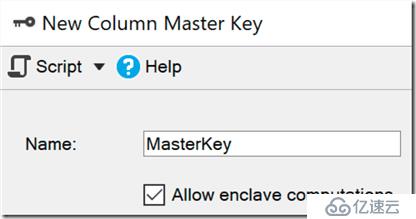
一个安全包是一个保护的内存区域,在哪里运算和过滤被委托(在Windows中,这使用基于虚拟化的安全)。数据在引擎中保持加密,但是在安全包中可以被安全加密或解密。你只需要添加ENCLAVE_COMPUTATIONS选项到主秘钥,你可以再SSMS中勾选“Allow enclave computations”复选框:
与老方法相比(通过向导,或者Set-SqlColumnEncyption命令,或应用程序,需要将数据库的所有数据完全移出、加密、然后发送回数据库),现在你几乎可以立即加密数据:
ALTER TABLE dbo.Patients ALTER COLUMN SSN char(9) -- currently not encrypted! ENCRYPTED WITH ( COLUMN_ENCRYPTION_KEY = ColumnEncryptionKeyName, ENCRYPTION_TYPE = Randomized, ALGORITHM = 'AEAD_AES_256_CBC_HMAC_SHA_256' ) NOT NULL;
这允许通配符和范围查找、排序等,以及查询内的就地加密,无安全损失,因为安全包允许加密和解密在服务器上发生。你也可以执行安全包中的加密秘钥轮询。
我猜该特性将让很多组织修正目标,但在这个CTP版某些优化仍旧是很棒的,而它们默认没启用。但在这篇文章启用丰富的运算你可以了解到如何开启。
在配置管理中的证书管理(Certificate Management in Configuration Manager)
管理SSL和TLS证书一直是一个痛点,很多人不得不执行冗长乏味的工作和自制的脚本,在企业中部署和维护证书。随着SQL Server 2019配置管理器的功能更新,允许你快速查看和验证任何实例的证书,找出即将过期的证书,在AG中跨多个副本(从一个地方:主副本)、或者FCI中的所有节点(从一个地方:活跃节点)同步部署证书。
我还没有尝试所有这些操作,但是它们应该能对旧版的SQL Server起作用,只要从SQL Server 2019版的SQL Server配置管理器来执行。
内置数据分类和审计(Built-In Data Classification and Auditing)
在SSMS 17.5,SQL Server团队在SSMS中添加了分类数据的功能,你可以识别可能包含敏感信息的列,或者可能不遵守各种标准(HIPAA、SOX、PCI和GDPR)。该向导使用一个算法,对于它认为可能导致规范性问题的列给出建议,但你可以自己添加、调整它的建议,并从列表消除任何列。使用扩展属性存储这些分类;基于SSMS的报表使用相同的信息来显示这些被识别的列。报表外,这些属性不可见。
在SQL Server 2019对于该元数据有个新命令,在Azure SQL Database也有,叫做ADD SENSITIVITY CLASSIFICATION。这允许你像SSMS向导一样做同样的事情,但是信息不再存储为扩展属性,任何对数据的访问自动以新的XML列data_sensitivity_information显示在审计中。这包含了在审计事件中访问的所有信息类型。
例如,有如下表:
CREATE TABLE dbo.Contractors ( FirstName sysname, LastName sysname, SSN char(9), HourlyRate decimal(6,2) );
可以看到,这四列要么容易数据泄露,要么不应该对每个访问该表的人可用,至少,我们需要提高可见性。因此可以用不同方式分类这些列:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName WITH (LABEL = 'Confidential – GDPR', INFORMATION_TYPE = 'Personal Info'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
现在,不用看sys.extended_properties,你可以查看sys.sensitivity_classifications的元数据:

如果你对该表审计SELECT或DML,你不必修改审计;创建了分类后一个SELECT *将在审计日志中产生新的data_sensitivity_information列:
<sensitivity_attributes> <sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" /> <sensitivity_attribute label="Highly Confidential" information_type="National ID" /> <sensitivity_attribute label="Highly Confidential" information_type="Financial" /> </sensitivity_attributes>
这明显不能解决所有规范性问题,但是开了个好头。如果你试用向导自动识别列,那么会自动将sp_addextendedproperty调用翻译为ADD SENSITIVITY CLASSIFICATION命令,可以很好的遵从规范性。之后我会写更多关于此的博文。
你也可以基于标签元数据自动或更新权限。对一个用户、组或完全可管理的角色,创建一个禁止访问所有Confidential – GDPR列的动态SQL语句。之后我会展开来讲。
可用性
可恢复在线索引创建(Resumable online index creation)
SQL Server 2017引入了暂停和恢复在线索引重建的功能,对于你想修改使用的CPU数很有用,在一个故障转移事件后继续剩下的操作,或者只是填补维护窗口间的空白。之前的博文我已讲到该特性,关于SQL Server 2017中的可恢复在线索引重建。
在SQL Server 2019,你可以使用相同的语法在线创建索引,你可以暂停和恢复,甚至设置运行时上线(在上线将会暂停运行):
CREATE INDEX foo ON dbo.bar(blat) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
如果运行时间太长,你可以在另一个会话使用ALTER INDEX来暂停(哪怕这个索引还不存在):
ALTER INDEX foo ON dbo.bar PAUSE;
在当前版本当恢复时不能像重建那样减少并行度。如果你尝试减少DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
你会得到:
Msg 10666, Level 16, State 1, Line 3 Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again. The statement has been terminated.
事实上,当你这么做时,至少在当前版本,只会触发一个没有选项的恢复,会得到相同的错误消息。我猜恢复尝试记录在某处并被重用。你需要指定正确或更高的DOP以便继续:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
很明显,当恢复一个暂停的索引创建时你可以增加DOP,你只是不能减少。
另一个额外的好处是,当使用新的数据库范围配置ELEVATE_ONLINE和ELEVATE_RESUMABLE时,默认可以对数据库执行在线和可恢复索引操作。
聚集列存储索引在线创建、重建(Online create / rebuild for Clustered Columnstore Indexes)
除了可恢复的在线索引创建,你也可以在线创建或重建聚集列存储索引(当然这也是可恢复的)。巨大改变是你不再需要维护窗口来执行索引维护,一个更具说服力的案例:将行存储转换为列存储:
CREATE TABLE dbo.splunge ( id int NOT NULL ); GO CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (DROP_EXISTING = ON, ONLINE = ON);
警告:从传统的聚集索引转换为聚集列存储索引,只有在你已存在的聚集索引是以特定的方式创建时才可以在线操作。如果它是显式聚集索引约束或者内联创建索引:
CREATE TABLE dbo.splunge ( id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id) ); GO -- or after the fact -- ALTER TABLE dbo.splunge ADD CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED(id);
将会报错:
Msg 1907, Level 16 Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
为了转换为聚集列存储索引,你得先删除该约束,但是你仍然能执行在线操作:
ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge WITH (ONLINE = ON); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (ONLINE = ON);
在大表上,它可能要比主键创建为唯一聚集索引花的时间更长。我不确定是否为预期行为,或者是当前CTP版本的限制。
辅助副本到主副本连接重定向(Secondary to Primary Replica Connection Redirection)
该特性允许你不用监听器配置重定向,因此即便辅助副本在连接串中显式命名,你可以切换连接到主副本。当你的群集拓扑不支持监听器,或者当你使用无群集AG,或者在多子网场景下有一个复杂的重定向架构,你也可以使用该特性。例如,这将阻止尝试对一个只读副本写操作(失败)的连接。
开发
图增强(Graph enhancements)
图关系现在对node或edge表支持使用MATCH谓词的MERGE语句;现在一条语句可以更新一个存在的edge或插入一个新的edge。一个新edge约束允许控制一个edge可以连接那个node。
UTF-8
SQL Server 2012添加了对UTF-16的支持,通过将排序规则命名为_sc后缀来增补字符,像Latin1_General_100_CI_AI_SC,对于使用Unicode列(nchar/nvarchar)。在SQL Server 2017,可以以UTF-8格式导入和导出数据,通过BCP和BULK INSERT来处理这些列。
在SQL Server 2019,有新的排序规则在SQL Server内本地支持存储为UTF-8数据。因此,你可以适当的使用新的以_SC_UTF8后缀的排序规则创建char或varchar列存储UTF-8数据,像Latin1_General_100_CI_AI_SC_UTF8。这可以帮助提高扩展应用和其他数据库平台和系统的兼容性,不用花费性能去存储nvarchar。
发现的一个小彩蛋
在我的记忆中,SQL Server用户总是抱怨模糊的错误信息:
Msg 8152 String or binary data would be truncated.
在当前的CTP版本中,我发现了之前没有的有趣错误信息:
Msg 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'.
我不认为这里还有什么需要说明的;这是一个伟大的姗姗来迟的改进,将让很多人非常高兴。然而,该功能在CTP 2.0不可用;我只是给你窥探下将来的增强,你可能还没有发现。Brent Ozar在当前CTP版本中列出了所有新的消息,在他的博文中准备了一些有用的评注:sys.messages解密。
总结
SQL Server 2019提供了大量的增强来提升你钟爱的关系数据库平台,还有大量的改变我还没有提及的。持久内存支持,机器学习服务群集,Linux上的复制和分布式事务,Kubernetes,Oracle/Teradata/MongoDB的连接器,同步AG副本最多可到5个支持Java(类似于Python/R的实现),最后一点,新的尝试“Big Data Cluster”。这些新特性你需要填写EAP表单获得。
Bob Ward即将出版的新书,Pro SQL Server on Linux – Including Container-Based Deployment with Docker and Kubernetes,会给你一些新线索。Brent Ozar的博文谈到了对用户自定义标量函数的即将到来的修复。
但即便是在第一个公共CTP版,这些特性都只是针对每个人的,我鼓励你自己做实验,让我知道你觉得怎样。
接下来
阅读更多关于SQL Server 2019的资源:
SQL Server 2019官方文档
SQL Server Blog中更多关于SQL Server 2019的信息
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





