要实现升级不断服,通常需要解决如下问题:
停止服务的时候,可能引起业务中断。在停止服务的过程中,可能服务正在处理请求,新的请求可能持续的发送到该服务。
在微服务架构下,一般都会通过注册中心进行服务发现,客户端会缓存实例地址。停止服务的时候,使用者可能无法及时感知实例下线,并继续使用错误的实例进行访问,导致失败。
新服务启动起来后,会存在灰度状态,出现多个版本并存,如果新服务新增加了接口,新升级的服务需要正确的将流量发送到包含新接口的服务。
成本:实现升级不断服,可以先准备大量的备份机器,将新服务启动起来。然后对用户的请求进行引流,待老服务没有流量后,停止老服务。这需要运维人员准备额外的集群资源并开发强大的运维监控系统来完成。
使用CSE框架,可以以极低的成本,不借助运维工具,就能够轻松的实现升级不断服
在讨论不断服的时候,需要先设计一个测试评估模型。为了简单,采用下面测试场景来进行评估。调用者通过网关来访问应用实例1和应用实例2,现在要对应用实例进行升级。升级的过程中,调用者会启动N个线程,以Mtps的流量来请求。我们可以以整个升级过程出现的失败次数来评估系统对于不断服升级的支持好坏。为了节省资源,我们采用先停止1.0版本的实例1,然后部署2.0版本的实例1;再停止1.0版本的实例2,最后部署2.0版本的实例2。另外,我们还需要构造服务端处理时延T,模拟请求正在处理的情况。
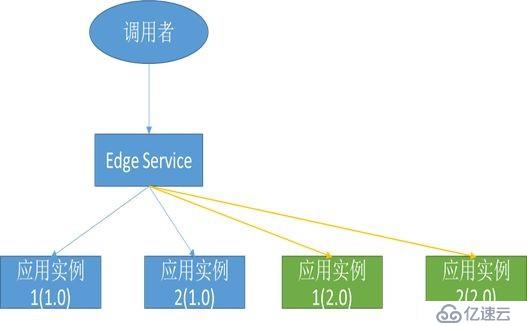
在这个过程中,使用CSE测试的数据如下:
调用者线程数N 调用者流量M 处理时延T 失败次数
10 20tps 无 0
10 80tps 无 0
10 600tps 无 0
10 80tps 100ms 0实现不断服的核心机制包括如下几个:
优雅停机:服务停止的时候,需要等待请求完成,并拒绝新请求;
重试:客户端对于网络连接错误,以及拒绝请求错误,需要选择新服务器进行重试。
隔离:对于失败超过一定次数的服务实例,进行隔离。
在上面的测试数据中,重试策略配置为:
servicecomb:
loadbalance:
retryEnabled: true
retryOnNext: 1
retryOnSame: 0隔离策略配置为:
servicecomb:
loadbalance:
myservice:
isolation:
enabled: true
enableRequestThreshold: 5
singleTestTime: 10000
continuousFailureThreshold: 2测试过程中,在停止1.0版本实例2的时候,需要确保2.0版本实例1已经正确处理请求,否则可能出现无实例可用,出现升级中断。
上面描述了仅仅借助SDK就实现升级不断服。通过配合CSE的灰度发布、部署工具等,可以实现更加可靠的升级不断服和更好的体验。
更多精彩文章,尽在微服务蜂巢公众号,快来关注我们吧~

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





