йЎәеәҸиЎЁе’ҢеҚ•й“ҫиЎЁзҡ„еҜ№жҜ”пјҲеҚҒдәҢпјү
жҲ‘们еңЁд№ӢеүҚеӯҰд№ дәҶзәҝжҖ§иЎЁе’ҢеҚ•й“ҫиЎЁзҡ„зӣёе…ізү№жҖ§пјҢжң¬иҠӮеҚҡе®ўжҲ‘们е°ұжқҘзңӢзңӢе®ғ们зҡ„еҢәеҲ«гҖӮйҰ–е…ҲжҸҗеҮәдёҖдёӘй—®йўҳпјҡеҰӮдҪ•еҲӨж–ӯжҹҗдёӘж•°жҚ®е…ғзҙ жҳҜеҗҰеӯҳеңЁдәҺзәҝжҖ§иЎЁдёӯпјҹйӮЈиӮҜе®ҡжҳҜзӣҙжҺҘйҒҚеҺҶдёҖйҒҚдәҶпјҢжҲ‘们жқҘзңӢзңӢд»Јз Ғ
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
int main()
{
LinkList<int> list;
for(int i=0; i<5; i++)
{
list.insert(0, i);
}
for(int i=0; i<list.length(); i++)
{
if( list.get(i) == 3 )
{
cout << list.get(i) << endl;
}
}
return 0;
} жҲ‘们еҲӨж–ӯ 3 жҳҜйғҪеӯҳеңЁдәҺеҪ“еүҚзәҝжҖ§иЎЁдёӯпјҢеҰӮжһңеӯҳеңЁпјҢдҫҝиҫ“еҮәгҖӮзңӢзңӢиҫ“еҮәз»“жһң

жҲ‘们зңӢеҲ°еңЁжҹҘжүҫзҡ„ж—¶еҖҷиҝҳеҫ—еҺ»жүӢеҠЁйҒҚеҺҶдёҖйҒҚпјҢж„ҹи§үеҫҲйә»зғҰгҖӮйӮЈд№ҲжҲ‘们еңЁд№ӢеүҚзҡ„е®һзҺ°дёӯпјҢе°‘дәҶдёҖдёӘж“ҚдҪңпјҢйӮЈдҫҝжҳҜжҹҘжүҫж“ҚдҪң findгҖӮе®ғеҸҜд»ҘдёәзәҝжҖ§иЎЁпјҲListпјүеўһеҠ дёҖдёӘжҹҘжүҫж“ҚдҪңпјҢеҺҹеһӢдёә int find(const T& e) const; еҸӮж•°дёәеёҰжҹҘжүҫзҡ„ж•°жҚ®е…ғзҙ пјӣиҝ”еӣһеҖјпјҡ>=0 ж—¶пјҢеҲҷиЎЁзӨәж•°жҚ®е…ғзҙ еңЁзәҝжҖ§иЎЁдёӯ第дёҖж¬ЎеҮәзҺ°зҡ„дҪҚзҪ®пјӣдёә -1 ж—¶пјҢеҲҷиЎЁзӨәж•°жҚ®е…ғзҙ дёҚеӯҳеңЁгҖӮдёӢйқўжҲ‘们зңӢзңӢж•°жҚ®е…ғзҙ жҹҘжүҫзҡ„зӨәдҫӢд»Јз ҒпјҢеҰӮдёӢ
LinkList<int> list;
for(int i=0; i<5; i++)
{
list.insert(0, i);
}
cout << list.find(3) << endl; // ==> 1 дёӢжқҘжҲ‘们еңЁ List.h жәҗз Ғдёӯж·»еҠ find ж“ҚдҪңпјҢеҰӮдёӢ
List.h жәҗз Ғ
#ifndef LIST_H
#define LIST_H
#include "Object.h"
namespace DTLib
{
template < typename T >
class List : public Object
{
protected:
List(const List&);
List& operator= (const List&);
public:
List() {}
virtual bool insert(const T& e) = 0;
virtual bool insert(int i, const T& e) = 0;
virtual bool remove(int i) = 0;
virtual bool set(int i, const T& e) = 0;
virtual bool get(int i, T& e) const = 0;
virtual int find(const T& e) const = 0;
virtual int length() const = 0;
virtual void clear() = 0;
};
SeqList.h жәҗз Ғ
#ifndef SEQLIST_H
#define SEQLIST_H
#include "List.h"
#include "Exception.h"
namespace DTLib
{
template < typename T >
class SeqList : public List<T>
{
protected:
T* m_array;
int m_length;
public:
bool insert(int i, const T& e)
{
bool ret = ((0 <= i) && (i <= m_length));
ret = ret && (m_length < capacity());
if( ret )
{
for(int p=m_length-1; p>=i; p--)
{
m_array[p+1] = m_array[p];
}
m_array[i] = e;
m_length++;
}
return ret;
}
bool insert(const T& e)
{
return insert(m_length, e);
}
bool remove(int i)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
for(int p=i; p<m_length-1; p++)
{
m_array[p] = m_array[p+1];
}
m_length--;
}
return ret;
}
bool set(int i, const T& e)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
m_array[i] = e;
}
return ret;
}
bool get(int i, T& e) const
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
e = m_array[i];
}
return ret;
}
int find(const T& e) const // O(n)
{
bool ret = -1;
for(int i=0; i<m_length; i++)
{
if( m_array[i] == e )
{
ret = i;
break;
}
}
return ret;
}
int length() const
{
return m_length;
}
void clear()
{
m_length = 0;
}
T& operator[] (int i)
{
if( (0 <= i) && (i < m_length) )
{
return m_array[i];
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Parameter i is invalid ...");
}
}
T operator[] (int i) const
{
return (const_cast<SeqList<T>&>(*this))[i];
}
virtual int capacity() const = 0;
};
}
#endif // SEQLIST_H
LinkList.h жәҗз Ғ
#ifndef LINKLIST_H
#define LINKLIST_H
#include "List.h"
#include "Exception.h"
namespace DTLib
{
template < typename T >
class LinkList : public List<T>
{
protected:
struct Node : public Object
{
T value;
Node* next;
};
mutable struct : public Object
{
char reserved[sizeof(T)];
Node* next;
} m_header;
int m_length;
Node* position(int i) const
{
Node* ret = reinterpret_cast<Node*>(&m_header);
for(int p=0; p<i; p++)
{
ret = ret->next;
}
return ret;
}
public:
LinkList()
{
m_header.next = NULL;
m_length = 0;
}
bool insert(const T& e)
{
return insert(m_length, e);
}
bool insert(int i, const T& e)
{
bool ret = ((0 <= i) && (i <= m_length));
if( ret )
{
Node* node = new Node();
if( node != NULL )
{
Node* current = position(i);
node->value = e;
node->next = current->next;
current->next = node;
m_length++;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No memory to insert new element ...");
}
}
}
bool remove(int i)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
Node* current = position(i);
Node* toDel = current->next;
current->next = toDel->next;
delete toDel;
m_length--;
}
return ret;
}
bool set(int i, const T& e)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
position(i)->next->value = e;
}
return ret;
}
T get(int i) const
{
T ret;
if( get(i, ret) )
{
return ret;
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Invaild parameter i to get element ...");
}
}
bool get(int i, T& e) const
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
e = position(i)->next->value;
}
return ret;
}
int find(const T& e) const
{
int ret = -1;
int i = 0;
Node* node = m_header.next;
while( node )
{
if( node->value == e )
{
ret = i;
break;
}
else
{
node = node->next;
i++;
}
}
return ret;
}
int length() const
{
return m_length;
}
void clear()
{
while( m_header.next )
{
Node* toDel = m_header.next;
m_header.next = toDel->next;
delete toDel;
}
m_length = 0;
}
~LinkList()
{
clear();
}
};
}
#endif // LINKLIST_H йӮЈд№ҲжӯӨж—¶зҡ„ main.cpp е°ұеҸҜд»ҘеҶҷжҲҗиҝҷж ·зҡ„дәҶ
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
int main()
{
LinkList<int> list;
for(int i=0; i<5; i++)
{
list.insert(0, i);
}
cout << list.find(3) << endl;
return 0;
} жҲ‘们жқҘзңӢзңӢз»“жһң

жҲ‘们жқҘжҹҘжүҫдёӢ -3 е‘ў

жҲ‘们зңӢеҲ°еҰӮжһңжҹҘжүҫзҡ„е…ғзҙ еңЁйҮҢйқўпјҢеҲҷиҝ”еӣһ 1пјӣеҰӮжһңжІЎжңүпјҢеҲҷиҝ”еӣһ -1гҖӮйӮЈд№ҲжҲ‘们еҰӮжһңжҹҘжүҫзҡ„жҳҜзұ»е‘ўпјҹйӮЈзЁӢеәҸиҝҳдјҡзј–иҜ‘йҖҡиҝҮеҗ—пјҹжҲ‘们жқҘзңӢзңӢпјҢmain.cpp жәҗз ҒеҰӮдёӢ
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
class Test
{
int i;
public:
Test(int v = 0)
{
i = v;
}
};
int main()
{
Test t1(1);
Test t2(3);
Test t3(3);
LinkList<Test> list;
return 0;
} зј–иҜ‘з»“жһңеҰӮдёӢ
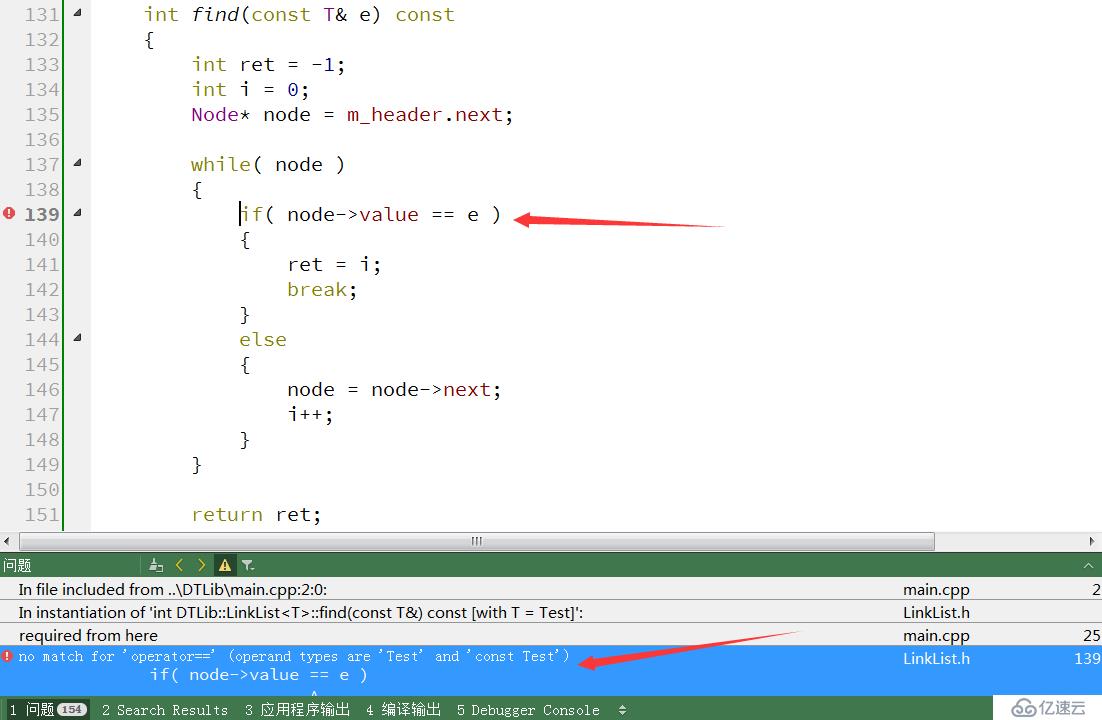
зј–иҜ‘жҠҘй”ҷдәҶпјҢжҲ‘们并没жңүж”№еҠЁ LinkList дёӯзҡ„д»Јз ҒпјҢдёәд»Җд№Ҳиҝҷеқ—дјҡжҠҘй”ҷе‘ўпјҹйӮЈд№ҲжӯӨж—¶жҲ‘们жғіиҰҒи®©дёӨдёӘзұ»еҜ№иұЎиҝӣиЎҢзӣёзӯүзҡ„жҜ”иҫғпјҢеҸҜжҳҜжҲ‘们并没жңүе®ҡд№ү == ж“ҚдҪңз¬ҰпјҢжӯӨж—¶иӮҜе®ҡдјҡеҮәй”ҷгҖӮйӮЈд№ҲжҲ‘们еңЁзұ» Test дёӯиҝӣиЎҢ == ж“ҚдҪңз¬Ұзҡ„е®ҡд№үпјҢеҰӮдёӢ
class Test
{
int i;
public:
Test(int v = 0)
{
i = v;
}
bool operator == (const Test& obj)
{
return true;
}
}; жҲ‘们еҶҚжқҘзј–иҜ‘дёӢпјҢзңӢзңӢз»“жһң
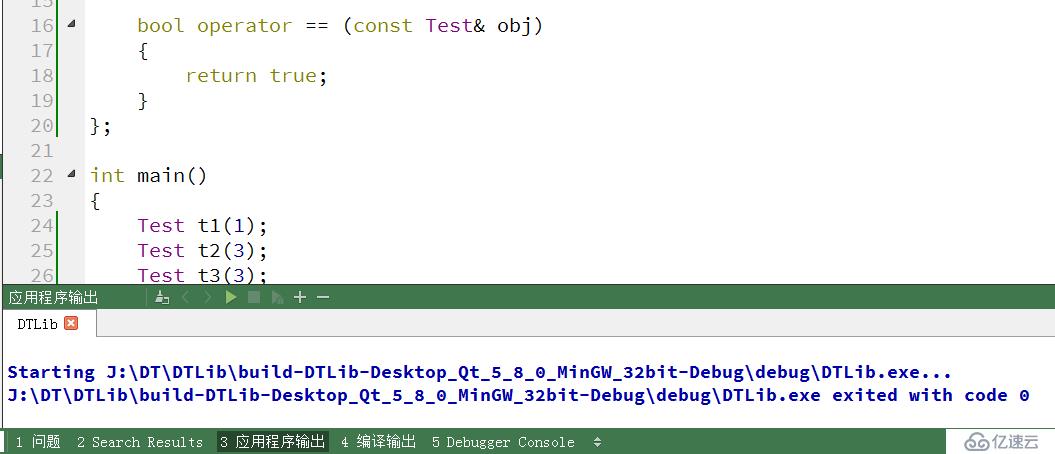
зј–иҜ‘жҳҜйҖҡиҝҮзҡ„пјҢйӮЈд№ҲжҲ‘们жӯӨж—¶дҫҝи§үеҫ—еҘҮжҖӘдәҶгҖӮжҲ‘们дёәд»Җд№ҲиҰҒеңЁ Test зұ»дёӯе®ҡд№ү == ж“ҚдҪңз¬Ұе‘ўпјҢжӯӨж—¶жңҖеҘҪзҡ„и§ЈеҶіеҠһжі•жҳҜеңЁйЎ¶еұӮзҲ¶зұ» Object дёӯж·»еҠ == е’Ң пјҒ= ж“ҚдҪңз¬ҰпјҢ然еҗҺе°Ҷ Test зұ»з»§жүҝиҮӘ Object зұ»е°ұеҸҜд»ҘдәҶгҖӮ
Object.h жәҗз Ғ
#ifndef OBJECT_H
#define OBJECT_H
namespace DTLib
{
class Object
{
public:
void* operator new (unsigned int size) throw();
void operator delete (void* p);
void* operator new[] (unsigned int size) throw();
void operator delete[] (void* p);
bool operator == (const Object& obj);
bool operator != (const Object& obj);
virtual ~Object() = 0;
};
}
#endif // OBJECT_H
Object.cpp жәҗз Ғ
#include "Object.h"
#include <cstdlib>
namespace DTLib
{
void* Object::operator new (unsigned int size) throw()
{
return malloc(size);
}
void Object::operator delete (void* p)
{
free(p);
}
void* Object::operator new[] (unsigned int size) throw()
{
return malloc(sizeof(size));
}
void Object::operator delete[] (void* p)
{
free(p);
}
bool Object::operator == (const Object& obj)
{
return (this == &obj);
}
bool Object::operator != (const Object& obj)
{
return (this != &obj);
}
Object::~Object()
{
}
} жӯӨж—¶зҡ„ main.cpp д»Јз ҒеҰӮдёӢ
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
class Test : public Object
{
int i;
public:
Test(int v = 0)
{
i = v;
}
bool operator == (const Test& obj)
{
return (i == obj.i);
}
};
int main()
{
Test t1(1);
Test t2(3);
Test t3(3);
LinkList<Test> list;
list.insert(t1);
list.insert(t2);
list.insert(t3);
cout << list.find(t2) << endl;
return 0;
} жҲ‘们жқҘзңӢзңӢзј–иҜ‘иҫ“еҮәз»“жһң

йӮЈд№ҲжҲ‘们еңЁ main.cpp жөӢиҜ•д»Јз Ғдёӯе°Ҷ t1, t2, t3 еҜ№иұЎжҸ’е…ҘеҲ° list дёӯпјҢ然еҗҺжҹҘжүҫ t2 жҳҜеҗҰеӯҳеңЁпјҢйӮЈд№Ҳе®ғиӮҜе®ҡжҳҜеӯҳеңЁзҡ„пјҢеӣ жӯӨдјҡиҫ“еҮә 1гҖӮйӮЈд№ҲжҲ‘们жқҘеҲҶжһҗдёӢйЎәеәҸиЎЁе’ҢеҚ•й“ҫиЎЁзҡ„ж—¶й—ҙеӨҚжқӮеәҰзҡ„еҜ№жҜ”пјҢеҰӮдёӢ

жҲ‘们зңӢеҲ°йЎәеәҸиЎЁеҸӘжңүдёүдёӘ O(n) пјҢиҖҢеҚ•й“ҫиЎЁеҮ д№ҺжҳҜе…ЁйғЁжҳҜ O(n)гҖӮд»Һж—¶й—ҙеӨҚжқӮеәҰдёҠжқҘзңӢпјҢдјјд№ҺйЎәеәҸиЎЁжӣҙеҚ дјҳеҠҝпјҢйӮЈд№ҲжҲ‘们еңЁе№іж—¶зҡ„ејҖеҸ‘дёӯпјҢдёәд»Җд№Ҳз»Ҹеёёи§ҒеҲ°зҡ„жҳҜеҚ•й“ҫиЎЁиҖҢдёҚжҳҜйЎәеәҸиЎЁе‘ўпјҹеңЁе®һйҷ…зҡ„е·ҘзЁӢејҖеҸ‘дёӯпјҢж—¶й—ҙеӨҚжқӮеәҰеҸӘжҳҜдёҖдёӘеҸӮиҖғжҢҮж ҮпјҢеҜ№дәҺеҶ…зҪ®еҹәзЎҖзұ»еһӢпјҢйЎәеәҸиЎЁе’ҢеҚ•й“ҫиЎЁзҡ„ж•ҲзҺҮдёҚзӣёдёҠдёӢпјҢиҖҢеҜ№дәҺиҮӘе®ҡд№үзұ»еһӢжқҘиҜҙпјҢйЎәеәҸиЎЁеңЁж•ҲзҺҮдёҠдҪҺдәҺеҚ•й“ҫиЎЁгҖӮеңЁжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңдёӯпјҢйЎәеәҸиЎЁж¶үеҸҠеӨ§йҮҸж•°жҚ®еҜ№иұЎзҡ„еӨҚеҲ¶ж“ҚдҪңпјҢиҖҢеҚ•й“ҫиЎЁеҸӘж¶үеҸҠжҢҮй’Ҳж“ҚдҪңпјҢж•ҲзҺҮдёҺж•°жҚ®еҜ№иұЎж— е…ігҖӮеҜ№дәҺж•°жҚ®и®ҝй—®пјҢйЎәеәҸиЎЁжҳҜйҡҸжңәи®ҝй—®пјҢеҸҜзӣҙжҺҘе®ҡдҪҚж•°жҚ®еҜ№иұЎпјӣиҖҢеҜ№дәҺеҚ•й“ҫиЎЁжқҘиҜҙжҳҜйЎәеәҸи®ҝй—®пјҢеҝ…йЎ»д»ҺеӨҙи®ҝй—®ж•°жҚ®еҜ№иұЎпјҢж— жі•зӣҙжҺҘе®ҡдҪҚгҖӮ
дёҖиҲ¬еңЁе·ҘзЁӢејҖеҸ‘дёӯпјҢйЎәеәҸиЎЁдё»иҰҒз”ЁдәҺпјҡж•°жҚ®е…ғзҙ зұ»еһӢзӣёеҜ№з®ҖеҚ•пјҢдёҚж¶үеҸҠж·ұжӢ·иҙқпјӣж•°жҚ®е…ғзҙ зӣёеҜ№зЁіе®ҡпјҢи®ҝй—®ж“ҚдҪңиҝңеӨҡдәҺжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңгҖӮеҚ•й“ҫиЎЁдё»иҰҒз”ЁдәҺпјҡж•°жҚ®е…ғзҙ зҡ„зұ»еһӢзӣёеҜ№еӨҚжқӮпјҢеӨҚеҲ¶ж“ҚдҪңзӣёеҜ№иҖ—ж—¶пјӣж•°жҚ®е…ғзҙ дёҚзЁіе®ҡпјҢйңҖиҰҒз»ҸеёёжҸ’е…Ҙе’ҢеҲ йҷӨпјҢи®ҝй—®ж“ҚдҪңиҫғе°‘зҡ„жғ…еҶөгҖӮйҖҡиҝҮд»ҠеӨ©зҡ„еӯҰд№ пјҢжҖ»з»“еҰӮдёӢпјҡ1гҖҒзәҝжҖ§иЎЁдёӯе…ғзҙ зҡ„жҹҘжүҫдҫқиө–дәҺзӣёзӯүжҜ”иҫғж“ҚдҪңз¬ҰпјҲ==пјүпјӣ2гҖҒйЎәеәҸиЎЁйҖӮз”ЁдәҺи®ҝй—®йңҖжұӮйҮҸиҫғеӨ§зҡ„еңәеҗҲпјҲйҡҸжңәи®ҝй—®пјүпјӣ3гҖҒеҚ•й“ҫиЎЁйҖӮз”ЁдәҺж•°жҚ®е…ғзҙ йў‘з№ҒжҸ’е…ҘеҲ йҷӨзҡ„еңәеҗҲпјҲйЎәеәҸи®ҝй—®пјүпјӣ4гҖҒеҪ“ж•°жҚ®зұ»еһӢзӣёеҜ№з®ҖеҚ•ж—¶пјҢйЎәеәҸиЎЁе’ҢеҚ•й“ҫиЎЁзҡ„ж•ҲзҺҮдёҚзӣёдёҠдёӢгҖӮ





