Analyzing plans
分析计划
要真正了解查询计划并真正能够发现、修复或解决查询计划的问题, 需要对组成这些计划的查询操作有一个扎实的理解。总的来说, 有太多的操作员可以在一章中讨论它们。此外, 可以以无数的方式将这些运算符合并到查询计划中。因此, 本节侧重于了解最常见的查询运算符-查询执行的最基本的构造块, 并对 SQL server 如何使用它们构建各种有趣的查询计划提供一些了解。具体地说, 本节查看扫描并查找、联接、聚合、联合、选择子查询计划和并行性。在了解这些基本操作和计划如何工作之后, 可以让你尽可能地分解并理解更大、更复杂的查询计划。
Scans and Seeks
扫描和查找
扫描和查找是 SQL server 用来从表和索引中读取数据的迭代器。这些迭代器是 SQL server 支持的最基本的。它们几乎出现在每个查询计划中。了解扫描和查找之间的不同之处很重要: 扫描处理整个表或一个索引的整个叶级别, 而查找有效地根据谓词从索引的一个或多个范围返回行。
首先看一下扫描的例子。请考虑以下查询:
SELECT [OrderId] FROM [Orders] WHERE [RequiredDate] = '1998-03-26'
RequiredDate 列没有索引。因此, SQL server 必须读取 Orders 表的每一行。计算每行的 RequiredDate 的谓词;如果谓词为 true (即, 如果行符合资格), 则返回该行。
为了最大化性能, SQL server 尽可能在扫描迭代器中计算谓词。但是, 如果谓词太复杂或太贵(损耗性能), 则 SQL server 可能会在单独的筛选器迭代程序中对其进行评估。谓词以 WHERE 关键字或 XML 计划中的标记出现在文本计划中<Predicate></Predicate>。
以下是前面查询的文本计划:
|--Clustered Index Scan(OBJECT:([Orders].[PK_Orders]),
WHERE:([Orders].[RequiredDate]='1998-03-26'))
图10-6 以扫描为例。
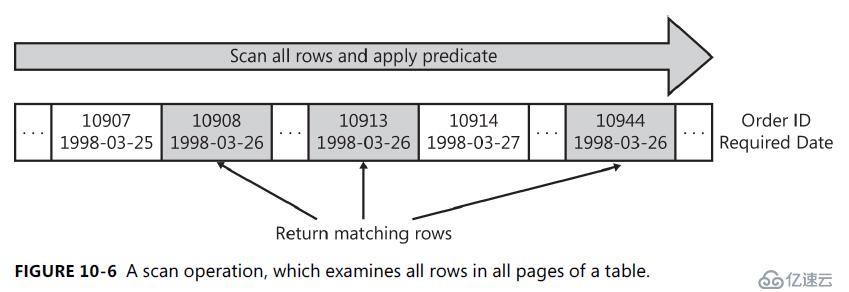
由于扫描会触及表中的每一行是否符合条件, 因此成本与表中的总行数成正比。因此, 如果表较小或许多行符合谓词的条件, 则扫描是一种有效的策略。但是, 如果表很大, 并且大多数行不符合条件, 则扫描会触及更多的页面和行, 并执行更多不必要的 i/o
现在来看一个索引查找的示例。假设我们有一个类似的查询, 但这次谓词在 OrderDate 列上有一个索引:
SELECT [OrderId] FROM [Orders] WHERE [OrderDate] = '1998-02-26'
这一次, SQL server 可以使用索引直接定位到符合谓词的行。在这种情况下, 谓词称为查找谓词。在大多数情况下, SQL server 不需要显式地评估查找谓词,索引可确保查找操作只返回符合条件的行。
查找谓词以SEEK关键字或 XML 计划中的标记出现在文本计划中<SeekPredicates></SeekPredicates>。
以下是本示例的文本计划:
|--Index Seek(OBJECT:([Orders].[OrderDate]),
SEEK:([Orders].[OrderDate]=CONVERT_IMPLICIT(datetime,[@1],0)) ORDERED FORWARD)
SQL server 通过自动参数化查询方法将参数 @1 替换为日期格式。
图10-7 索引查找举例。
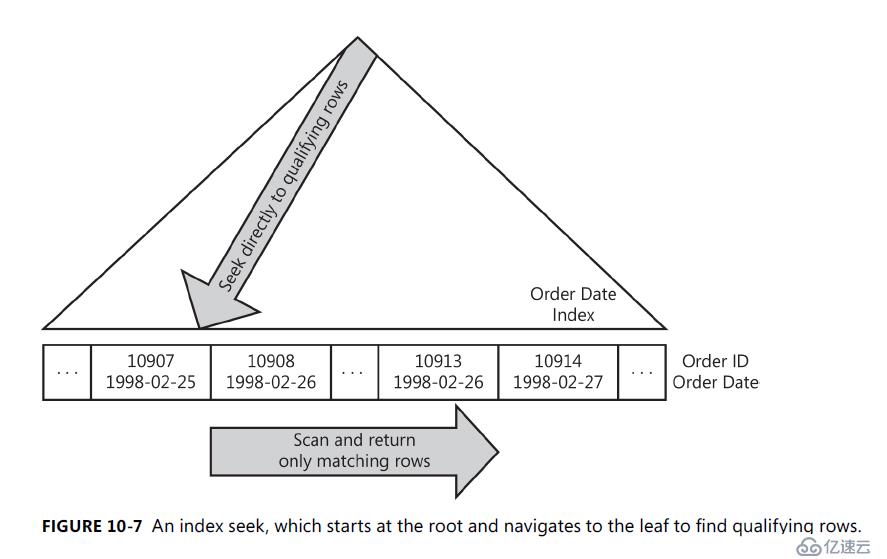
由于查找仅触及符合资格的行和包含这些限定行的页, 因此成本与限定行和页的数量成正比, 而不是与表中的总行数成比例。因此, 在使用高度选择性的查找谓词时, 查找通常是一种更有效的策略, 即, 如果查找谓词排除表的很大一部分。
SQL server 区分扫描和查找以及堆上的扫描 (没有聚集索引的表)、对聚集索引的扫描以及对非聚集索引的扫描。
表10-2 所有有效组合在计划输出中的显示。

亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



