Redisзҡ„жҢҒд№…еҢ–е’Ңдё»д»ҺеӨҚеҲ¶жңәеҲ¶жҳҜд»Җд№Ҳ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢRedisзҡ„жҢҒд№…еҢ–е’Ңдё»д»ҺеӨҚеҲ¶жңәеҲ¶жҳҜд»Җд№ҲпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жүҖ收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»жҺўи®Ёеҗ§пјҒ
RedisжҢҒд№…еҢ–
Redis жҸҗдҫӣдәҶеӨҡз§ҚдёҚеҗҢзә§еҲ«зҡ„жҢҒд№…еҢ–ж–№ејҸпјҡ
RDB жҢҒд№…еҢ–еҸҜд»ҘеңЁжҢҮе®ҡзҡ„ж—¶й—ҙй—ҙйҡ”еҶ…з”ҹжҲҗж•°жҚ®йӣҶзҡ„ж—¶й—ҙзӮ№еҝ«з…§пјҲpoint-in-time snapshotпјү
AOF жҢҒд№…еҢ–и®°еҪ•жңҚеҠЎеҷЁжү§иЎҢзҡ„жүҖжңүеҶҷж“ҚдҪңе‘Ҫд»ӨпјҢ并еңЁжңҚеҠЎеҷЁеҗҜеҠЁж—¶пјҢйҖҡиҝҮйҮҚж–°жү§иЎҢиҝҷдәӣе‘Ҫд»ӨжқҘиҝҳеҺҹж•°жҚ®йӣҶгҖӮ AOF ж–Ү件дёӯзҡ„е‘Ҫд»Өе…ЁйғЁд»Ҙ Redis еҚҸи®®зҡ„ж јејҸжқҘдҝқеӯҳпјҢж–°е‘Ҫд»Өдјҡиў«иҝҪеҠ еҲ°ж–Ү件зҡ„жң«е°ҫгҖӮ Redis иҝҳеҸҜд»ҘеңЁеҗҺеҸ°еҜ№ AOF ж–Ү件иҝӣиЎҢйҮҚеҶҷпјҲrewriteпјүпјҢдҪҝеҫ— AOF ж–Ү件зҡ„дҪ“з§ҜдёҚдјҡи¶…еҮәдҝқеӯҳж•°жҚ®йӣҶзҠ¶жҖҒжүҖйңҖзҡ„е®һйҷ…еӨ§е°ҸгҖӮ
Redis иҝҳеҸҜд»ҘеҗҢж—¶дҪҝз”Ё AOF жҢҒд№…еҢ–е’Ң RDB жҢҒд№…еҢ–гҖӮ еңЁиҝҷз§Қжғ…еҶөдёӢпјҢ еҪ“ Redis йҮҚеҗҜж—¶пјҢ е®ғдјҡдјҳе…ҲдҪҝз”Ё AOF ж–Ү件жқҘиҝҳеҺҹж•°жҚ®йӣҶпјҢ еӣ дёә AOF ж–Ү件дҝқеӯҳзҡ„ж•°жҚ®йӣҶйҖҡеёёжҜ” RDB ж–Ү件жүҖдҝқеӯҳзҡ„ж•°жҚ®йӣҶжӣҙе®Ңж•ҙгҖӮ
дҪ з”ҡиҮіеҸҜд»Ҙе…ій—ӯжҢҒд№…еҢ–еҠҹиғҪпјҢи®©ж•°жҚ®еҸӘеңЁжңҚеҠЎеҷЁиҝҗиЎҢж—¶еӯҳеңЁгҖӮ
RDB(Redis DataBase)
Rdb:еңЁжҢҮе®ҡзҡ„ж—¶й—ҙй—ҙйҡ”еҶ…е°ҶеҶ…еӯҳдёӯзҡ„ж•°жҚ®йӣҶеҝ«з…§еҶҷе…ҘзЈҒзӣҳпјҢд№ҹе°ұжҳҜиЎҢиҜқи®Ізҡ„ snapshot еҝ«з…§пјҢе®ғжҒўеӨҚж—¶е°ұжҳҜе°Ҷеҝ«з…§ж–Ү件зӣҙжҺҘиҜ»еҲ°еҶ…еӯҳйҮҢгҖӮ
Redis дјҡеҚ•зӢ¬зҡ„еҲӣе»ә(fork) дёҖдёӘеӯҗиҝӣзЁӢжқҘиҝӣиЎҢжҢҒд№…еҢ–пјҢдјҡе…Ҳе°Ҷж•°жҚ®еҶҷе…ҘеҲ°дёҖдёӘдёҙж—¶ж–Ү件дёӯпјҢеҫ…жҢҒд№…еҢ–иҝҮзЁӢз»“жқҹдәҶпјҢеҶҚз”ЁиҝҷдёӘдёҙж—¶ж–Ү件жӣҝжҚўдёҠж¬ЎжҢҒд№…еҢ–иҝҳзҡ„ж–Ү件гҖӮж•ҙдёӘиҝҮзЁӢжҖ»пјҢдё»иҝӣзЁӢжҳҜдёҚиҝӣиЎҢд»»дҪ• IO ж“ҚдҪңпјҢиҝҷе°ұзЎ®дҝқдәҶжһҒй«ҳзҡ„жҖ§иғҪпјҢеҰӮжһңйңҖиҰҒиҝӣиЎҢеӨ§и§„жЁЎзҡ„ж•°жҚ®жҒўеӨҚпјҢдё”еҜ№дәҺж•°жҚ®жҒўеӨҚзҡ„е®Ңж•ҙжҖ§дёҚжҳҜйқһеёёж•Ҹж„ҹпјҢйӮЈ RDB ж–№жі•иҰҒжҜ” AOF ж–№ејҸжӣҙеҠ зҡ„й«ҳж•ҲгҖӮRDB зҡ„зјәзӮ№жҳҜжңҖеҗҺдёҖж¬ЎжҢҒд№…еҢ–еҗҺзҡ„ж•°жҚ®еҸҜиғҪдёўеӨұгҖӮ
Fork зҡ„дҪңз”ЁжҳҜеӨҚеҲ¶дёҖдёӘдёҺеҪ“еүҚиҝӣзЁӢдёҖж ·зҡ„иҝӣзЁӢпјҢж–°иҝӣзЁӢзҡ„жүҖжңүж•°жҚ®(еҸҳйҮҸгҖҒзҺҜеўғеҸҳйҮҸгҖҒзЁӢеәҸи®Ўж•°еҷЁзӯү)ж•°еҖјйғҪе’ҢеҺҹиҝӣзЁӢдёҖиҮҙпјҢдҪҶжҳҜжҳҜдёҖдёӘе…Ёж–°зҡ„иҝӣзЁӢпјҢ并дҪңдёәеҺҹиҝӣзЁӢзҡ„еӯҗиҝӣзЁӢ
йҡҗжӮЈпјҡиӢҘеҪ“еүҚзҡ„иҝӣзЁӢзҡ„ж•°жҚ®йҮҸеәһеӨ§пјҢйӮЈд№Ҳ fork д№ӢеҗҺж•°жҚ®йҮҸ*2,жӯӨж—¶е°ұдјҡйҖ жҲҗжңҚеҠЎеҷЁеҺӢеҠӣеӨ§пјҢиҝҗиЎҢжҖ§иғҪйҷҚдҪҺгҖӮ
Rdb дҝқеӯҳзҡ„жҳҜ dump.rdb ж–Ү件

еңЁжөӢиҜ•пјҡжү§иЎҢ flushAll е‘Ҫд»Ө, дҪҝз”Ё shutDown зӣҙжҺҘе…ій—ӯиҝӣзЁӢж—¶пјҢ第дәҢж¬Ўжү“ејҖж—¶ redis дјҡиҮӘеҠЁиҜ»еҸ– dump.rdb ж–Ү件пјҢдҪҶжҳҜжҒўеӨҚж—¶пјҢе…Ёдёәз©әгҖӮ(жӯӨж—¶зҡ„еҺҹеӣ пјҡеңЁе…ій—ӯж—¶еҲ»пјҢredis зі»з»ҹдјҡдҝқеӯҳз©әзҡ„ dump.rdb жӣҝжҚўеҺҹжқҘзҡ„зј“еӯҳж–Ү件гҖӮжүҖд»Ҙ第дәҢж¬Ўжү“ејҖзҡ„ redisзі»з»ҹж—¶еҖҷпјҢиҮӘеҠЁиҜ»еҸ–зҡ„жҳҜз©әеҖјж–Ү件)
RDB save ж“ҚдҪң
Rdb жҳҜж•ҙдёӘеҶ…еӯҳзҡ„еҺӢзј©зҡ„ snapshotпјҢRDB зҡ„ж•°жҚ®з»“жһ„пјҢеҸҜд»Ҙй…ҚзҪ®з¬ҰеҗҲеҝ«з…§и§ҰеҸ‘жқЎд»¶пјҢй»ҳи®Өзҡ„жҳҜ 1 еҲҶй’ҹеҶ…ж”№еҠЁ 1 дёҮж¬ЎпјҢжҲ–иҖ… 5 еҲҶй’ҹж”№еҠЁ 10 ж¬ЎпјҢжҲ–иҖ…жҳҜ 15 еҲҶй’ҹж”№еҠЁдёҖж¬Ўпјӣ
Save зҰҒз”ЁпјҡеҰӮжһңжғізҰҒз”Ё RDB жҢҒд№…еҢ–зҡ„зӯ–з•ҘпјҢеҸӘиҰҒдёҚи®ҫзҪ®д»»дҪ• save жҢҮд»ӨпјҢжҲ–иҖ…жҳҜз»ҷ save дј е…ҘдёҖдёӘз©әеӯ—з¬ҰдёІеҸӮж•°д№ҹеҸҜд»ҘгҖӮ
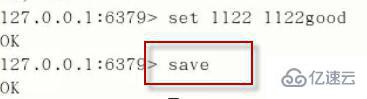
-----> save жҢҮд»ӨпјҡеҚіеҲ»дҝқеӯҳж“ҚдҪңеҜ№иұЎ
еҰӮдҪ•и§ҰеҸ‘ RDB еҝ«з…§
Saveпјҡsave ж—¶еҸӘз®ЎдҝқеӯҳпјҢе…¶д»–дёҚз®ЎпјҢе…ЁйғЁйҳ»еЎһгҖӮ
Bgsaveпјҡredis дјҡеңЁеҗҺеҸ°иҝӣиЎҢеҝ«з…§ж“ҚдҪңпјҢеҝ«з…§ж“ҚдҪңзҡ„еҗҢж—¶иҝҳеҸҜд»Ҙе“Қеә”е®ўжҲ·з«Ҝзҡ„иҜ·жұӮпјҢеҸҜд»ҘйҖҡиҝҮ lastsave е‘Ҫд»ӨиҺ·еҸ–жңҖеҗҺдёҖж¬ЎжҲҗеҠҹжү§иЎҢеҝ«з…§зҡ„ж—¶й—ҙгҖӮ
жү§иЎҢ fluhall е‘Ҫд»ӨпјҢд№ҹдјҡдә§з”ҹ dump.rdb ж–Ү件пјҢдҪҶйҮҢйқўжҳҜз©әзҡ„гҖӮ
еҰӮдҪ•жҒўеӨҚ:
е°ҶеӨҮд»Ҫж–Ү件(dump.rdb)移еҠЁеҲ° redis е®үиЈ…зӣ®еҪ•е№¶еҗҜеҠЁжңҚеҠЎеҚіеҸҜ
Config get dir е‘Ҫд»ӨеҸҜиҺ·еҸ–зӣ®еҪ•
еҰӮдҪ•еҒңжӯў
еҠЁжҖҒеҒңжӯў RDB дҝқеӯҳ规еҲҷзҡ„ж–№жі•пјҡredis -cli config set save вҖңвҖқ
AOF(Append Only File)
д»Ҙж—Ҙеҝ—зҡ„еҪўејҸдҝ©и®°еҪ•жҜҸдёӘеҶҷж“ҚдҪңпјҢе°Ҷ redis жү§иЎҢиҝҮзҡ„жүҖжңүеҶҷжҢҮд»Өи®°еҪ•дёӢжқҘ(иҜ»ж“ҚдҪңдёҚи®°еҪ•)гҖӮеҸӘи®ёиҝҪеҠ ж–Ү件дҪҶдёҚеҸҜд»Ҙж”№еҶҷж–Ү件пјҢredis еҗҜеҠЁд№ӢеҲқдјҡиҜ»еҸ–иҜҘж–Ү件йҮҚж–°жһ„е»әж•°жҚ®пјҢжҚўиЁҖд№ӢпјҢredisйҮҚеҗҜзҡ„иҜқе°ұж №жҚ®ж—Ҙеҝ—ж–Ү件зҡ„еҶ…е®№е°ҶеҶҷжҢҮд»Өд»ҺеүҚеҲ°еҗҺжү§иЎҢдёҖж¬ЎдёҖе®ҢжҲҗж•°жҚ®жҒўеӨҚе·ҘдҪңгҖӮ
======APPEND ONLY MODE=====
ејҖеҗҜ aof пјҡappendonly yes (й»ҳи®ӨжҳҜ no)

жіЁж„Ҹпјҡ
еңЁе®һйҷ…е·ҘдҪңз”ҹдә§зҡ„ж—¶еҖҷеҫҖеҫҖдјҡеҮәзҺ°пјҡaof ж–Ү件жҚҹеқҸ(зҪ‘з»ңдј иҫ“жҲ–иҖ…е…¶д»–й—®йўҳеҜјиҮҙ aof ж–Ү件з ҙеқҸ)
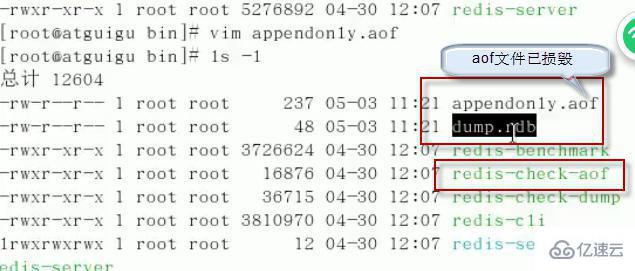
жңҚеҠЎеҷЁеҗҜеҠЁжҠҘй”ҷ(дҪҶжҳҜ dump.rdb ж–Ү件жҳҜе®Ңж•ҙзҡ„) иҜҙжҳҺеҗҜеҠЁе…ҲеҠ иҪҪ aof ж–Ү件
и§ЈеҶіж–№жЎҲпјҡжү§иЎҢе‘Ҫд»Ө redis-check-aof --fix aof ж–Ү件 [иҮӘеҠЁжЈҖжҹҘеҲ йҷӨдёҚе’Ң aof иҜӯжі•зҡ„еӯ—ж®ө]
Aofзӯ–з•Ҙ

Appendfsync еҸӮж•°пјҡ
Always еҗҢжӯҘжҢҒд№…еҢ– жҜҸж¬ЎеҸ‘з”ҹж•°жҚ®еҸҳжӣҙдјҡиў«з«ӢеҚіи®°еҪ•еҲ°зЈҒзӣҳпјҢжҖ§иғҪиҫғе·®дҪҶж•°жҚ®е®Ңж•ҙжҖ§иҫғеҘҪгҖӮ
Everysecпјҡ еҮәеҺӮй»ҳи®ӨжҺЁиҚҗпјҢејӮжӯҘж“ҚдҪңпјҢжҜҸз§’и®°еҪ•пјҢж—ҘиҝҮдёҖз§’е®•жңәпјҢжңүж•°жҚ®дёўеӨұ
Noпјҡд»ҺдёҚ fsync пјҡе°Ҷж•°жҚ®дәӨз»ҷж“ҚдҪңзі»з»ҹжқҘеӨ„зҗҶгҖӮжӣҙеҝ«пјҢд№ҹжӣҙдёҚе®үе…Ёзҡ„йҖүжӢ©гҖӮ
Rewrite
жҰӮеҝөпјҡAOF йҮҮз”Ёж–Ү件иҝҪеҠ ж–№ејҸпјҢж–Ү件дјҡи¶ҠжқҘи¶ҠжқҘеӨ§дёәйҒҝе…ҚеҮәзҺ°жӯӨз§Қжғ…еҶөпјҢж–°еўһдәҶйҮҚеҶҷжңәеҲ¶пјҢaof ж–Ү件зҡ„еӨ§е°Ҹи¶…иҝҮжүҖи®ҫе®ҡзҡ„йҳҲеҖјж—¶пјҢredis е°ұдјҡиҮӘеҠЁ aof ж–Ү件зҡ„еҶ…е®№еҺӢзј©пјҢеҖјдҝқз•ҷеҸҜд»ҘжҒўеӨҚж•°жҚ®зҡ„жңҖе°ҸжҢҮд»ӨйӣҶпјҢеҸҜд»ҘдҪҝз”Ёе‘Ҫд»Ө bgrewirteaofгҖӮ
йҮҚеҶҷеҺҹзҗҶпјҡaof ж–Ү件жҢҒз»ӯеўһй•ҝиҖҢеӨ§ж—¶пјҢдјҡ fork еҮәдёҖжқЎж–°иҝӣзЁӢжқҘе°Ҷж–Ү件йҮҚеҶҷ(д№ҹе°ұ
жҳҜе…ҲеҶҷдёҙж—¶ж–Ү件жңҖеҗҺеҶҚ rename)пјҢйҒҚеҺҶж–°иҝӣзЁӢзҡ„еҶ…еӯҳдёӯзҡ„ж•°жҚ®пјҢжҜҸжқЎи®°еҪ•жңүдёҖжқЎ set иҜӯеҸҘпјҢйҮҚеҶҷ aof ж–Ү件зҡ„ж“ҚдҪңпјҢ并没жңүиҜ»еҸ–ж—§зҡ„зҡ„ aof ж–Ү件пјҢиҖҢжҳҜе°Ҷж•ҙдёӘеҶ…еӯҳзҡ„ж•°жҚ®еә“еҶ…е®№з”Ёе‘Ҫд»Өзҡ„ж–№ејҸйҮҚеҶҷдәҶдёҖдёӘж–°зҡ„ aof ж–Ү件пјҢиҝҷзӮ№е’Ңеҝ«з…§жңүзӮ№зұ»дјјгҖӮ
и§ҰеҸ‘жңәеҲ¶пјҡredis дјҡи®°еҪ•дёҠж¬ЎйҮҚеҶҷзҡ„ aof зҡ„еӨ§е°ҸпјҢй»ҳи®Өзҡ„й…ҚзҪ®еҪ“ aof ж–Ү件еӨ§е°ҸдёҠж¬Ў rewrite еҗҺеӨ§е°Ҹзҡ„дёҖеҖҚдё”ж–Ү件еӨ§дәҺ 64M и§ҰеҸ‘(3G)
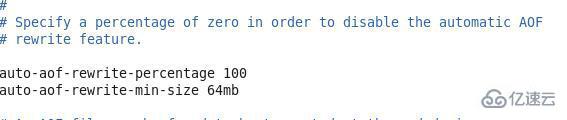
no-appendfsync-on-rewrite no : йҮҚеҶҷж—¶жҳҜеҗҰеҸҜд»Ҙиҝҗз”Ё Appendfsync з”Ёй»ҳи®Ө no еҚіеҸҜпјҢдҝқиҜҒж•°жҚ®е®үе…Ё
auto-aof-rewrite-percentage еҖҚж•° и®ҫзҪ®еҹәеҮҶеҖј
auto-aof-rewrite-min-size и®ҫзҪ®еҹәеҮҶеҖјеӨ§е°Ҹ
AOFдјҳзӮ№
дҪҝз”Ё AOF жҢҒд№…еҢ–дјҡи®© Redis еҸҳеҫ—йқһеёёиҖҗд№…пјҡдҪ еҸҜд»Ҙи®ҫзҪ®дёҚеҗҢзҡ„ fsync зӯ–з•ҘпјҢжҜ”еҰӮж— fsync пјҢжҜҸз§’й’ҹдёҖж¬Ў fsync пјҢжҲ–иҖ…жҜҸж¬Ўжү§иЎҢеҶҷе…Ҙе‘Ҫд»Өж—¶ fsync гҖӮ AOF зҡ„й»ҳи®Өзӯ–з•ҘдёәжҜҸз§’й’ҹ fsync дёҖж¬ЎпјҢеңЁиҝҷз§Қй…ҚзҪ®дёӢпјҢRedis д»Қ然еҸҜд»ҘдҝқжҢҒиүҜеҘҪзҡ„жҖ§иғҪпјҢ并且е°ұз®—еҸ‘з”ҹж•…йҡңеҒңжңәпјҢд№ҹжңҖеӨҡеҸӘдјҡдёўеӨұдёҖз§’й’ҹзҡ„ж•°жҚ®пјҲ fsync дјҡеңЁеҗҺеҸ°зәҝзЁӢжү§иЎҢпјҢжүҖд»Ҙдё»зәҝзЁӢеҸҜд»Ҙ继з»ӯеҠӘеҠӣең°еӨ„зҗҶе‘Ҫд»ӨиҜ·жұӮпјүгҖӮ
AOF ж–Ү件жҳҜдёҖдёӘеҸӘиҝӣиЎҢиҝҪеҠ ж“ҚдҪңзҡ„ж—Ҙеҝ—ж–Ү件пјҲappend only logпјүпјҢ еӣ жӯӨеҜ№ AOF ж–Ү件зҡ„еҶҷе…ҘдёҚйңҖиҰҒиҝӣиЎҢ seek пјҢ еҚідҪҝж—Ҙеҝ—еӣ дёәжҹҗдәӣеҺҹеӣ иҖҢеҢ…еҗ«дәҶжңӘеҶҷе…Ҙе®Ңж•ҙзҡ„е‘Ҫд»ӨпјҲжҜ”еҰӮеҶҷе…Ҙж—¶зЈҒзӣҳе·Іж»ЎпјҢеҶҷе…ҘдёӯйҖ”еҒңжңәпјҢзӯүзӯүпјүпјҢ redis-check-aof е·Ҙе…·д№ҹеҸҜд»ҘиҪ»жҳ“ең°дҝ®еӨҚиҝҷз§Қй—®йўҳгҖӮ
Redis еҸҜд»ҘеңЁ AOF ж–Ү件дҪ“з§ҜеҸҳеҫ—иҝҮеӨ§ж—¶пјҢиҮӘеҠЁең°еңЁеҗҺеҸ°еҜ№ AOF иҝӣиЎҢйҮҚеҶҷпјҡ йҮҚеҶҷеҗҺзҡ„ж–° AOF ж–Ү件еҢ…еҗ«дәҶжҒўеӨҚеҪ“еүҚж•°жҚ®йӣҶжүҖйңҖзҡ„жңҖе°Ҹе‘Ҫд»ӨйӣҶеҗҲгҖӮ ж•ҙдёӘйҮҚеҶҷж“ҚдҪңжҳҜз»қеҜ№е®үе…Ёзҡ„пјҢеӣ дёә Redis еңЁеҲӣе»әж–° AOF ж–Ү件зҡ„иҝҮзЁӢдёӯпјҢдјҡ继з»ӯе°Ҷе‘Ҫд»ӨиҝҪеҠ еҲ°зҺ°жңүзҡ„ AOF ж–Ү件йҮҢйқўпјҢеҚідҪҝйҮҚеҶҷиҝҮзЁӢдёӯеҸ‘з”ҹеҒңжңәпјҢзҺ°жңүзҡ„ AOF ж–Ү件д№ҹдёҚдјҡдёўеӨұгҖӮ иҖҢдёҖж—Ұж–° AOF ж–Ү件еҲӣе»әе®ҢжҜ•пјҢRedis е°ұдјҡд»Һж—§ AOF ж–Ү件еҲҮжҚўеҲ°ж–° AOF ж–Ү件пјҢ并ејҖе§ӢеҜ№ж–° AOF ж–Ү件иҝӣиЎҢиҝҪеҠ ж“ҚдҪңгҖӮ
AOF ж–Ү件жңүеәҸең°дҝқеӯҳдәҶеҜ№ж•°жҚ®еә“жү§иЎҢзҡ„жүҖжңүеҶҷе…Ҙж“ҚдҪңпјҢ иҝҷдәӣеҶҷе…Ҙж“ҚдҪңд»Ҙ Redis еҚҸи®®зҡ„ж јејҸдҝқеӯҳпјҢ еӣ жӯӨ AOF ж–Ү件зҡ„еҶ…е®№йқһеёёе®№жҳ“иў«дәәиҜ»жҮӮпјҢ еҜ№ж–Ү件иҝӣиЎҢеҲҶжһҗпјҲparseпјүд№ҹеҫҲиҪ»жқҫгҖӮ еҜјеҮәпјҲexportпјү AOF ж–Ү件д№ҹйқһеёёз®ҖеҚ•пјҡ дёҫдёӘдҫӢеӯҗпјҢ еҰӮжһңдҪ дёҚе°Ҹеҝғжү§иЎҢдәҶ FLUSHALL е‘Ҫд»ӨпјҢ дҪҶеҸӘиҰҒ AOF ж–Ү件жңӘиў«йҮҚеҶҷпјҢ йӮЈд№ҲеҸӘиҰҒеҒңжӯўжңҚеҠЎеҷЁпјҢ 移йҷӨ AOF ж–Ү件жң«е°ҫзҡ„ FLUSHALL е‘Ҫд»ӨпјҢ 并йҮҚеҗҜ Redis пјҢ е°ұеҸҜд»Ҙе°Ҷж•°жҚ®йӣҶжҒўеӨҚеҲ° FLUSHALL жү§иЎҢд№ӢеүҚзҡ„зҠ¶жҖҒгҖӮ
AOFзјәзӮ№
еҜ№дәҺзӣёеҗҢзҡ„ж•°жҚ®йӣҶжқҘиҜҙпјҢAOF ж–Ү件зҡ„дҪ“з§ҜйҖҡеёёиҰҒеӨ§дәҺ RDB ж–Ү件зҡ„дҪ“з§ҜгҖӮ
ж №жҚ®жүҖдҪҝз”Ёзҡ„ fsync зӯ–з•ҘпјҢAOF зҡ„йҖҹеәҰеҸҜиғҪдјҡж…ўдәҺ RDB гҖӮ еңЁдёҖиҲ¬жғ…еҶөдёӢпјҢ жҜҸз§’ fsync зҡ„жҖ§иғҪдҫқ然йқһеёёй«ҳпјҢ иҖҢе…ій—ӯ fsync еҸҜд»Ҙи®© AOF зҡ„йҖҹеәҰе’Ң RDB дёҖж ·еҝ«пјҢ еҚідҪҝеңЁй«ҳиҙҹиҚ·д№ӢдёӢд№ҹжҳҜеҰӮжӯӨгҖӮ дёҚиҝҮеңЁеӨ„зҗҶе·ЁеӨ§зҡ„еҶҷе…ҘиҪҪе…Ҙж—¶пјҢRDB еҸҜд»ҘжҸҗдҫӣжӣҙжңүдҝқиҜҒзҡ„жңҖеӨ§е»¶иҝҹж—¶й—ҙпјҲlatencyпјүгҖӮ
AOF еңЁиҝҮеҺ»жӣҫз»ҸеҸ‘з”ҹиҝҮиҝҷж ·зҡ„ bug пјҡ еӣ дёәдёӘеҲ«е‘Ҫд»Өзҡ„еҺҹеӣ пјҢеҜјиҮҙ AOF ж–Ү件еңЁйҮҚж–°иҪҪе…Ҙж—¶пјҢж— жі•е°Ҷж•°жҚ®йӣҶжҒўеӨҚжҲҗдҝқеӯҳж—¶зҡ„еҺҹж ·гҖӮ пјҲдёҫдёӘдҫӢеӯҗпјҢйҳ»еЎһе‘Ҫд»Ө BRPOPLPUSH е°ұжӣҫз»Ҹеј•иө·иҝҮиҝҷж ·зҡ„ bug гҖӮпјү
жөӢиҜ•еҘ—件йҮҢдёәиҝҷз§Қжғ…еҶөж·»еҠ дәҶжөӢиҜ•пјҡ е®ғ们дјҡиҮӘеҠЁз”ҹжҲҗйҡҸжңәзҡ„гҖҒеӨҚжқӮзҡ„ж•°жҚ®йӣҶпјҢ并йҖҡиҝҮйҮҚж–°иҪҪе…Ҙиҝҷдәӣж•°жҚ®жқҘзЎ®дҝқдёҖеҲҮжӯЈеёёгҖӮиҷҪ然иҝҷз§Қ bug еңЁ AOF ж–Ү件дёӯ并дёҚеёёи§ҒпјҢ дҪҶжҳҜеҜ№жҜ”жқҘиҜҙпјҢ RDB еҮ д№ҺжҳҜдёҚеҸҜиғҪеҮәзҺ°иҝҷз§Қ bug зҡ„гҖӮ
еӨҮд»ҪRedis ж•°жҚ®
дёҖе®ҡиҰҒеӨҮд»ҪдҪ зҡ„ж•°жҚ®еә“пјҒ
зЈҒзӣҳж•…йҡңпјҢ иҠӮзӮ№еӨұж•ҲпјҢ иҜёеҰӮжӯӨзұ»зҡ„й—®йўҳйғҪеҸҜиғҪи®©дҪ зҡ„ж•°жҚ®ж¶ҲеӨұдёҚи§ҒпјҢ дёҚиҝӣиЎҢеӨҮд»ҪжҳҜйқһеёёеҚұйҷ©зҡ„гҖӮ
Redis еҜ№дәҺж•°жҚ®еӨҮд»ҪжҳҜйқһеёёеҸӢеҘҪзҡ„пјҢ еӣ дёәдҪ еҸҜд»ҘеңЁжңҚеҠЎеҷЁиҝҗиЎҢзҡ„ж—¶еҖҷеҜ№ RDB ж–Ү件иҝӣиЎҢеӨҚеҲ¶пјҡ RDB ж–Ү件дёҖж—Ұиў«еҲӣе»әпјҢ е°ұдёҚдјҡиҝӣиЎҢд»»дҪ•дҝ®ж”№гҖӮ еҪ“жңҚеҠЎеҷЁиҰҒеҲӣе»әдёҖдёӘж–°зҡ„ RDB ж–Ү件时пјҢ е®ғе…Ҳе°Ҷж–Ү件зҡ„еҶ…е®№дҝқеӯҳеңЁдёҖдёӘдёҙж—¶ж–Ү件йҮҢйқўпјҢ еҪ“дёҙж—¶ж–Ү件еҶҷе…Ҙе®ҢжҜ•ж—¶пјҢ зЁӢеәҸжүҚдҪҝз”Ё rename(2) еҺҹеӯҗең°з”Ёдёҙж—¶ж–Ү件жӣҝжҚўеҺҹжқҘзҡ„ RDB ж–Ү件гҖӮ
иҝҷд№ҹе°ұжҳҜиҜҙпјҢ ж— и®әдҪ•ж—¶пјҢ еӨҚеҲ¶ RDB ж–Ү件йғҪжҳҜз»қеҜ№е®үе…Ёзҡ„гҖӮ
е»әи®®пјҡ
еҲӣе»әдёҖдёӘе®ҡжңҹд»»еҠЎпјҲcron jobпјүпјҢ жҜҸе°Ҹж—¶е°ҶдёҖдёӘ RDB ж–Ү件еӨҮд»ҪеҲ°дёҖдёӘж–Ү件еӨ№пјҢ 并且жҜҸеӨ©е°ҶдёҖдёӘ RDB ж–Ү件еӨҮд»ҪеҲ°еҸҰдёҖдёӘж–Ү件еӨ№гҖӮ
зЎ®дҝқеҝ«з…§зҡ„еӨҮд»ҪйғҪеёҰжңүзӣёеә”зҡ„ж—Ҙжңҹе’Ңж—¶й—ҙдҝЎжҒҜпјҢ жҜҸж¬Ўжү§иЎҢе®ҡжңҹд»»еҠЎи„ҡжң¬ж—¶пјҢ дҪҝз”Ё find е‘Ҫд»ӨжқҘеҲ йҷӨиҝҮжңҹзҡ„еҝ«з…§пјҡ жҜ”еҰӮиҜҙпјҢ дҪ еҸҜд»Ҙдҝқз•ҷжңҖиҝ‘ 48 е°Ҹж—¶еҶ…зҡ„жҜҸе°Ҹж—¶еҝ«з…§пјҢ иҝҳеҸҜд»Ҙдҝқз•ҷжңҖиҝ‘дёҖдёӨдёӘжңҲзҡ„жҜҸж—Ҙеҝ«з…§гҖӮ
иҮіе°‘жҜҸеӨ©дёҖж¬ЎпјҢ е°Ҷ RDB еӨҮд»ҪеҲ°дҪ зҡ„ж•°жҚ®дёӯеҝғд№ӢеӨ–пјҢ жҲ–иҖ…иҮіе°‘жҳҜеӨҮд»ҪеҲ°дҪ иҝҗиЎҢ Redis жңҚеҠЎеҷЁзҡ„зү©зҗҶжңәеҷЁд№ӢеӨ–гҖӮ
е®№зҒҫеӨҮд»Ҫ
Redis зҡ„е®№зҒҫеӨҮд»Ҫеҹәжң¬дёҠе°ұжҳҜеҜ№ж•°жҚ®иҝӣиЎҢеӨҮд»ҪпјҢ 并е°ҶиҝҷдәӣеӨҮд»Ҫдј йҖҒеҲ°еӨҡдёӘдёҚеҗҢзҡ„еӨ–йғЁж•°жҚ®дёӯеҝғгҖӮ
е®№зҒҫеӨҮд»ҪеҸҜд»ҘеңЁ Redis иҝҗиЎҢ并дә§з”ҹеҝ«з…§зҡ„дё»ж•°жҚ®дёӯеҝғеҸ‘з”ҹдёҘйҮҚзҡ„й—®йўҳж—¶пјҢ д»Қ然让数жҚ®еӨ„дәҺе®үе…ЁзҠ¶жҖҒгҖӮ
жңүзҡ„Redis з”ЁжҲ·жҳҜеҲӣдёҡиҖ…пјҢ 他们没жңүеӨ§жҠҠеӨ§жҠҠзҡ„й’ұеҸҜд»ҘжөӘиҙ№пјҢ жүҖд»ҘдёӢйқўд»Ӣз»Қзҡ„йғҪжҳҜдёҖдәӣе®һз”ЁеҸҲдҫҝе®ңзҡ„е®№зҒҫеӨҮд»Ҫж–№жі•пјҡ
Amazon S3 пјҢд»ҘеҸҠе…¶д»–зұ»дјј S3 зҡ„жңҚеҠЎпјҢжҳҜдёҖдёӘжһ„е»әзҒҫйҡҫеӨҮд»Ҫзі»з»ҹзҡ„еҘҪең°ж–№гҖӮ жңҖз®ҖеҚ•зҡ„ж–№жі•е°ұжҳҜе°ҶдҪ зҡ„жҜҸе°Ҹж—¶жҲ–иҖ…жҜҸж—Ҙ RDB еӨҮд»ҪеҠ еҜҶе№¶дј йҖҒеҲ° S3 гҖӮ еҜ№ж•°жҚ®зҡ„еҠ еҜҶеҸҜд»ҘйҖҡиҝҮ gpg -c е‘Ҫд»ӨжқҘе®ҢжҲҗпјҲеҜ№з§°еҠ еҜҶжЁЎејҸпјүгҖӮ и®°еҫ—жҠҠдҪ зҡ„еҜҶз Ғж”ҫеҲ°еҮ дёӘдёҚеҗҢзҡ„гҖҒе®үе…Ёзҡ„ең°ж–№еҺ»пјҲжҜ”еҰӮдҪ еҸҜд»ҘжҠҠеҜҶз ҒеӨҚеҲ¶з»ҷдҪ з»„з»ҮйҮҢжңҖйҮҚиҰҒзҡ„дәәзү©пјүгҖӮ еҗҢж—¶дҪҝз”ЁеӨҡдёӘеӮЁеӯҳжңҚеҠЎжқҘдҝқеӯҳж•°жҚ®ж–Ү件пјҢеҸҜд»ҘжҸҗеҚҮж•°жҚ®зҡ„е®үе…ЁжҖ§гҖӮ
дј йҖҒеҝ«з…§еҸҜд»ҘдҪҝз”Ё SCP жқҘе®ҢжҲҗпјҲSSH зҡ„组件пјүгҖӮ д»ҘдёӢжҳҜз®ҖеҚ•е№¶дё”е®үе…Ёзҡ„дј йҖҒж–№жі•пјҡ д№°дёҖдёӘзҰ»дҪ зҡ„ж•°жҚ®дёӯеҝғйқһеёёиҝңзҡ„ VPS(иҷҡжӢҹдё“з”ЁжңҚеҠЎеҷЁ) пјҢ иЈ…дёҠ SSH пјҢ еҲӣе»әдёҖдёӘж— еҸЈд»Өзҡ„ SSH е®ўжҲ·з«Ҝ key пјҢ 并е°ҶиҝҷдёӘ key ж·»еҠ еҲ° VPS зҡ„ authorized_keys ж–Ү件дёӯпјҢ иҝҷж ·е°ұеҸҜд»Ҙеҗ‘иҝҷдёӘ VPS дј йҖҒеҝ«з…§еӨҮд»Ҫж–Ү件дәҶгҖӮ дёәдәҶиҫҫеҲ°жңҖеҘҪзҡ„ж•°жҚ®е®үе…ЁжҖ§пјҢиҮіе°‘иҰҒд»ҺдёӨдёӘдёҚеҗҢзҡ„жҸҗдҫӣе•ҶйӮЈйҮҢеҗ„иҙӯд№°дёҖдёӘ VPS жқҘиҝӣиЎҢж•°жҚ®е®№зҒҫеӨҮд»ҪгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢ иҝҷзұ»е®№зҒҫзі»з»ҹеҰӮжһңжІЎжңүе°Ҹеҝғең°иҝӣиЎҢеӨ„зҗҶзҡ„иҜқпјҢ жҳҜеҫҲе®№жҳ“еӨұж•Ҳзҡ„гҖӮ
жңҖдҪҺйҷҗеәҰдёӢпјҢ дҪ еә”иҜҘеңЁж–Үд»¶дј йҖҒе®ҢжҜ•д№ӢеҗҺпјҢ жЈҖжҹҘжүҖдј йҖҒеӨҮд»Ҫж–Ү件зҡ„дҪ“з§Ҝе’ҢеҺҹе§Ӣеҝ«з…§ж–Ү件зҡ„дҪ“з§ҜжҳҜеҗҰзӣёеҗҢгҖӮ еҰӮжһңдҪ дҪҝз”Ёзҡ„жҳҜ VPS пјҢ йӮЈд№ҲиҝҳеҸҜд»ҘйҖҡиҝҮжҜ”еҜ№ж–Ү件зҡ„ SHA1 ж ЎйӘҢе’ҢжқҘзЎ®и®Өж–Ү件жҳҜеҗҰдј йҖҒе®Ңж•ҙгҖӮ
еҸҰеӨ–пјҢ дҪ иҝҳйңҖиҰҒдёҖдёӘзӢ¬з«Ӣзҡ„иӯҰжҠҘзі»з»ҹпјҢ и®©е®ғеңЁиҙҹиҙЈдј йҖҒеӨҮд»Ҫж–Ү件зҡ„дј йҖҒеҷЁпјҲtransferпјүеӨұзҒөж—¶йҖҡзҹҘдҪ гҖӮ
Redisдё»д»ҺеӨҚеҲ¶
Redis ж”ҜжҢҒз®ҖеҚ•дё”жҳ“з”Ёзҡ„дё»д»ҺеӨҚеҲ¶пјҲmaster-slave replicationпјүеҠҹиғҪпјҢ иҜҘеҠҹиғҪеҸҜд»Ҙи®©д»ҺжңҚеҠЎеҷЁ(slave server)жҲҗдёәдё»жңҚеҠЎеҷЁ(master server)зҡ„зІҫзЎ®еӨҚеҲ¶е“ҒгҖӮ
д»ҘдёӢжҳҜе…ідәҺ Redis еӨҚеҲ¶еҠҹиғҪзҡ„еҮ дёӘйҮҚиҰҒж–№йқўпјҡ
Redis дҪҝз”ЁејӮжӯҘеӨҚеҲ¶гҖӮ д»Һ Redis 2.8 ејҖе§ӢпјҢ д»ҺжңҚеҠЎеҷЁдјҡд»ҘжҜҸз§’дёҖж¬Ўзҡ„йў‘зҺҮеҗ‘дё»жңҚеҠЎеҷЁжҠҘе‘ҠеӨҚеҲ¶жөҒпјҲreplication streamпјүзҡ„еӨ„зҗҶиҝӣеәҰгҖӮ
дёҖдёӘдё»жңҚеҠЎеҷЁеҸҜд»ҘжңүеӨҡдёӘд»ҺжңҚеҠЎеҷЁгҖӮ
дёҚд»…дё»жңҚеҠЎеҷЁеҸҜд»Ҙжңүд»ҺжңҚеҠЎеҷЁпјҢ д»ҺжңҚеҠЎеҷЁд№ҹеҸҜд»ҘжңүиҮӘе·ұзҡ„д»ҺжңҚеҠЎеҷЁпјҢ еӨҡдёӘд»ҺжңҚеҠЎеҷЁд№Ӣй—ҙеҸҜд»Ҙжһ„жҲҗдёҖдёӘеӣҫзҠ¶з»“жһ„гҖӮ
еӨҚеҲ¶еҠҹиғҪдёҚдјҡйҳ»еЎһдё»жңҚеҠЎеҷЁпјҡ еҚідҪҝжңүдёҖдёӘжҲ–еӨҡдёӘд»ҺжңҚеҠЎеҷЁжӯЈеңЁиҝӣиЎҢеҲқж¬ЎеҗҢжӯҘпјҢ дё»жңҚеҠЎеҷЁд№ҹеҸҜд»Ҙ继з»ӯеӨ„зҗҶе‘Ҫд»ӨиҜ·жұӮгҖӮ
еӨҚеҲ¶еҠҹиғҪд№ҹдёҚдјҡйҳ»еЎһд»ҺжңҚеҠЎеҷЁпјҡ еҸӘиҰҒеңЁ redis.conf ж–Ү件дёӯиҝӣиЎҢдәҶзӣёеә”зҡ„и®ҫзҪ®пјҢ еҚідҪҝд»ҺжңҚеҠЎеҷЁжӯЈеңЁиҝӣиЎҢеҲқж¬ЎеҗҢжӯҘпјҢ жңҚеҠЎеҷЁд№ҹеҸҜд»ҘдҪҝз”Ёж—§зүҲжң¬зҡ„ж•°жҚ®йӣҶжқҘеӨ„зҗҶе‘Ҫд»ӨжҹҘиҜўгҖӮ
дёҚиҝҮпјҢ еңЁд»ҺжңҚеҠЎеҷЁеҲ йҷӨж—§зүҲжң¬ж•°жҚ®йӣҶ并иҪҪе…Ҙж–°зүҲжң¬ж•°жҚ®йӣҶзҡ„йӮЈж®өж—¶й—ҙеҶ…пјҢ иҝһжҺҘиҜ·жұӮдјҡиў«йҳ»еЎһгҖӮ
дҪ иҝҳеҸҜд»Ҙй…ҚзҪ®д»ҺжңҚеҠЎеҷЁпјҢ и®©е®ғеңЁдёҺдё»жңҚеҠЎеҷЁд№Ӣй—ҙзҡ„иҝһжҺҘж–ӯејҖж—¶пјҢ еҗ‘е®ўжҲ·з«ҜеҸ‘йҖҒдёҖдёӘй”ҷиҜҜгҖӮ
еӨҚеҲ¶еҠҹиғҪеҸҜд»ҘеҚ•зәҜең°з”ЁдәҺж•°жҚ®еҶ—дҪҷпјҲdata redundancyпјүпјҢ д№ҹеҸҜд»ҘйҖҡиҝҮи®©еӨҡдёӘд»ҺжңҚеҠЎеҷЁеӨ„зҗҶеҸӘиҜ»е‘Ҫд»ӨиҜ·жұӮжқҘжҸҗеҚҮжү©еұ•жҖ§пјҲscalabilityпјүпјҡ жҜ”еҰӮиҜҙпјҢ з№ҒйҮҚзҡ„ SORT е‘Ҫд»ӨеҸҜд»ҘдәӨз»ҷйҷ„еұһиҠӮзӮ№еҺ»иҝҗиЎҢгҖӮ
еҸҜд»ҘйҖҡиҝҮеӨҚеҲ¶еҠҹиғҪжқҘи®©дё»жңҚеҠЎеҷЁе…ҚдәҺжү§иЎҢжҢҒд№…еҢ–ж“ҚдҪңпјҡ еҸӘиҰҒе…ій—ӯдё»жңҚеҠЎеҷЁзҡ„жҢҒд№…еҢ–еҠҹиғҪпјҢ 然еҗҺз”ұд»ҺжңҚеҠЎеҷЁеҺ»жү§иЎҢжҢҒд№…еҢ–ж“ҚдҪңеҚіеҸҜгҖӮ
е…ій—ӯдё»жңҚеҠЎеҷЁжҢҒд№…еҢ–ж—¶пјҢеӨҚеҲ¶еҠҹиғҪзҡ„ж•°жҚ®е®үе…ЁгҖӮ
еҪ“й…ҚзҪ®RedisеӨҚеҲ¶еҠҹиғҪж—¶пјҢејәзғҲе»әи®®жү“ејҖдё»жңҚеҠЎеҷЁзҡ„жҢҒд№…еҢ–еҠҹиғҪгҖӮ еҗҰеҲҷзҡ„иҜқпјҢз”ұдәҺ延иҝҹзӯүй—®йўҳпјҢйғЁзҪІзҡ„жңҚеҠЎеә”иҜҘиҰҒйҒҝе…ҚиҮӘеҠЁжӢүиө·гҖӮ
жЎҲдҫӢпјҡ
еҒҮи®ҫиҠӮзӮ№Aдёәдё»жңҚеҠЎеҷЁпјҢ并且关й—ӯдәҶжҢҒд№…еҢ–гҖӮ 并且иҠӮзӮ№Bе’ҢиҠӮзӮ№Cд»ҺиҠӮзӮ№AеӨҚеҲ¶ж•°жҚ®
иҠӮзӮ№Aеҙ©жәғпјҢ然еҗҺз”ұиҮӘеҠЁжӢүиө·жңҚеҠЎйҮҚеҗҜдәҶиҠӮзӮ№A. з”ұдәҺиҠӮзӮ№Aзҡ„жҢҒд№…еҢ–иў«е…ій—ӯдәҶпјҢжүҖд»ҘйҮҚеҗҜд№ӢеҗҺжІЎжңүд»»дҪ•ж•°жҚ®
иҠӮзӮ№Bе’ҢиҠӮзӮ№Cе°Ҷд»ҺиҠӮзӮ№AеӨҚеҲ¶ж•°жҚ®пјҢдҪҶжҳҜAзҡ„ж•°жҚ®жҳҜз©әзҡ„пјҢ дәҺжҳҜе°ұжҠҠиҮӘиә«дҝқеӯҳзҡ„ж•°жҚ®еүҜжң¬еҲ йҷӨгҖӮ
еңЁе…ій—ӯдё»жңҚеҠЎеҷЁдёҠзҡ„жҢҒд№…еҢ–пјҢ并еҗҢж—¶ејҖеҗҜиҮӘеҠЁжӢүиө·иҝӣзЁӢзҡ„жғ…еҶөдёӢпјҢеҚідҫҝдҪҝз”ЁSentinelжқҘе®һзҺ°Redisзҡ„й«ҳеҸҜз”ЁжҖ§пјҢд№ҹжҳҜйқһеёёеҚұйҷ©зҡ„гҖӮ еӣ дёәдё»жңҚеҠЎеҷЁеҸҜиғҪжӢүиө·еҫ—йқһеёёеҝ«пјҢд»ҘиҮідәҺSentinelеңЁй…ҚзҪ®зҡ„еҝғи·іж—¶й—ҙй—ҙйҡ”еҶ…жІЎжңүжЈҖжөӢеҲ°дё»жңҚеҠЎеҷЁе·Іиў«йҮҚеҗҜпјҢ然еҗҺиҝҳжҳҜдјҡжү§иЎҢдёҠйқўзҡ„ж•°жҚ®дёўеӨұзҡ„жөҒзЁӢгҖӮ
ж— и®әдҪ•ж—¶пјҢж•°жҚ®е®үе…ЁйғҪжҳҜжһҒе…¶йҮҚиҰҒзҡ„пјҢжүҖд»Ҙеә”иҜҘзҰҒжӯўдё»жңҚеҠЎеҷЁе…ій—ӯжҢҒд№…еҢ–зҡ„еҗҢж—¶иҮӘеҠЁжӢүиө·гҖӮ
д»ҺжңҚеҠЎеҷЁй…ҚзҪ®
й…ҚзҪ®дёҖдёӘд»ҺжңҚеҠЎеҷЁйқһеёёз®ҖеҚ•пјҢ еҸӘиҰҒеңЁй…ҚзҪ®ж–Ү件дёӯеўһеҠ д»ҘдёӢзҡ„иҝҷдёҖиЎҢе°ұеҸҜд»ҘдәҶпјҡ
slaveof 192.168.1.1 6379
еҸҰеӨ–дёҖз§Қж–№жі•жҳҜи°ғз”Ё SLAVEOF е‘Ҫд»ӨпјҢиҫ“е…Ҙдё»жңҚеҠЎеҷЁзҡ„ IP е’Ңз«ҜеҸЈпјҢ然еҗҺеҗҢжӯҘе°ұдјҡејҖе§Ӣ
127.0.0.1:6379> SLAVEOF 192.168.1.1 10086
OK
еҸӘиҜ»д»ҺжңҚеҠЎеҷЁ
д»Һ Redis 2.6 ејҖе§ӢпјҢ д»ҺжңҚеҠЎеҷЁж”ҜжҢҒеҸӘиҜ»жЁЎејҸпјҢ 并且иҜҘжЁЎејҸдёәд»ҺжңҚеҠЎеҷЁзҡ„й»ҳи®ӨжЁЎејҸгҖӮ
еҸӘиҜ»жЁЎејҸз”ұ redis.conf ж–Ү件дёӯзҡ„ slave-read-only йҖүйЎ№жҺ§еҲ¶пјҢ д№ҹеҸҜд»ҘйҖҡиҝҮ CONFIG SET е‘Ҫд»ӨжқҘејҖеҗҜжҲ–е…ій—ӯиҝҷдёӘжЁЎејҸгҖӮ
еҸӘиҜ»д»ҺжңҚеҠЎеҷЁдјҡжӢ’з»қжү§иЎҢд»»дҪ•еҶҷе‘Ҫд»ӨпјҢ жүҖд»ҘдёҚдјҡеҮәзҺ°еӣ дёәж“ҚдҪңеӨұиҜҜиҖҢе°Ҷж•°жҚ®дёҚе°ҸеҝғеҶҷе…ҘеҲ°дәҶд»ҺжңҚеҠЎеҷЁзҡ„жғ…еҶөгҖӮ
еҸҰеӨ–пјҢеҜ№дёҖдёӘд»ҺеұһжңҚеҠЎеҷЁжү§иЎҢе‘Ҫд»Ө SLAVEOF NO ONE е°ҶдҪҝеҫ—иҝҷдёӘд»ҺеұһжңҚеҠЎеҷЁе…ій—ӯеӨҚеҲ¶еҠҹиғҪпјҢ并д»Һд»ҺеұһжңҚеҠЎеҷЁиҪ¬еҸҳеӣһдё»жңҚеҠЎеҷЁпјҢеҺҹжқҘеҗҢжӯҘжүҖеҫ—зҡ„ж•°жҚ®йӣҶдёҚдјҡиў«дёўејғгҖӮ
еҲ©з”ЁгҖҺ SLAVEOF NO ONE дёҚдјҡдёўејғеҗҢжӯҘжүҖеҫ—ж•°жҚ®йӣҶгҖҸиҝҷдёӘзү№жҖ§пјҢеҸҜд»ҘеңЁдё»жңҚеҠЎеҷЁеӨұиҙҘзҡ„ж—¶еҖҷпјҢе°Ҷд»ҺеұһжңҚеҠЎеҷЁз”ЁдҪңж–°зҡ„дё»жңҚеҠЎеҷЁпјҢд»ҺиҖҢе®һзҺ°ж— й—ҙж–ӯиҝҗиЎҢгҖӮ
д»ҺжңҚеҠЎеҷЁзӣёе…ій…ҚзҪ®пјҡ
еҰӮжһңдё»жңҚеҠЎеҷЁйҖҡиҝҮ requirepass йҖүйЎ№и®ҫзҪ®дәҶеҜҶз ҒпјҢ йӮЈд№ҲдёәдәҶи®©д»ҺжңҚеҠЎеҷЁзҡ„еҗҢжӯҘж“ҚдҪңеҸҜд»ҘйЎәеҲ©иҝӣиЎҢпјҢ жҲ‘们д№ҹеҝ…йЎ»дёәд»ҺжңҚеҠЎеҷЁиҝӣиЎҢзӣёеә”зҡ„иә«д»ҪйӘҢиҜҒи®ҫзҪ®гҖӮ
еҜ№дәҺдёҖдёӘжӯЈеңЁиҝҗиЎҢзҡ„жңҚеҠЎеҷЁпјҢ еҸҜд»ҘдҪҝз”Ёе®ўжҲ·з«Ҝиҫ“е…Ҙд»ҘдёӢе‘Ҫд»Өпјҡ
config set masterauth <password>
иҰҒж°ёд№…ең°и®ҫзҪ®иҝҷдёӘеҜҶз ҒпјҢ йӮЈд№ҲеҸҜд»Ҙе°Ҷе®ғеҠ е…ҘеҲ°й…ҚзҪ®ж–Ү件дёӯпјҡ
masterauth <password>
дё»жңҚеҠЎеҷЁеҸӘеңЁжңүиҮіе°‘ N дёӘд»ҺжңҚеҠЎеҷЁзҡ„жғ…еҶөдёӢпјҢжүҚжү§иЎҢеҶҷж“ҚдҪң
д»Һ Redis 2.8 ејҖе§ӢпјҢ дёәдәҶдҝқиҜҒж•°жҚ®зҡ„е®үе…ЁжҖ§пјҢеҸҜд»ҘйҖҡиҝҮй…ҚзҪ®пјҢ и®©дё»жңҚеҠЎеҷЁеҸӘеңЁжңүиҮіе°‘ N дёӘеҪ“еүҚе·ІиҝһжҺҘд»ҺжңҚеҠЎеҷЁзҡ„жғ…еҶөдёӢпјҢ жүҚжү§иЎҢеҶҷе‘Ҫд»ӨгҖӮ
дёҚиҝҮпјҢ еӣ дёә Redis дҪҝз”ЁејӮжӯҘеӨҚеҲ¶пјҢ жүҖд»Ҙдё»жңҚеҠЎеҷЁеҸ‘йҖҒзҡ„еҶҷж•°жҚ®е№¶дёҚдёҖе®ҡдјҡиў«д»ҺжңҚеҠЎеҷЁжҺҘ收еҲ°пјҢ еӣ жӯӨпјҢ ж•°жҚ®дёўеӨұзҡ„еҸҜиғҪжҖ§д»Қ然жҳҜеӯҳеңЁзҡ„гҖӮ
д»ҘдёӢжҳҜиҝҷдёӘзү№жҖ§зҡ„иҝҗдҪңеҺҹзҗҶпјҡ
д»ҺжңҚеҠЎеҷЁд»ҘжҜҸз§’дёҖж¬Ўзҡ„йў‘зҺҮ PING дё»жңҚеҠЎеҷЁдёҖж¬ЎпјҢ 并жҠҘе‘ҠеӨҚеҲ¶жөҒзҡ„еӨ„зҗҶжғ…еҶөгҖӮ
дё»жңҚеҠЎеҷЁдјҡи®°еҪ•еҗ„дёӘд»ҺжңҚеҠЎеҷЁжңҖеҗҺдёҖж¬Ўеҗ‘е®ғеҸ‘йҖҒ PING зҡ„ж—¶й—ҙгҖӮ
з”ЁжҲ·еҸҜд»ҘйҖҡиҝҮй…ҚзҪ®пјҢ жҢҮе®ҡзҪ‘з»ң延иҝҹзҡ„жңҖеӨ§еҖј min-slaves-max-lag пјҢ д»ҘеҸҠжү§иЎҢеҶҷж“ҚдҪңжүҖйңҖзҡ„иҮіе°‘д»ҺжңҚеҠЎеҷЁж•°йҮҸ min-slaves-to-write гҖӮ
еҰӮжһңиҮіе°‘жңү min-slaves-to-write дёӘд»ҺжңҚеҠЎеҷЁпјҢ 并且иҝҷдәӣжңҚеҠЎеҷЁзҡ„延иҝҹеҖјйғҪе°‘дәҺ min-slaves-max-lag з§’пјҢ йӮЈд№Ҳдё»жңҚеҠЎеҷЁе°ұдјҡжү§иЎҢе®ўжҲ·з«ҜиҜ·жұӮзҡ„еҶҷж“ҚдҪңгҖӮ
еҸҰдёҖж–№йқўпјҢ еҰӮжһңжқЎд»¶иҫҫдёҚеҲ° min-slaves-to-write е’Ң min-slaves-max-lag жүҖжҢҮе®ҡзҡ„жқЎд»¶пјҢ йӮЈд№ҲеҶҷж“ҚдҪңе°ұдёҚдјҡиў«жү§иЎҢпјҢ дё»жңҚеҠЎеҷЁдјҡеҗ‘иҜ·жұӮжү§иЎҢеҶҷж“ҚдҪңзҡ„е®ўжҲ·з«Ҝиҝ”еӣһдёҖдёӘй”ҷиҜҜгҖӮ
д»ҘдёӢжҳҜиҝҷдёӘзү№жҖ§зҡ„дёӨдёӘйҖүйЎ№е’Ңе®ғ们жүҖйңҖзҡ„еҸӮж•°пјҡ
min-slaves-to-write <number of slaves>
min-slaves-max-lag <number of seconds>
зңӢе®ҢдәҶиҝҷзҜҮж–Үз« пјҢзӣёдҝЎдҪ еҜ№Redisзҡ„жҢҒд№…еҢ–е’Ңдё»д»ҺеӨҚеҲ¶жңәеҲ¶жҳҜд»Җд№ҲжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ





