mysqlжҹҘиҜўж—¶пјҢoffsetиҝҮеӨ§еҪұе“ҚжҖ§иғҪжҖҺд№ҲеӨ„зҗҶ
жң¬ж–Үдё»иҰҒз»ҷеӨ§е®¶д»Ӣз»ҚmysqlжҹҘиҜўж—¶пјҢoffsetиҝҮеӨ§еҪұе“ҚжҖ§иғҪжҖҺд№ҲеӨ„зҗҶпјҢж–Үз« еҶ…е®№йғҪжҳҜ笔иҖ…з”Ёеҝғж‘ҳйҖүе’Ңзј–иҫ‘зҡ„пјҢе…·жңүдёҖе®ҡзҡ„й’ҲеҜ№жҖ§пјҢеҜ№еӨ§е®¶зҡ„еҸӮиҖғж„Ҹд№үиҝҳжҳҜжҜ”иҫғеӨ§зҡ„пјҢдёӢйқўи·ҹ笔иҖ…дёҖиө·дәҶи§ЈдёӢmysqlжҹҘиҜўж—¶пјҢoffsetиҝҮеӨ§еҪұе“ҚжҖ§иғҪжҖҺд№ҲеӨ„зҗҶеҗ§гҖӮ
еҮҶеӨҮжөӢиҜ•ж•°жҚ®иЎЁеҸҠж•°жҚ®
1.еҲӣе»әиЎЁ
CREATE TABLE `member` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL COMMENT '姓еҗҚ', `gender` tinyint(3) unsigned NOT NULL COMMENT 'жҖ§еҲ«', PRIMARY KEY (`id`), KEY `gender` (`gender`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.жҸ’е…Ҙ1000000жқЎи®°еҪ•
<?php
$pdo = new PDO("mysql:host=localhost;dbname=user","root",'');for($i=0; $i<1000000; $i++){ $name = substr(md5(time().mt_rand(000,999)),0,10); $gender = mt_rand(1,2); $sqlstr = "insert into member(name,gender) values('".$name."','".$gender."')"; $stmt = $pdo->prepare($sqlstr); $stmt->execute();}
?>mysql> select count(*) from member;
+----------+| count(*) |
+----------+| 1000000 |
+----------+1 row in set (0.23 sec)
3.еҪ“еүҚж•°жҚ®еә“зүҲжң¬
mysql> select version();
+-----------+| version() |
+-----------+| 5.6.24 |
+-----------+1 row in set (0.01 sec)

еҲҶжһҗoffsetиҝҮеӨ§еҪұе“ҚжҖ§иғҪзҡ„еҺҹеӣ
1.offsetиҫғе°Ҹзҡ„жғ…еҶө
mysql> select * from member where gender=1 limit 10,1;
+----+------------+--------+| id | name | gender |
+----+------------+--------+| 26 | 509e279687 | 1 |
+----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 100,1;
+-----+------------+--------+| id | name | gender |
+-----+------------+--------+| 211 | 07c4cbca3a | 1 |
+-----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 1000,1;
+------+------------+--------+| id | name | gender |
+------+------------+--------+| 1975 | e95b8b6ca1 | 1 |
+------+------------+--------+1 row in set (0.00 sec)
еҪ“offsetиҫғе°Ҹж—¶пјҢжҹҘиҜўйҖҹеәҰеҫҲеҝ«пјҢж•ҲзҺҮиҫғй«ҳгҖӮ
2.offsetиҫғеӨ§зҡ„жғ…еҶө
mysql> select * from member where gender=1 limit 100000,1;
+--------+------------+--------+| id | name | gender |
+--------+------------+--------+| 199798 | 540db8c5bc | 1 |
+--------+------------+--------+1 row in set (0.12 sec)mysql> select * from member where gender=1 limit 200000,1;
+--------+------------+--------+| id | name | gender |
+--------+------------+--------+| 399649 | 0b21fec4c6 | 1 |
+--------+------------+--------+1 row in set (0.23 sec)mysql> select * from member where gender=1 limit 300000,1;
+--------+------------+--------+| id | name | gender |
+--------+------------+--------+| 599465 | f48375bdb8 | 1 |
+--------+------------+--------+1 row in set (0.31 sec)
еҪ“offsetеҫҲеӨ§ж—¶пјҢдјҡеҮәзҺ°ж•ҲзҺҮй—®йўҳпјҢйҡҸзқҖoffsetзҡ„еўһеӨ§пјҢжү§иЎҢж•ҲзҺҮдёӢйҷҚгҖӮ
еҲҶжһҗеҪұе“ҚжҖ§иғҪеҺҹеӣ
select * from member where gender=1 limit 300000,1;
еӣ дёәж•°жҚ®иЎЁжҳҜInnoDBпјҢж №жҚ®InnoDBзҙўеј•зҡ„з»“жһ„пјҢжҹҘиҜўиҝҮзЁӢдёәпјҡ
йҖҡиҝҮдәҢзә§зҙўеј•жҹҘеҲ°дё»й”®еҖјпјҲжүҫеҮәжүҖжңүgender=1зҡ„id)гҖӮ
еҶҚж №жҚ®жҹҘеҲ°зҡ„дё»й”®еҖјйҖҡиҝҮдё»й”®зҙўеј•жүҫеҲ°зӣёеә”зҡ„ж•°жҚ®еқ—пјҲж №жҚ®idжүҫеҮәеҜ№еә”зҡ„ж•°жҚ®еқ—еҶ…е®№пјүгҖӮ
ж №жҚ®offsetзҡ„еҖјпјҢжҹҘиҜў300001ж¬Ўдё»й”®зҙўеј•зҡ„ж•°жҚ®пјҢжңҖеҗҺе°Ҷд№ӢеүҚзҡ„300000жқЎдёўејғпјҢеҸ–еҮәжңҖеҗҺ1жқЎгҖӮ
дёҚиҝҮ既然дәҢзә§зҙўеј•е·Із»ҸжүҫеҲ°дё»й”®еҖјпјҢдёәд»Җд№ҲиҝҳйңҖиҰҒе…Ҳз”Ёдё»й”®зҙўеј•жүҫеҲ°ж•°жҚ®еқ—пјҢеҶҚж №жҚ®offsetзҡ„еҖјеҒҡеҒҸ移еӨ„зҗҶе‘ўпјҹ
еҰӮжһңеңЁжүҫеҲ°дё»й”®зҙўеј•еҗҺпјҢе…Ҳжү§иЎҢoffsetеҒҸ移еӨ„зҗҶпјҢи·іиҝҮ300000жқЎпјҢеҶҚйҖҡиҝҮ第300001жқЎи®°еҪ•зҡ„дё»й”®зҙўеј•еҺ»иҜ»еҸ–ж•°жҚ®еқ—пјҢиҝҷж ·е°ұиғҪжҸҗй«ҳж•ҲзҺҮдәҶгҖӮ
еҰӮжһңжҲ‘们еҸӘжҹҘиҜўеҮәдё»й”®пјҢзңӢзңӢжңүд»Җд№ҲдёҚеҗҢ
mysql> select id from member where gender=1 limit 300000,1;
+--------+| id |
+--------+| 599465 |
+--------+1 row in set (0.09 sec)
еҫҲжҳҺжҳҫпјҢеҰӮжһңеҸӘжҹҘиҜўдё»й”®пјҢжү§иЎҢж•ҲзҺҮеҜ№жҜ”жҹҘиҜўе…ЁйғЁеӯ—ж®өпјҢжңүеҫҲеӨ§зҡ„жҸҗеҚҮгҖӮ
жҺЁжөӢ
еҸӘжҹҘиҜўдё»й”®зҡ„жғ…еҶө
еӣ дёәдәҢзә§зҙўеј•е·Із»ҸжүҫеҲ°дё»й”®еҖјпјҢиҖҢжҹҘиҜўеҸӘйңҖиҰҒиҜ»еҸ–дё»й”®пјҢеӣ жӯӨmysqlдјҡе…Ҳжү§иЎҢoffsetеҒҸ移ж“ҚдҪңпјҢеҶҚж №жҚ®еҗҺйқўзҡ„дё»й”®зҙўеј•иҜ»еҸ–ж•°жҚ®еқ—гҖӮ
йңҖиҰҒжҹҘиҜўжүҖжңүеӯ—ж®өзҡ„жғ…еҶө
еӣ дёәдәҢзә§зҙўеј•еҸӘжүҫеҲ°дё»й”®еҖјпјҢдҪҶе…¶д»–еӯ—ж®өзҡ„еҖјйңҖиҰҒиҜ»еҸ–ж•°жҚ®еқ—жүҚиғҪиҺ·еҸ–гҖӮеӣ жӯӨmysqlдјҡе…ҲиҜ»еҮәж•°жҚ®еқ—еҶ…е®№пјҢеҶҚжү§иЎҢoffsetеҒҸ移ж“ҚдҪңпјҢжңҖеҗҺдёўејғеүҚйқўйңҖиҰҒи·іиҝҮзҡ„ж•°жҚ®пјҢиҝ”еӣһеҗҺйқўзҡ„ж•°жҚ®гҖӮ
иҜҒе®һ
InnoDBдёӯжңүbuffer poolпјҢеӯҳж”ҫжңҖиҝ‘и®ҝй—®иҝҮзҡ„ж•°жҚ®йЎөпјҢеҢ…жӢ¬ж•°жҚ®йЎөе’Ңзҙўеј•йЎөгҖӮ
дёәдәҶжөӢиҜ•пјҢе…ҲжҠҠmysqlйҮҚеҗҜпјҢйҮҚеҗҜеҗҺжҹҘзңӢbuffer poolзҡ„еҶ…е®№гҖӮ
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
Empty set (0.04 sec)еҸҜд»ҘзңӢеҲ°пјҢйҮҚеҗҜеҗҺпјҢжІЎжңүи®ҝй—®иҝҮд»»дҪ•зҡ„ж•°жҚ®йЎөгҖӮ
жҹҘиҜўжүҖжңүеӯ—ж®өпјҢеҶҚжҹҘзңӢbuffer poolзҡ„еҶ…е®№
mysql> select * from member where gender=1 limit 300000,1;
+--------+------------+--------+| id | name | gender |
+--------+------------+--------+| 599465 | f48375bdb8 | 1 |
+--------+------------+--------+1 row in set (0.38 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
+------------+----------+| index_name | count(*) |
+------------+----------+| gender | 261 || PRIMARY | 1385 |
+------------+----------+2 rows in set (0.06 sec)еҸҜд»ҘзңӢеҮәпјҢжӯӨж—¶buffer poolдёӯе…ідәҺmemberиЎЁжңү1385дёӘж•°жҚ®йЎөпјҢ261дёӘзҙўеј•йЎөгҖӮ
йҮҚеҗҜmysqlжё…з©әbuffer poolпјҢ继з»ӯжөӢиҜ•еҸӘжҹҘиҜўдё»й”®
mysql> select id from member where gender=1 limit 300000,1;
+--------+| id |
+--------+| 599465 |
+--------+1 row in set (0.08 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
+------------+----------+| index_name | count(*) |
+------------+----------+| gender | 263 || PRIMARY | 13 |
+------------+----------+2 rows in set (0.04 sec)еҸҜд»ҘзңӢеҮәпјҢжӯӨж—¶buffer poolдёӯе…ідәҺmemberиЎЁеҸӘжңү13дёӘж•°жҚ®йЎөпјҢ263дёӘзҙўеј•йЎөгҖӮеӣ жӯӨеҮҸе°‘дәҶеӨҡж¬ЎйҖҡиҝҮдё»й”®зҙўеј•и®ҝй—®ж•°жҚ®еқ—зҡ„I/Oж“ҚдҪңпјҢжҸҗй«ҳжү§иЎҢж•ҲзҺҮгҖӮ
еӣ жӯӨеҸҜд»ҘиҜҒе®һпјҢmysqlжҹҘиҜўж—¶пјҢoffsetиҝҮеӨ§еҪұе“ҚжҖ§иғҪзҡ„еҺҹеӣ жҳҜеӨҡж¬ЎйҖҡиҝҮдё»й”®зҙўеј•и®ҝй—®ж•°жҚ®еқ—зҡ„I/Oж“ҚдҪңгҖӮпјҲжіЁж„ҸпјҢеҸӘжңүInnoDBжңүиҝҷдёӘй—®йўҳпјҢиҖҢMYISAMзҙўеј•з»“жһ„дёҺInnoDBдёҚеҗҢпјҢдәҢзә§зҙўеј•йғҪжҳҜзӣҙжҺҘжҢҮеҗ‘ж•°жҚ®еқ—зҡ„пјҢеӣ жӯӨжІЎжңүжӯӨй—®йўҳ пјүгҖӮ
InnoDBдёҺMyISAMеј•ж“Һзҙўеј•з»“жһ„еҜ№жҜ”еӣҫ
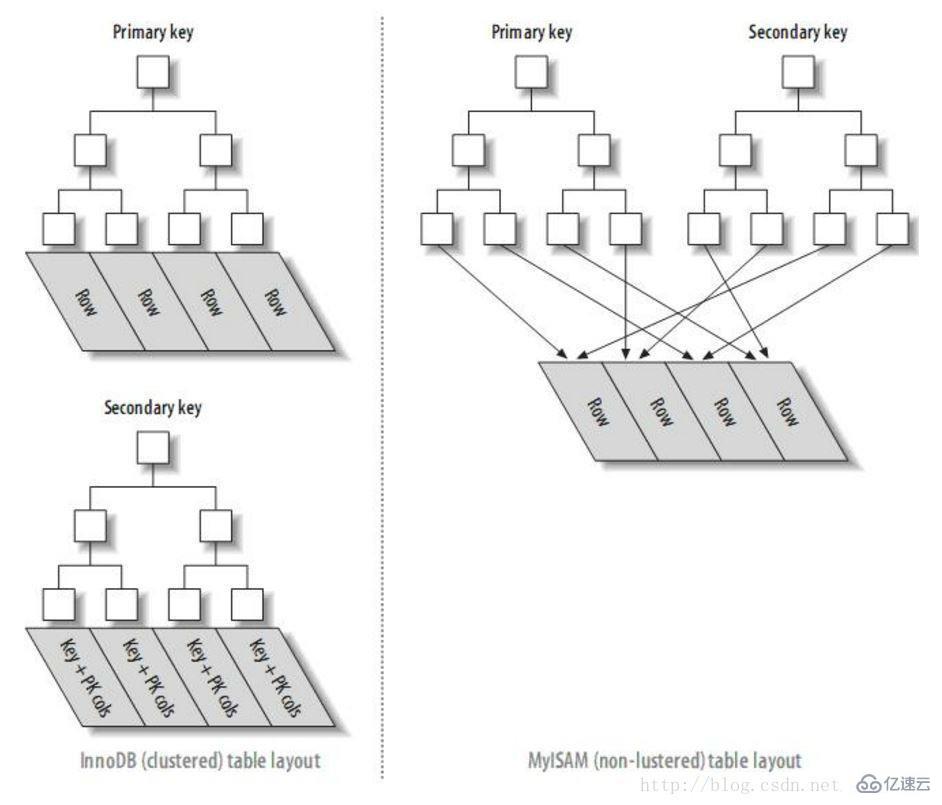
дјҳеҢ–ж–№жі•
ж №жҚ®дёҠйқўзҡ„еҲҶжһҗпјҢжҲ‘们зҹҘйҒ“жҹҘиҜўжүҖжңүеӯ—ж®өдјҡеҜјиҮҙдё»й”®зҙўеј•еӨҡж¬Ўи®ҝй—®ж•°жҚ®еқ—йҖ жҲҗзҡ„I/Oж“ҚдҪңгҖӮ
еӣ жӯӨжҲ‘们е…ҲжҹҘеҮәеҒҸ移еҗҺзҡ„дё»й”®пјҢеҶҚж №жҚ®дё»й”®зҙўеј•жҹҘиҜўж•°жҚ®еқ—зҡ„жүҖжңүеҶ…е®№еҚіеҸҜдјҳеҢ–гҖӮ
mysql> select a.* from member as a inner join (select id from member where gender=1 limit 300000,1) as b on a.id=b.id;
+--------+------------+--------+| id | name | gender |
+--------+------------+--------+| 599465 | f48375bdb8 | 1 |
+--------+------------+--------+1 row in set (0.08 sec)
зңӢе®Ңд»ҘдёҠе…ідәҺmysqlжҹҘиҜўж—¶пјҢoffsetиҝҮеӨ§еҪұе“ҚжҖ§иғҪжҖҺд№ҲеӨ„зҗҶпјҢеҫҲеӨҡиҜ»иҖ…жңӢеҸӢиӮҜе®ҡеӨҡе°‘жңүдёҖе®ҡзҡ„дәҶи§ЈпјҢеҰӮйңҖиҺ·еҸ–жӣҙеӨҡзҡ„иЎҢдёҡзҹҘиҜҶдҝЎжҒҜ пјҢеҸҜд»ҘжҢҒз»ӯе…іжіЁжҲ‘们зҡ„иЎҢдёҡиө„и®Ҝж Ҹзӣ®зҡ„гҖӮ





