小编给大家分享一下怎么使用XML化的思维组织数据,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
以往数据更多的通过人工录入,从专用网络协议的终端转移到“玻璃房子”里的大铁盒子,现在信息无所不在、无时不在,不过不一定都会汇总到您公司里,很多时候大家是在一个“平”的世界里分享数据,信息来源的渠道多了、信息本身的变化也更加频繁。不仅如此随着Web 2.0、Enterprise 2.0和Internet Service Bus等一系列概念的出现,您发现单单从自己的“玻璃房子”里找供货商提供的仓库地址远不如Google Map方便。
似乎以往桎梏数据的各种枷锁在互联网下被一一打破,但作为IT从业者,我们的工作是为用户提供它们所需的数据和他们希望获取信息的手段,因此应用必须能够经得起各种变化,包括以往我们关心的用户界面的变化、应用间调用的变化、应用内部逻辑的变化,还有步伐越来越快但又是最根本变化——数据自身的变化。
关系模型告诉我们要用二维表格描述信息世界,但这是太“不”自然不过了,看看手边的一本书或是家里的装修计划、马上要开工项目的任务分解,好像套到一个二维表格里总不合适,而且即便通过“实体——关系”生硬的削足适履后,在快速变化的环境下又总是要牵涉到“数据——应用——前端交互”一系列变动,而且经常是牵一发动全身。
似乎很多新一代应用已经找到了更适合新趋势的方案——XML,用一种更贴近我们自己思维的方式组织应用、组织用户体验。那么对于企业而言,组织数据这种相对基础性的工作是否也可以用XML的思维进行呢?应该可以。
数据实体以往总是被假设为应用中最为稳定的部分,无论我们用设计模式还是采用各种开源的开发框架(包括这些框架本身)都是尽量在适应应用本身变化的问题,那么现实的情况如何呢?
l 我们需要交换的数据实体经常要根据自身、合作方的需要变化;
l 合作方给我们的数据实体也常常变化;
l 随着SOA和Enterprise 2.0概念的推出,数据实体本身从多个源mash up出来,同时数据实体本身也被反复的拼装和组合;
l 随着业务的细化,我们自己的员工总是希望获取越来越丰富,同时也越来越详尽的信息;
因此,以往视需求也好、设计也好认为可以最早固定下来的数据实体在愈发敏捷的技术和业务现状前需要不断调整。为了适应这个要求我们可以自顶向下入手,不断调整应用自身的柔性;另一个方式是从“根”上处理这个问题,采用自身就可以不断适应这些变化的新数据模型,例如:XML数据模型和XML相关技术家族。
例如,定义用户实体的时候,最初下面的信息就够了,其中ICustomer是应用会使用的用户接口,而CUSTOMER为关系数据库方式下的表示,<Customer>为XML方式:
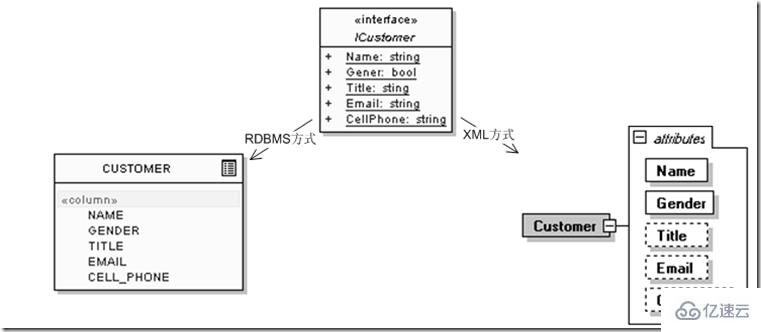
不过紧接着我们就发现这个实体设计有些问题,因为还要增加用户的办公室电话、住宅电话,还有可能1、2个电子邮件,他的MSN或Skype号码等。不考虑其他问题,仅仅从关系模型范1的要求,那么RDBMS和XML两个模型发展的结果就成了:
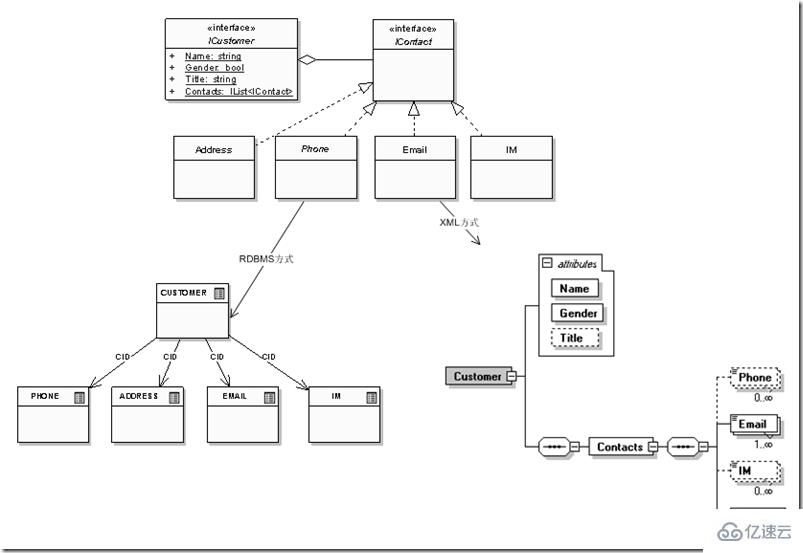
不难看出,虽然仅仅只是“客户”数据实体末节“联系信息”的一个变化,关系模型和XML模型在适应性方面就有非常大的区别,关系模型需要不断扩展出新的关系用来描述不断细化的数据实体,而XML模型自身的层次性可以提供变化条件下,自身的不断延伸和扩展。实际项目中,“学历情况”、“工作经验情况”等信息也存在类似的问题,关系模型下即便某位客户希望把某阶段工作情况的“借调”方式补充进去,也会发现因为设计上没有预留相应的字段,因此只好把它作为字符串“揉”在“工作单位”字段里,后面补充个“(借调)”,这等于僵化的数据模型本身抹杀了数据的业务语义中包括的信息;而层次模型可以把它作为一个子节点或属性来描述,这样不仅可以把关系模型下需要多个关系(客户、学历情况、工作经验、联系信息)集中在一个数据实体内部,而且可以把每个实体自身的扩展信息(例如“工作模式”:借调、交流、短期集中)等也描述在数据实体内部,同时从外部应用看“客户”实体本身依然是一个实体,这样用更贴近现实业务情景的数据实体才能更有效的适应外部变化。
上面我们讨论的仅仅是一个数据实体,进一步发展到具体业务领域模型模型的时候,往往需要同时综合多个数据实体协作完成业务功能,这时候情形又如何呢?比如:保单需要客户提供除了上述信息外的个人健康信息,子女、父母、伴侣家庭主要成员信息,同时会从其他从业机构获取用户的信用信息等,而且不同的数据实体组合主要用于企业内部的各异的应用领域,因此从数据使用角度看为了尽量让应用部分稳定,最好是数据实体稳定,但仅仅用户信息的联系方式部分就可能会反复的变化,如果让应用完全依赖这些变化因素组合后的结果,那么应用的稳定性确实难以保证,那么从源头上第一步先尽量保证不同应用尽量仅依赖于具体一个实体也许是有效改进的第一步,这时候XML的层次特性优势又显示出来了,比如我们可以根据不同的应用主题,自由组合这些信息:
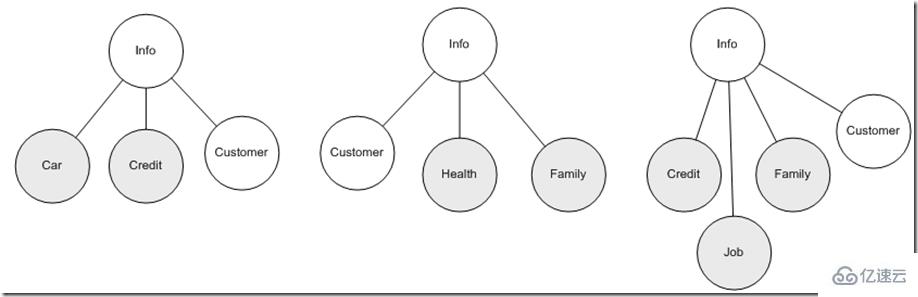
这样应用面对的就是一个统一的<info>实体,相应的采用专用的XML技术可以保证应用框架不变的情况下,新的业务可以动态响应变化的数据实体。
上面提的数据实体更多是在一个已经集中后的语境下讨论的,但除了概念上的设计外,使用中还有一个具体的问题就是如何如何把他们“聚集”到一起,这个一般通过数据集成实现。
(不过就像“架构”一词被过度滥用一样,“数据集成”同样被各个厂家根据自己的产品特征被定义成不同概念的组合,比如BI厂商力图把它描绘成ETL的代名词、提供数据交换平台的厂商描述为实现BizTalk Framework的产品、对于SOA产品公司而言,数据集成则更多在于如何保证在有效治理的前提下提供数据服务,另外对于一些厂商而已,数据集成还包括业务语义组合等。)
但作为用户,数据集成我们要着重关心什么问题呢?
l 数据实体的映射关系;
l 数据源的在各种交换协议、行业数据标准、安全控制约束下的互联;
l 数据交换过程的编排;
l 数据实体的验证和重构;
l 数据介质、数据载体的转换;
虽然理论上这些工作用编码完成不成问题,但随着企业集成逻辑越来越复杂且变化越来越快,修改代码即便可以应付一下1:N的集成,但如果经常是M:N的情况,那么就显得力不从心了。是否可以有更简化的办法呢?仅从“映射”的逻辑层次说:
l 面向对象思想告诉我们依赖倒置,要尽量依赖于抽象而不是具体,比如依赖于接口而非实体类型;
l 设计模式告诉我们,不兼容接口间适配器(Adapter)是个不错的途径;
那么数据领域是否也有类似的技术呢?XML Schema + XSLT也许就是个选择。
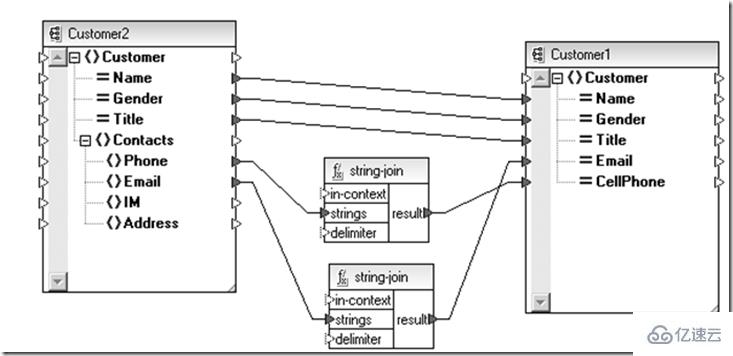
上面是为了兼容新、老用户实体做的转换,同样的如果需要进行上部分针对不同主体的数据实体聚合操作也完全可以借助在抽象数据定义(Schema)层次通过XSLT(Schema间的适配关系)完成。
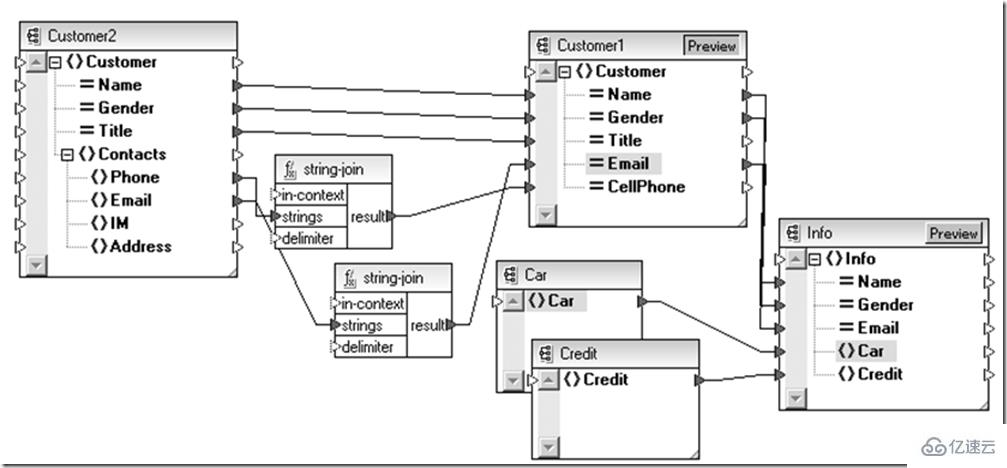
这样,我们可以在数据实体层次看到数据是如何聚合在一起的,但之前还需要解决一个问题:车辆信息、信用信息还有遗留系统的客户信息都是分别保存在关系数据库和合作方的Web Service中,如何连接起这个数据渠道呢?从现在看XML还是不错的选择。
不同数据介质上的数据可以以他们本源的形式提取,比如平文本、关系数据库、EDI报文或者是SOAP消息,通过不同的信息渠道传递到数据集成的汇聚点,然后根据目的数据源的需要,通过一个适配器转换异构的数据源。
这时候如果为每两种类型都设计一个点对点的适配器,整体规模将沿着N^2级的趋势发展,为此不妨先把他们统一为兼容这些信息的XML,然后用上面介绍的XSLT技术进行数据实体间的映射后,接着把XML再转换成目标数据源所需的形式,这样整个适配体系复杂度降为N级。
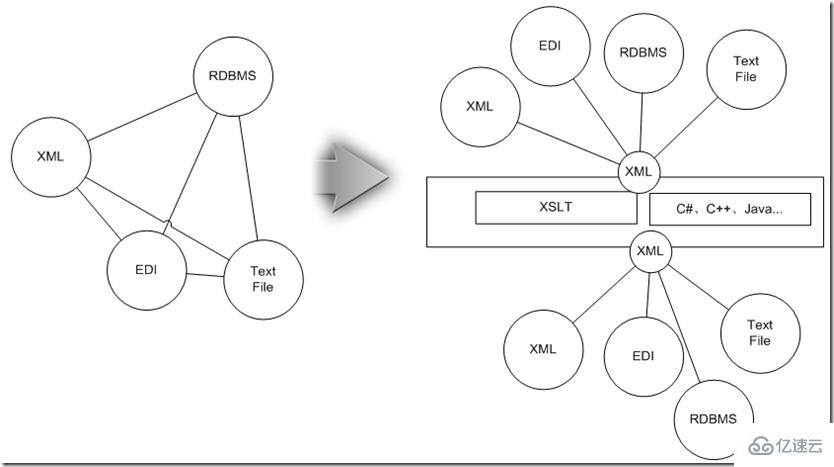
接着,我们看看XML技术如何满足只前提的那些数据集成要求:
l 数据实体的映射、数据介质、数据载体的转换、数据实体的验证和重构:
如上,先把数据统一转换为XML,然后通过XML层次型优势,结合XML专用技术进行处理。
l 数据源的在各种交换协议、行业数据标准、安全控制约束下的互联;
XML数据不仅可以跨越网络、防火墙,而且可以很容易的用于互联网环境(,不过您依然可以用消息队列方式把他们定义为报文),数据本身不会因为特殊的二进制操作需要受到交换协议的限制。当前,各个行业标准基本上都在使用XML描述自己的行业DM(Data Modal),即便您企业内部的系统本身数据实体由于数据库设计、历史遗留等问题,本身不是符合这些DM的数据,但各种XML数据统一治理的协议和标准可以比较方便的实现转换。对于安全性,似乎还有没比基于WS-*相关协议更适合于互联网环境下的安全标准家族,其中所有的标准无一例外都可以用XML实体定义数据和额外安全机制间的组合关系。
l 数据交换过程的编排;
对于同构系统环境,或者是仅仅基于兼容中间件系统的平台,可以采用遗留的工作流机制实现数据交换过程的编排,但为了适应服务化的时代,可以采用更通用的BPEL标准,此时XML不仅仅是数据,同时他也作为执行指令的形态出现,相比较一直标榜跨平台的Java技术而言,采用XML定义的交换过程更是跨语言的。
似乎集成已经解决了很大的问题,但一个显而易见的问题是所有的工作我们可能都要自己做一些实现,一步步告诉应用怎么做,那么当我们不再把Web仅仅当成“新鲜事物”,而把它考虑成一个服务于我们信息内容,并且可以交互的系统时,如何把这些散落的服务能力呈递给我们自己呢?这时候也许XML开放的元数据定义的优势才真正体现出来。
除去各种语义算法以外,如何让分散的各种繁多的服务聚合在一起为我们提供服务,其中XML一个非常关键的因素就是找到数据线索的主干,而且明确这条主干上实体间的关联关系及其逐步分解细化的过程。这个层次的数据不仅是被动由应用调用的对象,他们本身为应用共了进一步推断的支持。例如:
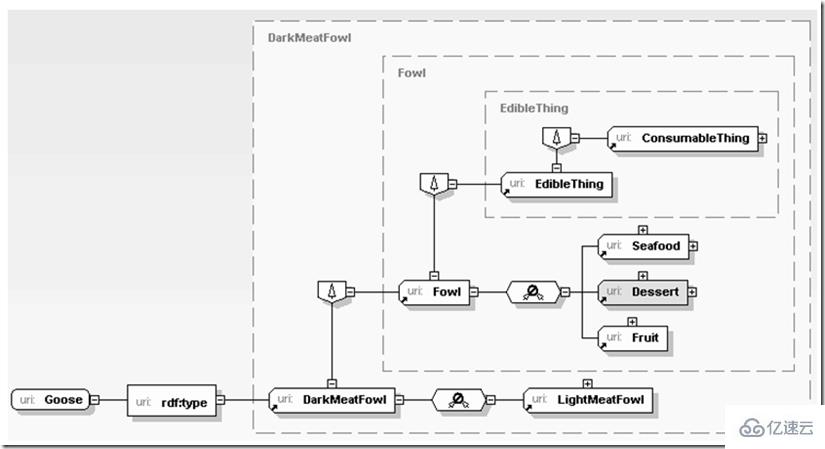
这里首先应用了解到当前处理的这个对象是鹅肉,由于鹅肉是一种黑肉,而黑肉是某种禽肉(fowl),禽肉可以食用,因此应用可以逐步推断鹅肉可以食用。上面的推断过程并不复杂,但如果用关系数据库实现却相对比较复杂,用平文本书写那就更难于实现了,试想一下如果同时把禽肉与蔬菜、甜点、海产品间的关系全部用关系数据库或文本书写,那实在太“难为”应用了。而XML不同,它可以很自然的贴近我们思维的习惯,以一种开放但又交织的办法描述我们熟悉的语义,无论是企业ERP环境的生产材料准备过程,还是为了一次生日Party准备自己下厨的采购计划,亦然。
以上是“怎么使用XML化的思维组织数据”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





