如何使用UTF-8对XML文档进行编码?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
Google的Sitemap服务要求发布的所有站点地图必须采用Unicode的UTF-8编码。Google甚至不允许其他Unicode编码(如UTF-16),更不用说ISO-8859-1这样的非Unicode编码了。从技术上说,这意味着Google使用的是非标准XML解析器,因为XML Recommendation特别要求“所有XML处理程序必须接受Unicode 3.1的UTF-8和UTF-16编码”,但这确实是一个大问题吗?
每个人都能使用UTF-8
普遍性是选择UTF-8的第一个也是最有说服力的理由。它可以处理目前世界上使用的每一种文字。虽然还有少数空白,但是越来越不明显,被逐渐填平了。没有纳入的文字通常也没有其他任何字符集实现过,即使有也不能在 XML 中使用。最好的情况下,这些文字通过字体借用转嫁到 Latin-1 这样的单字节字符集。对这类稀有文字的真正支持可能最先来自 Unicode,而且可能只有 Unicode 支持它们。
但这仅仅是使用 Unicode 的一个理由。为什么选择 UTF-8 而不是 UTF-16 或者其他 Unicode 编码呢?最直接的原因之一是广泛的工具支持。基本上所有可能用于 XML 的主要编辑器都能处理 UTF-8,包括 JEdit、BBEdit、Eclipse、emacs 甚至 Notepad。在 XML 和非 XML 工具中,没有其他 Unicode 编码拥有这样广泛的工具支持。
对于其中一些编辑器,如 BBEdit 和 Eclipse,UTF-8 并不是默认的字符集。现在有必要改变默认设置了,所有工具出厂的时候都应该选择 UTF-8 作为默认编码。除非这样,否则当文件跨越国界、平台和语言传递的时候,我们就会陷入不能互操作的泥潭。不过在所有程序都把 UTF-8 作为默认编码之前,自己修改默认设置也很容易。比如在 Eclipse 中,图 1 所示的“General/Editors”首选项面板允许指定所有文件都使用 UTF-8。您可能注意到 Eclipse 希望默认值为 MacRoman,但是如果这样,当把文件传递给使用 Microsoft® Windows® 的程序员或者美国和西欧之外的计算机时将无法编译。
图 1. 改变 Eclipse 的默认字符集
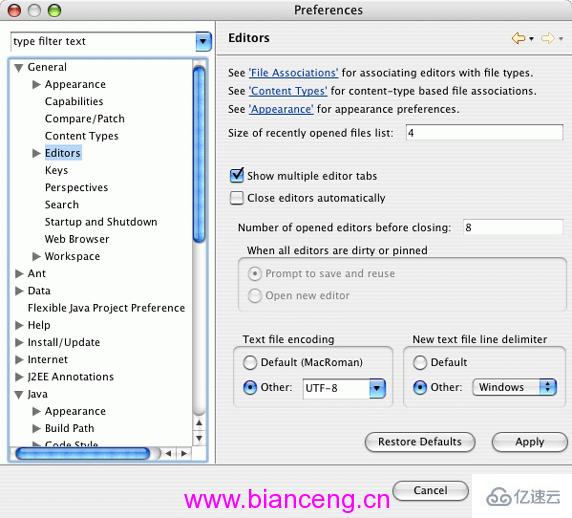
当然,要让 UTF-8 其作用,开发人员交换的文件也都必须使用 UTF-8,但这不成问题。与 MacRoman 不同,UTF-8 不局限于少数文字或者个别平台。任何人都能用 UTF-8。而 MacRoman、Latin-1、SJIS 和其他各种遗留的国家字符集都不能做到。
UTF-8 在不支持多字节数据的工具中也能正常工作。其他 Unicode 格式如 UTF-16 往往包含很多零字节。很多工具将这些字节解释为文件尾或者其他某种特殊的分界符,造成不希望的、未曾预料到的、常常是不愉快的结果。比方说,如果 UTF-16 数据原样加载到 C 字符串中,字符串可能从第一个 ASCII 字符的第二个字节截断。UTF-8 文件仅在确实表示 null 的地方包含 null。当然,不应该选择这么天真的工具来处理 XML 文档。但是,遗留系统中文档常常在奇怪的地方结束,没有人真正认识到或者理解那些字符序列仅仅是旧瓶装新酒。与 UTF-16 或其他 Unicode 编码相比,对于不支持 Unicode 和 XML 的系统,UTF-8 更不容易造成问题。
专家们的说法
XML 是第一个全面支持 UTF-8 的重要标准,但这仅仅是开始。各标准组织都在逐渐推荐 UTF-8。比如,包含非 ASCII 字符的 URL 是长期困扰 Web 的一个问题。在 PC 机上工作的包含非 ASCII 字符的 URL 不能用于 Mac,反之亦然。万维网联盟(W3C)和 Internet 工程任务组(IETF)最近同意所有 URL 都必须采用 UTF-8 编码而不能是其他编码,从而解决了这一问题。
W3C 和 IETF 对最先、最后还是偶尔使用 UTF-8 变得越来越强硬。The W3C Character Model for the World Wide Web 1.0: Fundamentals 指出,“如果必须选择一种字符编码,则必须是 UTF-8、UTF-16 或 UTF-32。US-ASCII 对 UTF-8 向上兼容(US-ASCII 字符串也是 UTF-8 字符串,参见 [RFC 3629]),因此如果需要与 US-ASCII 保持兼容,UTF-8 非常合适。”事实上,与 US-ASCII 兼容如此重要,几乎是必需的。W3C 明智地解释说,“其他情况下,如对于 API,UTF-16 或 UTF-32 可能更合适。选择一种编码的原因可能包括内部处理的效率以及与其他进程的互操作性。”
我同意内部处理的效率这条理由。比如,Java™ 语言中字符串的内部表示采用 UTF-16,因此对字符串的索引更快。不过,Java 代码永远不会把这种内部表示向与它交换数据的程序公开。相反,对于外部数据交换,要使用 java.io.Writer,明确地指定字符集。选择的时候,强烈推荐 UTF-8。
IETF 甚至更加明确。The IETF Charset Policy [RFC 2277] 指出,在没有不确定性的语言中:
协议必须能够使用 UTF-8 字符集,它由 ISO 10646 编码集和 UTF-8 字符编码方法组成,全文参见 [10646] Annex R(修正版 2 中发布)。
此外,协议可以规定如何使用其他 ISO 10646 字符集和字符编码方案,如 UTF-16,但是不能使用 UTF-8 是对本策略的违反,这种违反在进入或者提升到标准跟踪过程时,需要经过变更程序([BCP9] 第 9 节),并在协议规范文档中提出明确、可靠的理由。
现有的协议或者从已有数据存储转移数据的协议,可能需要支持其他数据集,甚至使用 UTF-8 之外的默认编码。这是允许的,但是必须能够支持 UTF-8。
要点:今后一段时间,对遗留协议和文件的支持可能要求接受 UTF-8 之外的字符集和编码,但是如果必须如此我会非常小心。每种新的协议、应用程序和文档都应该使用 UTF-8。
中文、日文和韩文
一种常见的误解是认为 UTF-8 是一种压缩格式。其实并非如此。与其他 Unicode 编码特别是 UTF-16 相比,在 UTF-8 中 ASCII 字符占用的空间只有一半。不过一些字符的 UTF-8 编码占用的空间要多出 50%,特别是中文、日文和韩文(CJK)这样的象形文字。
但即使用 UTF-8 编码 CJK XML,实际的大小可能也比 UTF-16 小。比如,中文的 XML 文档包含大量 ASCII 字符,如 <、>、&、=、"、' 和空格。这些字符的 UTF-8 编码要比 UTF-16 小。具体的压缩/膨胀因素因文档而异,但不论哪种情况,差别都不可能很明显。
最后,值得一提的是中文和日文这类象形文字,与 Latin、Cyrillic 这类字母文字相比,用字往往更少。由于字符的绝对量很大,要求每个字符使用三个或更多字节才能完全地表达这些文字,就是说,与英文或俄文相比,同样的词语或句子,这些语言可以用更少的字表达。比如,“tree”在日文中用“木”表示(非常像一棵树)。 用 UTF-8 表示需要三个字节,而英文单词“tree”包含四个字母,需要四个字节。日文中的“grove(小树林)”是“林”(两棵树靠在一起)。用 UTF-8 编码需要三个字节,而英文单词“grove”有五个字母,需要五个字节。日文中的“森”(三棵树)仍然需要三个字节。而对应的英文字“forest”需要六个字节。
如果确实需要压缩,则使用 zip 或 gzip。压缩后,UTF-8 和 UTF-16 的大小差不多,不论原始大小相差多少。无论哪种编码,原始大小越大,压缩算法去掉的冗余就更多。
健壮性
真正的优势在于设计,与以前和以后设计的其他任何文本编码相比,UTF-8 是一种更健壮、更容易解释的格式。首先,与 UTF-16 相比,UTF-8 没有 endianness 问题。UTF-8 用 Big-endian 和 little-endian 来表示都是一样的,因为 UTF-8 是按 8 位字节而不是 16 位字定义的。UTF-8 没有字节序的不确定性问题,后者必须通过字节序标志或其他试探手段来解决。
UTF-8 更重要的一个特征是无状态性。UTF-8 流或序列中的每个字节都是明确的。在 UTF-8 中总是可以知道所处的位置,就是说给定一个字节,马上就能确定它是一个单字节字符、双字节字符的第一个字节、双字节字符的第二个字节,或者三字节/四字节字符的第二个、第三个或第四个字节(当然还有其他可能性,但明白这个意思就行)。在 UTF-16 中,就不能确定字节“0x41”是不是字母“A”。有时候是,有时候不是。必须记录足够的状态才能确定在流中的位置。如果损失了一个字节,此后的数据就全部无法用了。在 UTF-8 中,丢失或者破坏的字节很容易确定,也不会影响其他数据。
UTF-8 并非是万能的。需要随机访问文档特定位置的应用程序使用 UCS2 或 UTF-32 这类固定宽度的编码可能操作起来更快。(如果考虑到替换对,UTF-16 是一种变长字符编码。)但是,XML 处理不属于这类应用程序。XML 规范特别要求解析器从 XML 文档的第一个字节开始解析直到最后一个字节,所有现有的解析器都是这样操作的。更快的随机访问对 XML 处理没有什么帮助,虽然对于数据库或其他系统使用不同的编码这可能是一个很好的理由,但不适用于 XML。
结束语
在越来越国际化的世界中,语言和政治边界日渐模糊,依赖于地域的字符集不再适用了。Unicode 是惟一能够跨越很多地域互操作的字符集。UTF-8 是最好的 Unicode 编码:
广泛的工具支持,包括与遗留 ASCII 系统最佳的兼容性。
处理起来简单而高效。
抗讹误。
平台独立。
该停止关于字符集和编码的争论了,选择 UTF-8,结束纷争。
看完上述内容,你们掌握如何使用UTF-8对XML文档进行编码的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





