[TOC]
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
在这里必须对比MapReduce,MapReduce最大的性能短板就在于shuffle过程中,会将中间结果输出到磁盘上(也就是hdfs上),这个过程中至少会产生6次的IO。也正是这些频繁的IO使得mr的性能不尽人意。
对于spark来说,中间结果是都在内存中的(checkpoint另说),就从这点来说,就少了很多IO导致的性能问题。当然这只是其中一点,后面会细说
与Hadoop的MapReduce相比,Spark基于内存的运算速度要快100倍以上,即使,Spark基于硬盘的运算也要快10倍。Spark实现了高效的DAG执行引擎,从而可以通过内存来高效处理数据流。
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
另外Spark还可以很好的融入Hadoop的体系结构中可以直接操作HDFS,并提供Hive on Spark、Pig on Spark的框架集成Hadoop。
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
Spark生态圈:
Spark Core :最重要,其中最重要的是 RDD (弹性分布式数据集)
Spark SQL :类似于Hive 使用SQL语句操作RDD DataFrame(表)
Spark Streaming : 流式计算
前面三个用到比较多,后面这两个看需求吧
Spark MLLib :Spark机器学习类库
Spark GraphX : 图计算
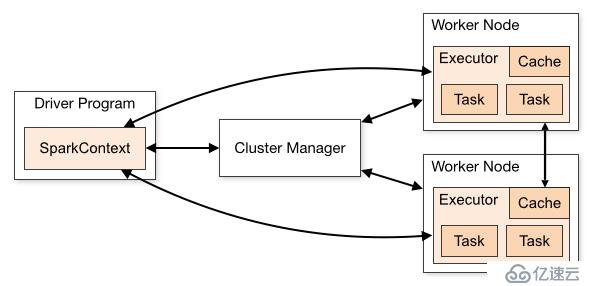
图2.1 spark架构
spark大致有几个大组件,分别为:driver、master(cluster manager)、worker。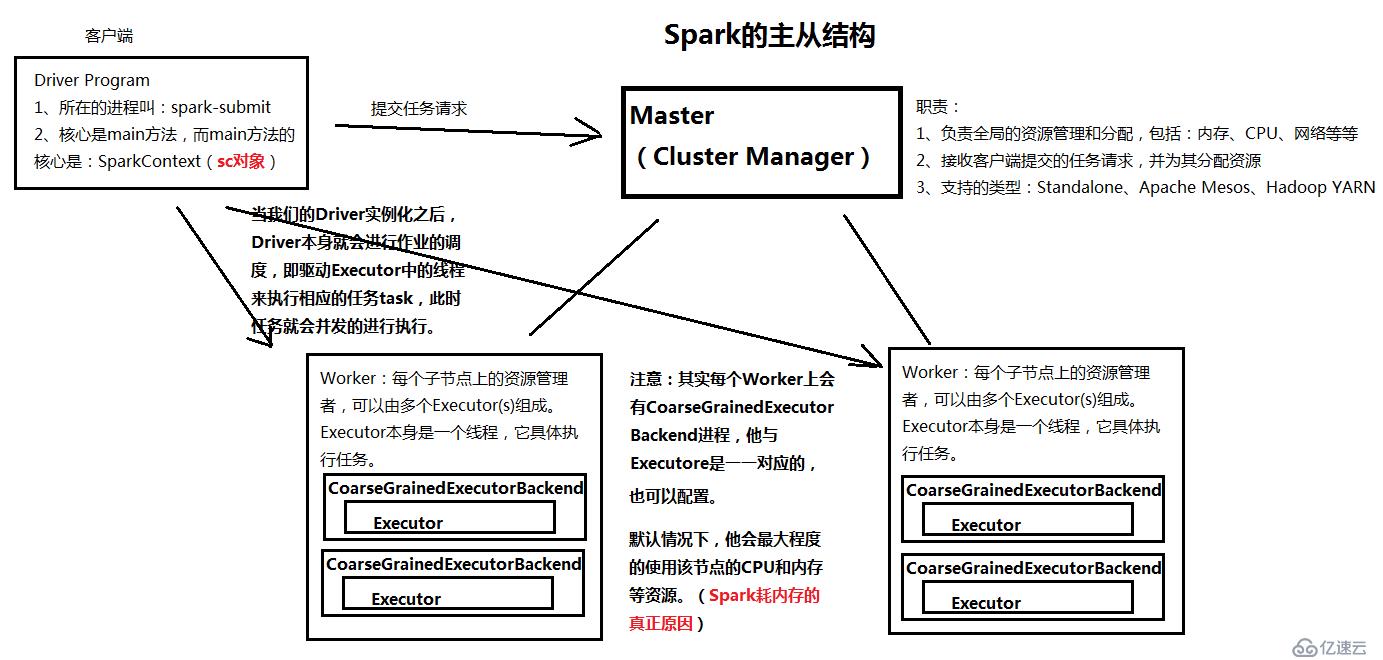
图2.2 spark工作任务图
上面这图说明了每个组件的功能。
spark可以部署在以上几种环境之上:
Standalone:spark内置的资源管理器
YARN:hadoop的资源管理器
Mesos
Amazon EC2
使用scala版本为scala2.11.8,spark版本为spark-2.1.0-bin-hadoop2.7。
jdk版本1.8,hadoop版本2.8.4
解压好spark程序之后,进入解压目录下。修改配置文件:
cd conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
添加以下内容:
export JAVA_HOME=/opt/modules/jdk1.8.0_144
# 指定master节点主机名以及端口
export SPARK_MASTER_HOST=bigdata121 这里自己按实际的ip改,为master节点
export SPARK_MASTER_PORT=7077
cp slaves.template slaves
vim slaves
# 配置从节点主机名,指定worker节点主机
bigdata121配置完成后,启动集群:
cd sbin
./start-all.sh
jps 查看是否有master和worker进程
20564 JobHistoryServer
127108 Jps
51927 Worker
41368 ResourceManager
11130 SecondaryNameNode
10875 NameNode
41467 NodeManager
51868 Master
10973 DataNode基本和伪分布式是一样的,也就是 conf/slaves文件中配置多几个worker节点而已,然后照样启动集群就OK了。
搭建完成了可以进入 http://masterIP:8080 查看集群状态
在spark中,master节点作为整个集群的管理者,是单点的,容易发生单点故障,所以为了保障master节点的可用性,需要给它实现HA
主要用于开发或测试环境。spark提供目录保存spark Application和worker的注册信息,并将他们的恢复状态信息写入该目录中,这时,一旦Master发生故障,就可以通过重新启动Master进程(sbin/start-master.sh),恢复已运行的spark Application和worker的注册信息。
基于文件系统的单点恢复,主要是在spark-env.sh里SPARK_DAEMON_JAVA_OPTS设置以下内容:
指定两个运行参数:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/root/training/spark-2.1.0-bin-hadoop2.7/recovery"
其中:
spark.deploy.recoveryMode=FILESYSTEM 设置为FILESYSTEM开启单点恢复功能,默认值:NONE
spark.deploy.recoveryDirectory Spark 保存恢复状态的目录要注意的是,这种方式本质上还是只有一个master节点,只不过是重启master节点时可以自动还原worker以及application信息,防止master挂了之后,所有任务都丢失执行状态,然后master重启之后需要重新从头到尾执行之前的任务。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到ZooKeeper,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。
这里分别用两台主机配置master节点,而worker节点仍然是单节点(为了方便起见而已)。首先需保证zookeeper服务的正常运行。这里不重复讲,可以看之前zookeeper的文章。这里直接讲spark 的配置。
修改spark-env.sh配置文件
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata121:2181,bigdata123:2181,bigdata122:2181 -Dspark.deploy.zookeeper.dir=/spark"
其中:
spark.deploy.recoveryMode=ZOOKEEPER 设置为ZOOKEEPER开启单点恢复功能,默认值:NONE
spark.deploy.zookeeper.url ZooKeeper集群的地址
spark.deploy.zookeeper.dir Spark信息在ZK中的保存目录,默认:/spark
另外:每个节点上,需要将以下两行注释掉
# export SPARK_MASTER_HOST=bigdata121
# export SPARK_MASTER_PORT=7077
会自动选出哪个是active的master节点地址以及端口,不需要指定。以上配置需要保证在整个spark集群的所有master和worker节点所在主机的配置一样。
配置完成后,启动集群
随便在一台master节点上启动整个集群:
sbin/start.all.sh
接着再另外一个master节点单独启动master:
sbin/start-master.sh启动完成后,可以到两个master的管理页面上看对应的状态:
http://masterip1:8080
http://masterip2:8080
如果正常工作的话,一般是一个显示active,一个显示standby接着我们看看zookeeper上存储什么信息:
会在zk上创建 /spark节点,有如下两个目录:
master_status 这个节点下有以worker名创建的子节点,也就是worker信息
leader_election 主备master节点所在主机的心跳信息,都是临时节点。如果失去心跳,那么就会对应的节点消失
如:
这个看节点名字就知道了,是worker的信息节点
[zk: localhost:2181(CONNECTED) 0] ls /spark/master_status
[worker_worker-20190822120853-192.168.50.121-59531]
这个则是两个master节点的的状态节点,如果没有心跳就消失了
[zk: localhost:2181(CONNECTED) 1] ls /spark/leader_election
[_c_dcc9ec86-80f9-4212-a5db-d1ec259add80-latch-0000000003, _c_fa42411d-0aa0-4da8-bbe9-483c198ee1f9-latch-0000000004]spark提供了一些实例程序,
[root@bigdata121 spark-2.1.0-bin-hadoop2.7]# ls examples/jars/
scopt_2.11-3.3.0.jar spark-examples_2.11-2.1.0.jarspark提供了两个工具用于提交执行spark任务,分别是spark-shell和spark-submit
一般用在生产环境中用于提交任务到集群中执行
例子:蒙特卡罗求PI
spark-submit --master spark://bigdata121:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 100
--master 指定master地址
--class 运行的类的全类名
Jar包位置
运行的类的main函数需要输入的参数(其实就是main函数中的args参数)
如果有多个额外的jar包,这样写:
submit --master xxx --jars jar1 jar2..... --class 全类名 包含运行类的jar包 参数
--jar 用于指定除了运行类之外的jar包地址,比如依赖的各种jar包
如果需要指定一些driver,比如mysql-connecter,需要加一个选项
--driver-class-path xxxx
或者方便一点的话就直接加到spark的jars目录下一般在生产环境中,在IDE中编写完spark程序后,会打包成jar包,然后上传到集群中。通过上面的spark-submit命令,将任务提交至集群中执行
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。一般用于测试
有两种运行模式:
(1)本地模式:不需要连接到Spark集群,在本地直接运行,用于测试
启动:bin/spark-shell 后面不写任何参数,代表本地模式
Spark context available as 'sc' (master = local[*], app id = local-1553936033811).
local代表本地模式
local[*] 表示cpu核数
(2)集群模式
命令:bin/spark-shell --master spark://.....
Spark context available as 'sc' (master = spark://node3:7077, app id = app-20190614091350-0000).
特殊说明:
Spark session 保存为 spark: Spark2.0以后提供的,利用session可以访问所有spark组件(core sql..)
spark context 保存为 sc,是任务的上下文对象。
spark sc 两个对象,可以直接使用例子:在Spark Shell中编写WordCount程序
程序如下:
sc.textFile("hdfs://bigdata121:9000/data/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://bigdata121:9000/output/spark/wc")
注意:hdfs://bigdata121:9000/data/data.txt上的文件需自行先上传到你的hdfs集群上,而且需保证输出目录不存在
说明:
sc是SparkContext对象,该对象时提交spark程序的入口
textFile("hdfs://bigdata121/data/data.txt")是hdfs中读取数据
flatMap(_.split(" "))先map在压平
map((_,1))将单词和1构成元组
reduceByKey(_+_)按照key进行reduce,并将value累加
saveAsTextFile("hdfs://bigdata121:9000/output/spark/wc")将结果写入到hdfs中首先需要idea配置好scala开发环境。
到插件中心安装scala插件。
创建maven工程,然后add framework support添加scala支持
到project structure添加scala源码文件夹
最后右键就可以看到可以创建scala class 的选项了。
注意:本地得安装scala以及jdk
配置好scala环境后,需要添加spark对应的maven依赖,添加依赖到pom.xml中:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>king</groupId>
<artifactId>sparkTest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.1.0</spark.version>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.7.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
<!--下面这是maven打包scala的插件,一定要,否则直接忽略scala代码-->
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>记住上面的关于build的配置千万不要漏掉。这里说说我之前的遇到的小坑。
小坑:
我用maven打包jar之后,到Linux上运行时,发现报错,说在jar包里找不到指定的主类。重新打包好几次都不行。接着我就到idea中将打包的jar添加为工程依赖,然后到jar包里看看有啥东西,结果发现我写的代码并没有打包到里面去。但是java的可以打包进去,我就猜测是maven直接忽略了scala代码,到网上一搜,需要加上上面的build配置,配置好就可以打包了。wordcount实例代码:
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//创建spark配置文件对象.设置app名称,master地址,local表示为本地模式。
//如果是提交到集群中,通常不指定。因为可能在多个集群汇上跑,写死不方便
val conf = new SparkConf().setAppName("wordCount").setMaster("local")
//创建spark context对象
val sc = new SparkContext(conf)
sc.textFile(args(0)).flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.saveAsTextFile(args(1))
}
}免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





