正文
与事务处理应用相比,大数据服务属于分析处理应用,由于两者的数据处理特点不同,因此容量估算方法也有一定的区别。
大数据服务通常要经过数据ETL、数据存储、数据分析、数据展示、数据开放的过程,因此在计算能力、存储能力以及网络能力的估算上也有自身的特点。
大数据服务在不同阶段对于基础设施的需求如图3-2-19所示:
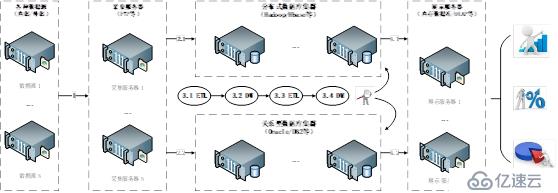
图3-2-19大数据服务不同阶段基础设施需求
从图3-2-19可以看出,对于一个普通的大数据项目,通常要经过数据采集(1)、数据存储和数据转换(2.1,2.2,3.1,3.2,3.3,3.4)、数据展示(4.1,4.2)三大步骤,具体处理过程为:
数据源分为内部和外部数据源两种。内部数据源是企业自身的数据,比如电信运营商的用户上网数据是从交换机获取的业务使用记录;
外部数据源是企业从外部获取的数据,比如移动终端配置数据是从第三方公司数据库获取的。采集数据的方式也分为主动和被动两种。
主动方式是主动去数据源抓取数据,比如可以通过网络爬虫在各大网站获取数据;被动方式是企业为数据源设定好存储位置,让数据提供方按照时间策略向指定位置存放数据。
企业可以根据数据特点不同采取不同的数据存储策略,如果数据规模大或者预期的数据规模大,传统的关系型数据库无法满足快速处理要求的,因而需要考虑采用分布式数据库,比如Hadoop/HBase。
类似Hadoop/HBase这样的分布式数据库的特点是扩展性好,如果存储空间不够,只需增加存储服务器即可。不足之处是HBase只适合单表或者多表之间关联关系简单的场景,对于需要数据操作或者多表关联的应用,还是需要基于关系型数据库实现。
关系型数据的优势就是能够对数据进行整合和统计,从而使得用户可以从多个维度来查看分析结果。当然,由于关系型数据库基于单机模式完成的架构设计,尽管也可以支持集群方式部署,但是横向扩展能力有限。
可见,多表关联查询要比键值映射方式对数据库管理系统的要求高,但是没有键值映射的方式扩展性好。
因此,在大数据存储时,需要结合应用需求和数据库存储特征来进行综合考量:使用分布式数据来存储数据规模大、增量大并且以数据查询为主的数据,采用关系型数据库完成需要多表关联的查询统计功能。
当原始数据存储到数据库中以后,需要对数据进行抽取、转换与加载,保证数据质量和应用要求。数据过程过程通常是经过初步的ETL,然后将数据存储数据仓库,接着再次对数据进行ETL,将数据加工成面向不同主题的数据集市,以便于从多个维度查看数据统计结果。
虽然已经经费了很大力气完成了数据的抽取、转换、丰富等工作,但是数据毕竟是给人看的,数据展示的越好,越容易让用户看到数据背后隐藏的事实和规律。
比如电信运营商为了查看各地区数据流量的多少,可以基于电子地图,不同数据流量区间用不同颜色标识,这样可以直观地看到各省数据流量的多寡。
大数据分析处理系统容量估算可以分为:理论估算法和实验估算法两种类型。
理论估算法的数据基础包括文件数、单个文件数的记录条数、单条记录大小、数据采集周期,数据采集周期包括一次、一天、一个月等,这样就能够算出某个时间段内的总数据量大小。然后在考虑磁盘的冗余空间系数,就可以算出对于磁盘空间总的需求量。理论估算法适合于没有样本数据的场景。
理论估算法的计算公式为:存储空间大小 = 文件个数单个文件记录数单条记录大小时间长度冗余系数。
实验估算法基于某个时间段的样本数据。用户可以用操作系统自带的命令查看文件大小。如果进入数据仓库的数据从时间上是连续的,则可以通过样本数据测量值与时间长度相乘,算出大数据分析处理系统存储空间需求。
实验估算法的计算公式为:大数据分析处理系统存储空间大小 = 样本数据量大小时间长度冗余系数。
传统数据处理与存储架构是“主机+磁盘阵列”的集群方式,主机可以是小机、PC服务器或者刀片服务器,磁盘阵列可以是NAS、SAN等,采用的协议可以是FC、IP等。
传统数据处理与存储架构解决了存储资源和计算资源的共享问题。多个服务器组成的集群可以将计算资源统一管理,接收请求的负载均衡器会根据服务器负荷将请求发送到计算资源充足的服务器。
磁盘阵列实现共享的方式更加容易理解,就是多个磁盘放到一个机箱中,机箱可以扩展并且机箱内可以热插拔磁盘,这样可以便于扩展磁盘空间。
“主机+磁盘阵列”的系统架构是将计算和存储分离,通过计算群和存储群的方式提高了并行处理能力,满足了高并发的事务处理应用的系统要求,但是这种架构也带来了新的问题,就是计算和存储资源的横向扩展能力是有限的。
大数据服务的特点是数据量大,尤其是随着时间的推移,数据量会不断增大,要求计算和存储资源能够具备几乎没有限制的扩展能力。
为了满足不断增加的数据量,谷歌公司提出了基于MapReduce和GFS的分布式计算架构,与“主机+磁盘阵列”的架构方式不同,谷歌公司利用廉价的机器设备,通过软件将能力不一的大量计算机设备连接到一起,降低了IT基础设施采购成本,提升了IT基础设施的扩展能力。随后,Apache受谷歌的GFS/MapReduce架构的启发,提出了Hadoop分布式计算架构。
可见,新型的面向大数据的分布式计算架构与“主机+磁盘阵列”的系统架构在设计思路上完全不同的,大数据计算能力估算的方法也是不同的。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





