RedisеҒ¶еҸ‘иҝһжҺҘеӨұиҙҘжҖҺд№ҲеҠһ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶRedisеҒ¶еҸ‘иҝһжҺҘеӨұиҙҘжҖҺд№ҲеҠһпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
еүҚиЁҖ
жң¬ж–Үдё»иҰҒз»ҷеӨ§е®¶д»Ӣз»ҚдәҶе…ідәҺRedisеҒ¶еҸ‘иҝһжҺҘеӨұиҙҘзҡ„зӣёе…іеҶ…е®№пјҢеҲҶдә«еҮәжқҘдҫӣеӨ§е®¶еҸӮиҖғеӯҰд№ пјҢдёӢйқўиҜқдёҚеӨҡиҜҙдәҶпјҢжқҘдёҖиө·зңӢзңӢиҜҰз»Ҷзҡ„д»Ӣз»Қеҗ§
гҖҗдҪңиҖ…гҖ‘
еј е»¶дҝҠпјҡжҗәзЁӢжҠҖжңҜдҝқйҡңдёӯеҝғиө„ж·ұDBAпјҢеҜ№ж•°жҚ®еә“жһ¶жһ„е’Ңз–‘йҡҫй—®йўҳеҲҶжһҗжҺ’жҹҘжңүжө“еҺҡзҡ„е…ҙи¶ЈгҖӮ
еҜҝеҗ‘жҷЁпјҡжҗәзЁӢжҠҖжңҜдҝқйҡңдёӯеҝғй«ҳзә§DBAпјҢдё»иҰҒиҙҹиҙЈжҗәзЁӢRedisеҸҠDBзҡ„иҝҗз»ҙе·ҘдҪңпјҢеңЁиҮӘеҠЁеҢ–иҝҗз»ҙпјҢжөҒзЁӢеҢ–еҸҠзӣ‘жҺ§жҺ’йҡңзӯүж–№йқўжңүиҫғеӨҡзҡ„е®һи·өз»ҸйӘҢпјҢе–ңж¬ўж·ұе…ҘеҲҶжһҗй—®йўҳпјҢжҸҗй«ҳеӣўйҳҹиҝҗз»ҙж•ҲзҺҮгҖӮ
гҖҗй—®йўҳжҸҸиҝ°гҖ‘
вҖӮз”ҹдә§зҺҜеўғжңүдёҖдёӘRedisдјҡеҒ¶е°”еҸ‘з”ҹиҝһжҺҘеӨұиҙҘзҡ„жҠҘй”ҷпјҢжҠҘй”ҷзҡ„ж—¶й—ҙзӮ№гҖҒе®ўжҲ·з«ҜIP并没жңүзү№еҲ«жҳҺжҳҫзҡ„规еҫӢпјҢиҝҮдёҖдјҡе„ҝпјҢжҠҘй”ҷдјҡиҮӘеҠЁжҒўеӨҚгҖӮ
вҖӮд»ҘдёӢжҳҜе®ўжҲ·з«ҜжҠҘй”ҷдҝЎжҒҜпјҡ
CRedis.Client.RExceptions.ExcuteCommandException: Unable to Connect redis server: ---> CRedis.Third.Redis.RedisException: Unable to Connect redis server:
еңЁ CRedis.Third.Redis.RedisNativeClient.CreateConnectionError()
еңЁ CRedis.Third.Redis.RedisNativeClient.SendExpectData(Byte[][] cmdWithBinaryArgs)
еңЁ CRedis.Client.Entities.RedisServer.<>c__DisplayClassd`1.
вҖӮд»ҺжҠҘй”ҷзҡ„дҝЎжҒҜжқҘзңӢпјҢеә”иҜҘжҳҜиҝһжҺҘдёҚдёҠRedisжүҖиҮҙгҖӮRedisзҡ„зүҲжң¬жҳҜ2.8.19гҖӮиҷҪ然зүҲжң¬жңүзӮ№иҖҒпјҢдҪҶеҹәжң¬иҝҗиЎҢзЁіе®ҡгҖӮ
вҖӮзәҝдёҠзҺҜеўғеҸӘжңүиҝҷдёӘйӣҶзҫӨжңүеҒ¶е°”жҠҘй”ҷгҖӮиҝҷдёӘйӣҶзҫӨзҡ„дёҖдёӘжҜ”иҫғжҳҺжҳҫзҡ„зү№еҫҒжҳҜе®ўжҲ·з«ҜжңҚеҠЎеҷЁжҜ”иҫғеӨҡпјҢжңүдёҠзҷҫеҸ°гҖӮ
гҖҗй—®йўҳеҲҶжһҗгҖ‘
вҖӮд»ҺжҠҘй”ҷзҡ„дҝЎжҒҜжқҘзңӢпјҢе®ўжҲ·з«ҜиҝһжҺҘдёҚеҲ°жңҚеҠЎз«ҜгҖӮеёёи§Ғзҡ„еҺҹеӣ жңүд»ҘдёӢеҮ зӮ№пјҡ
дёҖдёӘеёёи§Ғзҡ„еҺҹеӣ жҳҜз”ұдәҺз«ҜеҸЈиҖ—е°ҪпјҢеҜ№зҪ‘з»ңиҝһжҺҘиҝӣиЎҢжҺ’жҹҘпјҢеңЁеҮәй—®йўҳзҡ„зӮ№дёҠпјҢTCPиҝһжҺҘж•°иҝңжІЎжңүиҫҫеҲ°з«ҜеҸЈиҖ—е°Ҫзҡ„еңәжҷҜпјҢеӣ жӯӨиҝҷдёӘдёҚжҳҜRedisиҝһжҺҘдёҚдёҠзҡ„ж №жң¬еҺҹеӣ гҖӮ
еҸҰеӨ–дёҖз§Қеёёи§Ғзҡ„еңәжҷҜжҳҜеңЁжңҚеҠЎз«Ҝжңүж…ўжҹҘиҜўпјҢеҜјиҮҙRedisжңҚеҠЎйҳ»еЎһгҖӮжҲ‘们еңЁRedisжңҚеҠЎз«ҜпјҢжҠҠиҝҗиЎҢи¶…иҝҮ10жҜ«з§’зҡ„иҜӯеҸҘиҝӣиЎҢжҠ“еҸ–пјҢд№ҹжІЎжңүжҠ“еҲ°иҝҗиЎҢж…ўзҡ„иҜӯеҸҘгҖӮ
вҖӮд»ҺжңҚеҠЎз«Ҝзҡ„йғЁзҪІзҡ„зӣ‘жҺ§жқҘзңӢпјҢеҮәй—®йўҳзҡ„зӮ№дёҠпјҢиҝһжҺҘж•°жңүдёҖдёӘзӘҒ然йЈҷеҚҮпјҢд»Һ3500дёӘиҝһжҺҘзӘҒ然йЈҷеҚҮиҮі4100дёӘиҝһжҺҘгҖӮеҰӮдёӢеӣҫжҳҫзӨәпјҡ
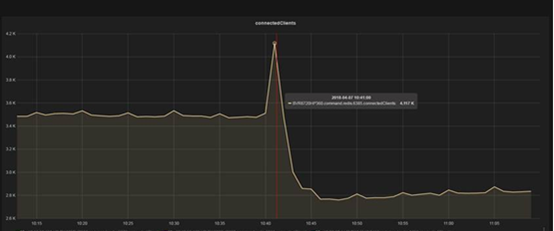
еҗҢж—¶й—ҙпјҢжңҚеҠЎеҷЁз«ҜжҳҫзӨәRedisжңҚеҠЎз«ҜжңүдёўеҢ…зҺ°иұЎпјҡ345539 вҖ“ 344683 = 856дёӘеҢ…гҖӮ
Sat Apr 7 10:41:40 CST 2018
1699 outgoing packets dropped
92 dropped because of missing route
344683 SYNs to LISTEN sockets dropped
344683 times the listen queue of a socket overflowed
Sat Apr 7 10:41:41 CST 2018
1699 outgoing packets dropped
92 dropped because of missing route
345539 SYNs to LISTEN sockets dropped
345539 times the listen queue of a socket overflowed
вҖӮе®ўжҲ·з«ҜжҠҘй”ҷзҡ„еҺҹеӣ еҹәжң¬зЎ®е®ҡпјҢжҳҜеӣ дёәе»әиҝһйҖҹеәҰеӨӘеҝ«пјҢеҜјиҮҙжңҚеҠЎз«ҜbacklogйҳҹеҲ—жәўеҮәпјҢиҝһжҺҘиў«serverз«ҜresetгҖӮ
гҖҗе…ідәҺbacklog overflowгҖ‘
вҖӮеңЁй«ҳ并еҸ‘зҡ„зҹӯиҝһжҺҘжңҚеҠЎдёӯпјҢиҝҷжҳҜдёҖз§ҚеҫҲеёёи§Ғзҡ„tcpжҠҘй”ҷзұ»еһӢгҖӮдёҖдёӘжӯЈеёёзҡ„tcpе»әиҝһиҝҮзЁӢеҰӮдёӢпјҡ
вҖӮ1.clientеҸ‘йҖҒдёҖдёӘ(SYN)з»ҷserver
вҖӮ2.serverиҝ”еӣһдёҖдёӘ(SYN,ACK)з»ҷclient
вҖӮ3.clientиҝ”еӣһдёҖдёӘ(ACK)
вҖӮдёүж¬ЎжҸЎжүӢз»“жқҹпјҢеҜ№clientжқҘиҜҙе»әиҝһжҲҗеҠҹпјҢclientеҸҜд»Ҙ继з»ӯеҸ‘йҖҒж•°жҚ®еҢ…з»ҷserverпјҢдҪҶжҳҜиҝҷдёӘж—¶еҖҷserverз«ҜжңӘеҝ…readyпјҢеҰӮдёӢеӣҫжүҖзӨә пјҡ

еңЁBSDзүҲжң¬еҶ…ж ёе®һзҺ°зҡ„tcpеҚҸи®®дёӯпјҢserverз«Ҝе»әиҝһиҝҮзЁӢйңҖиҰҒдёӨдёӘйҳҹеҲ—пјҢдёҖдёӘжҳҜSYN queueпјҢдёҖдёӘжҳҜaccept queueгҖӮеүҚиҖ…еҸ«еҚҠејҖиҝһжҺҘпјҲжҲ–иҖ…еҚҠиҝһжҺҘпјүйҳҹеҲ—пјҢеңЁжҺҘ收еҲ°clientеҸ‘йҖҒзҡ„SYNж—¶еҠ е…ҘйҳҹеҲ—гҖӮпјҲдёҖз§Қеёёи§Ғзҡ„зҪ‘з»ңж”»еҮ»ж–№ејҸе°ұжҳҜдёҚж–ӯеҸ‘йҖҒSYNдҪҶжҳҜдёҚеҸ‘йҖҒACKд»ҺиҖҢеҜјиҮҙserverз«Ҝзҡ„еҚҠејҖйҳҹеҲ—ж’‘зҲҶпјҢserverз«ҜжӢ’з»қжңҚеҠЎгҖӮпјүеҗҺиҖ…еҸ«е…ЁиҝһжҺҘйҳҹеҲ—пјҢserverиҝ”еӣһ(SYN,ACK)пјҢеңЁжҺҘ收еҲ°clientеҸ‘йҖҒACKеҗҺпјҲжӯӨж—¶clientдјҡи®Өдёәе»әиҝһе·Із»Ҹе®ҢжҲҗпјҢдјҡејҖе§ӢеҸ‘йҖҒPSHеҢ…пјүпјҢеҰӮжһңaccept queueжІЎжңүж»ЎпјҢйӮЈд№Ҳserverд»ҺSYN queueжҠҠиҝһжҺҘдҝЎжҒҜ移еҲ°accept queueпјӣеҰӮжһңжӯӨж—¶accept queueжәўеҮәзҡ„иҜқпјҢserverзҡ„иЎҢдёәиҰҒзңӢй…ҚзҪ®гҖӮеҰӮжһңtcp_abort_on_overflowдёә0пјҲй»ҳи®ӨпјүпјҢйӮЈд№ҲзӣҙжҺҘdropжҺүclientеҸ‘йҖҒзҡ„PSHеҢ…пјҢжӯӨж—¶clientдјҡиҝӣе…ҘйҮҚеҸ‘иҝҮзЁӢпјҢдёҖж®өж—¶й—ҙеҗҺserverз«ҜйҮҚж–°еҸ‘йҖҒSYN,ACKпјҢйҮҚж–°д»Һе»әиҝһзҡ„第дәҢжӯҘејҖе§ӢпјӣеҰӮжһңtcp_abort_on_overflowдёә1пјҢйӮЈд№Ҳserverз«ҜеҸ‘зҺ°accept queueж»Ўд№ӢеҗҺзӣҙжҺҘеҸ‘йҖҒresetгҖӮ
йҖҡиҝҮwiresharkжҗңзҙўеҸ‘зҺ°еңЁдёҖз§’еҶ…жңүи¶…иҝҮ2000ж¬ЎеҜ№Redis Serverз«ҜеҸ‘иө·е»әиҝһиҜ·жұӮгҖӮжҲ‘们е°қиҜ•дҝ®ж”№tcp backlogеӨ§е°ҸпјҢд»Һ511и°ғж•ҙеҲ°2048, й—®йўҳ并没жңүеҫ—еҲ°и§ЈеҶігҖӮжүҖд»ҘжӯӨзұ»еҫ®и°ғпјҢ并дёҚиғҪеҪ»еә•зҡ„и§ЈеҶій—®йўҳгҖӮ
гҖҗзҪ‘з»ңеҢ…еҲҶжһҗгҖ‘
жҲ‘们用wiresharkжқҘиҜҶеҲ«зҪ‘з»ңжӢҘеЎһзҡ„еҮҶзЎ®ж—¶й—ҙзӮ№е’ҢеҺҹеӣ гҖӮжҲ‘们已з»ҸжңүдәҶеҮҶзЎ®зҡ„жҠҘй”ҷж—¶й—ҙзӮ№пјҢе…Ҳз”ЁeditcapжҠҠи¶…еӨ§зҡ„tcpеҢ…иЈҒеүӘдёҖдёӢпјҢиЈҒжҲҗ30з§’й—ҙйҡ”пјҢ并йҖҡиҝҮwireshark I/O 100msй—ҙйҡ”еҲҶжһҗзҪ‘з»ңйҳ»еЎһзҡ„еҮҶзЎ®ж—¶й—ҙзӮ№пјҡ

вҖӮж №жҚ®еӣҫж ҮеҸҜд»ҘжҳҺжҳҫзңӢеҲ°tcpзҡ„packetsжқҘеҫҖеӯҳеңЁblockгҖӮ
вҖӮеҜ№иҜҘblockеүҚеҗҺзҡ„зҪ‘з»ңеҢ…иҝӣиЎҢжҳҺз»ҶеҲҶжһҗпјҢзҪ‘з»ңеҢ…жқҘеҫҖжғ…еҶөеҰӮдёӢпјҡ
| Time | Source | Dest | Description |
|---|
| вҖӮвҖӮ12:01:54.6536050вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰAPвҖҰ |
| вҖӮвҖӮ12:01:54.6538580вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰAPвҖҰ |
| вҖӮвҖӮ12:01:54.6539770вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰAPвҖҰ |
| вҖӮвҖӮ12:01:54.6720580вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰA..S.. |
| вҖӮвҖӮ12:01:54.6727200вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰAвҖҰвҖҰ |
| вҖӮвҖӮ12:01:54.6808480вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰAPвҖҰ.. |
| вҖӮвҖӮ12:01:54.6910840вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰAвҖҰS., |
| вҖӮвҖӮ12:01:54.6911950вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰAвҖҰвҖҰ |
| вҖӮвҖӮвҖҰ вҖӮвҖӮ | вҖӮвҖӮвҖҰ вҖӮвҖӮ | вҖӮвҖӮ вҖҰ вҖӮвҖӮ | вҖӮвҖӮ вҖҰ |
| вҖӮвҖӮ12:01:56.1181350вҖӮвҖӮ | вҖӮвҖӮRedis-ServerвҖӮвҖӮ | вҖӮвҖӮClientsвҖӮвҖӮ | вҖӮвҖӮTCP:Flags=вҖҰAPвҖҰ. |
12:01:54.6808480, Redis Serverз«Ҝеҗ‘е®ўжҲ·з«ҜеҸ‘йҖҒдәҶдёҖдёӘPushеҢ…пјҢд№ҹе°ұжҳҜеҜ№дәҺжҹҘиҜўиҜ·жұӮзҡ„дёҖдёӘз»“жһңиҝ”еӣһгҖӮеҗҺйқўзҡ„еҢ…йғҪжҳҜеңЁеҒҡиҝһжҺҘеӨ„зҗҶпјҢеҢ…жӢ¬AckеҢ…пјҢAckзЎ®и®ӨеҢ…пјҢд»ҘеҸҠйҮҚзҪ®зҡ„RSTеҢ…пјҢзҙ§жҺҘзқҖдёӢйқўдёҖдёӘPushеҢ…жҳҜеңЁ12:01:56.1181350еҸ‘еҮәзҡ„гҖӮдёӯй—ҙзҡ„й—ҙйҡ”жҳҜ1.4372870з§’гҖӮд№ҹе°ұжҳҜиҜҙпјҢеңЁиҝҷ1.4372870з§’жңҹй—ҙпјҢRedisзҡ„жңҚеҠЎеҷЁз«ҜпјҢйҷӨдәҶеҒҡдёҖдёӘжҹҘиҜўпјҢе…¶д»–зҡ„ж“ҚдҪңйғҪжҳҜеңЁеҒҡе»әиҝһпјҢжҲ–жӢ’з»қиҝһжҺҘгҖӮ
е®ўжҲ·з«ҜжҠҘй”ҷзҡ„еүҚеҗҺйҖ»иҫ‘е·Із»Ҹжё…жҘҡдәҶпјҢredis-serverеҚЎдәҶ1.43з§’пјҢclientзҡ„connection poolиў«жү“ж»ЎпјҢз–ҜзӢӮж–°е»әиҝһжҺҘпјҢserverзҡ„accept queueж»ЎпјҢзӣҙжҺҘжӢ’з»қжңҚеҠЎпјҢclientжҠҘй”ҷгҖӮејҖе§ӢжҖҖз–‘clientеҸ‘йҖҒдәҶзү№ж®Ҡе‘Ҫд»ӨпјҢиҝҷж—¶йңҖиҰҒзЎ®и®ӨдёҖдёӢclientзҡ„жңҖеҗҺеҮ дёӘе‘Ҫд»ӨжҳҜд»Җд№ҲпјҢжүҫеҲ°redis-serverеҚЎжӯ»еүҚзҡ„第дёҖдёӘеҢ…пјҢиЈ…дёҖдёӘwiresharkзҡ„redisжҸ’件пјҢзңӢеҲ°жңҖеҗҺеҮ дёӘе‘Ҫд»ӨжҳҜз®ҖеҚ•зҡ„getпјҢ并且key-valueйғҪеҫҲе°ҸпјҢдёҚиҮідәҺйңҖиҰҒиҖ—иҙ№1.43з§’жүҚиғҪе®ҢжҲҗгҖӮжңҚеҠЎз«Ҝд№ҹжІЎжңүslow logпјҢжӯӨж—¶жҺ’йҡңеҶҚж¬Ўйҷ·е…ҘеғөеұҖгҖӮ
гҖҗиҝӣдёҖжӯҘеҲҶжһҗгҖ‘
дёәдәҶдәҶи§Јиҝҷ1.43з§’д№ӢеҶ…пјҢRedis ServerеңЁеҒҡд»Җд№ҲдәӢжғ…пјҢжҲ‘们用pstackжқҘжҠ“еҸ–дҝЎжҒҜгҖӮPstackжң¬иҙЁдёҠжҳҜgdb attach. й«ҳйў‘зҺҮзҡ„жҠ“еҸ–дјҡеҪұе“Қredisзҡ„еҗһеҗҗгҖӮжӯ»еҫӘзҺҜ0.5з§’дёҖж¬Ўж— и„‘жҠ“пјҢеңЁredis-serverеҚЎжӯ»зҡ„ж—¶еҖҷжҠ“еҲ°е Ҷж ҲеҰӮдёӢ(иҝҮж»ӨдәҶжІЎз”Ёзҡ„ж ҲдҝЎжҒҜ)пјҡ
Thu May 31 11:29:18 CST 2018
Thread 1 (Thread 0x7ff2db6de720 (LWP 8378)):
#0 0x000000000048cec4 in ?? ()
#1 0x00000000004914a4 in je_arena_ralloc ()
#2 0x00000000004836a1 in je_realloc ()
#3 0x0000000000422cc5 in zrealloc ()
#4 0x00000000004213d7 in sdsRemoveFreeSpace ()
#5 0x000000000041ef3c in clientsCronResizeQueryBuffer ()
#6 0x00000000004205de in clientsCron ()
#7 0x0000000000420784 in serverCron ()
#8 0x0000000000418542 in aeProcessEvents ()
#9 0x000000000041873b in aeMain ()
#10 0x0000000000420fce in main ()
Thu May 31 11:29:19 CST 2018
Thread 1 (Thread 0x7ff2db6de720 (LWP 8378)):
#0 0x0000003729ee5407 in madvise () from /lib64/libc.so.6
#1 0x0000000000493a4e in je_pages_purge ()
#2 0x000000000048cf70 in ?? ()
#3 0x00000000004914a4 in je_arena_ralloc ()
#4 0x00000000004836a1 in je_realloc ()
#5 0x0000000000422cc5 in zrealloc ()
#6 0x00000000004213d7 in sdsRemoveFreeSpace ()
#7 0x000000000041ef3c in clientsCronResizeQueryBuffer ()
#8 0x00000000004205de in clientsCron ()
#9 0x0000000000420784 in serverCron ()
#10 0x0000000000418542 in aeProcessEvents ()
#11 0x000000000041873b in aeMain ()
#12 0x0000000000420fce in main ()
Thu May 31 11:29:19 CST 2018
Thread 1 (Thread 0x7ff2db6de720 (LWP 8378)):
#0 0x000000000048108c in je_malloc_usable_size ()
#1 0x0000000000422be6 in zmalloc ()
#2 0x00000000004220bc in sdsnewlen ()
#3 0x000000000042c409 in createStringObject ()
#4 0x000000000042918e in processMultibulkBuffer ()
#5 0x0000000000429662 in processInputBuffer ()
#6 0x0000000000429762 in readQueryFromClient ()
#7 0x000000000041847c in aeProcessEvents ()
#8 0x000000000041873b in aeMain ()
#9 0x0000000000420fce in main ()
Thu May 31 11:29:20 CST 2018
Thread 1 (Thread 0x7ff2db6de720 (LWP 8378)):
#0 0x000000372a60e7cd in write () from /lib64/libpthread.so.0
#1 0x0000000000428833 in sendReplyToClient ()
#2 0x0000000000418435 in aeProcessEvents ()
#3 0x000000000041873b in aeMain ()
#4 0x0000000000420fce in main ()
йҮҚеӨҚеӨҡж¬ЎжҠ“еҸ–еҗҺпјҢд»Һе Ҷж ҲдёӯеҸ‘зҺ°еҸҜз–‘е Ҷж ҲclientsCronResizeQueryBufferдҪҚзҪ®пјҢеұһдәҺserverCron()еҮҪж•°дёӢпјҢиҝҷдёӘredis-serverеҶ…йғЁзҡ„е®ҡж—¶и°ғеәҰпјҢ并дёҚеңЁз”ЁжҲ·зәҝзЁӢдёӢпјҢиҝҷдёӘи§ЈйҮҠдәҶдёәд»Җд№ҲеҚЎжӯ»зҡ„ж—¶еҖҷжІЎжңүеҮәзҺ°ж…ўжҹҘиҜўгҖӮ
жҹҘзңӢredisжәҗз ҒпјҢзЎ®и®ӨеҲ°еә•redis-serverеңЁеҒҡд»Җд№Ҳпјҡ
clientsCron(server.h):
#define CLIENTS_CRON_MIN_ITERATIONS 5
void clientsCron(void) {
/* Make sure to process at least numclients/server.hz of clients
* per call. Since this function is called server.hz times per second
* we are sure that in the worst case we process all the clients in 1
* second. */
int numclients = listLength(server.clients);
int iterations = numclients/server.hz;
mstime_t now = mstime();
/* Process at least a few clients while we are at it, even if we need
* to process less than CLIENTS_CRON_MIN_ITERATIONS to meet our contract
* of processing each client once per second. */
if (iterations < CLIENTS_CRON_MIN_ITERATIONS)
iterations = (numclients < CLIENTS_CRON_MIN_ITERATIONS) ?
numclients : CLIENTS_CRON_MIN_ITERATIONS;
while(listLength(server.clients) && iterations--) {
client *c;
listNode *head;
/* Rotate the list, take the current head, process.
* This way if the client must be removed from the list it's the
* first element and we don't incur into O(N) computation. */
listRotate(server.clients);
head = listFirst(server.clients);
c = listNodeValue(head);
/* The following functions do different service checks on the client.
* The protocol is that they return non-zero if the client was
* terminated. */
if (clientsCronHandleTimeout(c,now)) continue;
if (clientsCronResizeQueryBuffer(c)) continue;
}
}clientsCronйҰ–е…ҲеҲӨж–ӯеҪ“еүҚclientзҡ„ж•°йҮҸпјҢз”ЁдәҺжҺ§еҲ¶дёҖж¬Ўжё…зҗҶиҝһжҺҘзҡ„ж•°йҮҸпјҢз”ҹдә§жңҚеҠЎеҷЁеҚ•е®һдҫӢзҡ„иҝһжҺҘж•°йҮҸеңЁ5000дёҚеҲ°пјҢд№ҹе°ұжҳҜдёҖж¬Ўжё…зҗҶзҡ„иҝһжҺҘж•°жҳҜ50дёӘгҖӮ
clientsCronResizeQueryBuffer(server.h):
/* The client query buffer is an sds.c string that can end with a lot of
* free space not used, this function reclaims space if needed.
*
* The function always returns 0 as it never terminates the client. */
int clientsCronResizeQueryBuffer(client *c) {
size_t querybuf_size = sdsAllocSize(c->querybuf);
time_t idletime = server.unixtime - c->lastinteraction;
/* еҸӘеңЁд»ҘдёӢдёӨз§Қжғ…еҶөдёӢдјҡResize query buffer:
* 1) Query buffer > BIG_ARG(еңЁserver.h дёӯе®ҡд№ү#define PROTO_MBULK_BIG_ARG (1024*32))
дё”иҝҷдёӘBufferзҡ„е°ҸдәҺдёҖж®өж—¶й—ҙзҡ„е®ўжҲ·з«ҜдҪҝз”Ёзҡ„еі°еҖј.
* 2) е®ўжҲ·з«Ҝз©әй—Іи¶…иҝҮ2sдё”Buffer sizeеӨ§дәҺ1k. */
if (((querybuf_size > PROTO_MBULK_BIG_ARG) &&
(querybuf_size/(c->querybuf_peak+1)) > 2) ||
(querybuf_size > 1024 && idletime > 2))
{
/* Only resize the query buffer if it is actually wasting space. */
if (sdsavail(c->querybuf) > 1024) {
c->querybuf = sdsRemoveFreeSpace(c->querybuf);
}
}
/* Reset the peak again to capture the peak memory usage in the next
* cycle. */
c->querybuf_peak = 0;
return 0;
}еҰӮжһңredisClientеҜ№иұЎзҡ„query bufferж»Ўи¶іжқЎд»¶пјҢйӮЈд№Ҳе°ұзӣҙжҺҘresizeжҺүгҖӮж»Ўи¶іжқЎд»¶зҡ„иҝһжҺҘеҲҶжҲҗдёӨз§ҚпјҢдёҖз§ҚжҳҜзңҹзҡ„еҫҲеӨ§зҡ„пјҢжҜ”иҜҘе®ўжҲ·з«ҜдёҖж®өж—¶й—ҙеҶ…дҪҝз”Ёзҡ„еі°еҖјиҝҳеӨ§пјӣиҝҳжңүдёҖз§ҚжҳҜеҫҲй—ІпјҲidle>2пјүзҡ„пјҢиҝҷдёӨз§ҚйғҪиҰҒж»Ўи¶ідёҖдёӘжқЎд»¶пјҢе°ұжҳҜbuffer freeзҡ„йғЁеҲҶи¶…иҝҮ1kгҖӮйӮЈд№Ҳredis-serverеҚЎдҪҸзҡ„еҺҹеӣ е°ұжҳҜжӯЈеҘҪжңүйӮЈд№Ҳ50дёӘеҫҲеӨ§зҡ„жҲ–иҖ…з©әй—Ізҡ„并且free sizeи¶…иҝҮдәҶ1kеӨ§е°ҸиҝһжҺҘзҡ„еҗҢж—¶еҫӘзҺҜеҒҡдәҶresizeпјҢз”ұдәҺredisйғҪеұһдәҺеҚ•зәҝзЁӢе·ҘдҪңзҡ„зЁӢеәҸпјҢжүҖд»ҘblockдәҶclientгҖӮйӮЈд№Ҳи§ЈеҶіиҝҷдёӘй—®йўҳеҠһжі•е°ұеҫҲжҳҺжң—дәҶпјҢи®©resize зҡ„йў‘зҺҮеҸҳдҪҺжҲ–иҖ…resizeзҡ„жү§иЎҢйҖҹеәҰеҸҳеҝ«гҖӮ
既然问йўҳеҮәеңЁquery bufferдёҠпјҢжҲ‘们е…ҲзңӢдёҖдёӢиҝҷдёӘдёңиҘҝиў«дҝ®ж”№зҡ„дҪҚзҪ®пјҡ
readQueryFromClientпјҲnetworking.cпјү:
redisClient *createClient(int fd) {
redisClient *c = zmalloc(sizeof(redisClient));
/* passing -1 as fd it is possible to create a non connected client.
* This is useful since all the Redis commands needs to be executed
* in the context of a client. When commands are executed in other
* contexts (for instance a Lua script) we need a non connected client. */
if (fd != -1) {
anetNonBlock(NULL,fd);
anetEnableTcpNoDelay(NULL,fd);
if (server.tcpkeepalive)
anetKeepAlive(NULL,fd,server.tcpkeepalive);
if (aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c) == AE_ERR)
{
close(fd);
zfree(c);
return NULL;
}
}
selectDb(c,0);
c->id = server.next_client_id++;
c->fd = fd;
c->name = NULL;
c->bufpos = 0;
c->querybuf = sdsempty(); еҲқе§ӢеҢ–жҳҜ0
readQueryFromClient(networking.c):
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
redisClient *c = (redisClient*) privdata;
int nread, readlen;
size_t qblen;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
server.current_client = c;
readlen = REDIS_IOBUF_LEN;
/* If this is a multi bulk request, and we are processing a bulk reply
* that is large enough, try to maximize the probability that the query
* buffer contains exactly the SDS string representing the object, even
* at the risk of requiring more read(2) calls. This way the function
* processMultiBulkBuffer() can avoid copying buffers to create the
* Redis Object representing the argument. */
if (c->reqtype == REDIS_REQ_MULTIBULK && c->multibulklen && c->bulklen != -1
&& c->bulklen >= REDIS_MBULK_BIG_ARG)
{
int remaining = (unsigned)(c->bulklen+2)-sdslen(c->querybuf);
if (remaining < readlen) readlen = remaining;
}
qblen = sdslen(c->querybuf);
if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen); еңЁиҝҷйҮҢдјҡиў«жү©еӨ§з”ұжӯӨеҸҜи§Ғc->querybufеңЁиҝһжҺҘ第дёҖж¬ЎиҜ»еҸ–е‘Ҫд»ӨеҗҺзҡ„еӨ§е°Ҹе°ұдјҡиў«еҲҶй…ҚиҮіе°‘1024*32пјҢжүҖд»ҘеӣһиҝҮеӨҙеҶҚеҺ»зңӢresizeзҡ„жё…зҗҶйҖ»иҫ‘е°ұжҳҺжҳҫеӯҳеңЁй—®йўҳпјҢжҜҸдёӘиў«дҪҝз”ЁеҲ°зҡ„query bufferзҡ„еӨ§е°ҸиҮіе°‘е°ұжҳҜ1024*32пјҢдҪҶжҳҜжё…зҗҶзҡ„ж—¶еҖҷеҲӨж–ӯжқЎд»¶жҳҜ>1024пјҢд№ҹе°ұжҳҜиҜҙпјҢжүҖжңүзҡ„idle>2зҡ„иў«дҪҝз”ЁиҝҮзҡ„иҝһжҺҘйғҪдјҡиў«resizeжҺүпјҢдёӢж¬ЎжҺҘ收еҲ°иҜ·жұӮзҡ„ж—¶еҖҷеҶҚйҮҚж–°еҲҶй…ҚеҲ°1024*32пјҢиҝҷдёӘе…¶е®һжҳҜжІЎжңүеҝ…иҰҒзҡ„пјҢеңЁи®ҝй—®жҜ”иҫғйў‘з№Ғзҡ„зҫӨйӣҶпјҢеҶ…еӯҳдјҡиў«йў‘з№Ғеҫ—еӣһ收йҮҚеҲҶй…ҚпјҢжүҖд»ҘжҲ‘们е°қиҜ•е°Ҷжё…зҗҶзҡ„еҲӨж–ӯжқЎд»¶ж”№йҖ дёәеҰӮдёӢпјҢе°ұеҸҜд»ҘйҒҝе…ҚеӨ§йғЁеҲҶжІЎжңүеҝ…иҰҒзҡ„resizeж“ҚдҪңпјҡ
if (((querybuf_size > REDIS_MBULK_BIG_ARG) &&
(querybuf_size/(c->querybuf_peak+1)) > 2) ||
(querybuf_size > 1024*32 && idletime > 2))
{
/* Only resize the query buffer if it is actually wasting space. */
if (sdsavail(c->querybuf) > 1024*32) {
c->querybuf = sdsRemoveFreeSpace(c->querybuf);
}
}иҝҷдёӘж”№йҖ зҡ„еүҜдҪңз”ЁжҳҜеҶ…еӯҳзҡ„ејҖй”ҖпјҢжҢүз…§дёҖдёӘе®һдҫӢ5kиҝһжҺҘи®Ўз®—пјҢ5000*1024*32=160MпјҢиҝҷзӮ№еҶ…еӯҳж¶ҲиҖ—еҜ№дәҺдёҠзҷҫGеҶ…еӯҳзҡ„жңҚеҠЎеҷЁе®Ңе…ЁеҸҜд»ҘжҺҘеҸ—гҖӮ
гҖҗй—®йўҳйҮҚзҺ°гҖ‘
еңЁдҪҝз”Ёдҝ®ж”№иҝҮжәҗз Ғзҡ„Redis serverеҗҺпјҢй—®йўҳд»Қ然йҮҚзҺ°дәҶпјҢе®ўжҲ·з«ҜиҝҳжҳҜдјҡжҠҘеҗҢзұ»еһӢзҡ„й”ҷиҜҜпјҢдё”жҠҘй”ҷзҡ„ж—¶еҖҷпјҢжңҚеҠЎеҷЁеҶ…еӯҳдҫқ然дјҡеҮәзҺ°жҠ–еҠЁгҖӮжҠ“еҸ–еҶ…еӯҳе Ҷж ҲдҝЎжҒҜеҰӮдёӢпјҡ
Thu Jun 14 21:56:54 CST 2018
#3 0x0000003729ee893d in clone () from /lib64/libc.so.6
Thread 1 (Thread 0x7f2dc108d720 (LWP 27851)):
#0 0x0000003729ee5400 in madvise () from /lib64/libc.so.6
#1 0x0000000000493a1e in je_pages_purge ()
#2 0x000000000048cf40 in arena_purge ()
#3 0x00000000004a7dad in je_tcache_bin_flush_large ()
#4 0x00000000004a85e9 in je_tcache_event_hard ()
#5 0x000000000042c0b5 in decrRefCount ()
#6 0x000000000042744d in resetClient ()
#7 0x000000000042963b in processInputBuffer ()
#8 0x0000000000429762 in readQueryFromClient ()
#9 0x000000000041847c in aeProcessEvents ()
#10 0x000000000041873b in aeMain ()
#11 0x0000000000420fce in main ()
Thu Jun 14 21:56:54 CST 2018
Thread 1 (Thread 0x7f2dc108d720 (LWP 27851)):
#0 0x0000003729ee5400 in madvise () from /lib64/libc.so.6
#1 0x0000000000493a1e in je_pages_purge ()
#2 0x000000000048cf40 in arena_purge ()
#3 0x00000000004a7dad in je_tcache_bin_flush_large ()
#4 0x00000000004a85e9 in je_tcache_event_hard ()
#5 0x000000000042c0b5 in decrRefCount ()
#6 0x000000000042744d in resetClient ()
#7 0x000000000042963b in processInputBuffer ()
#8 0x0000000000429762 in readQueryFromClient ()
#9 0x000000000041847c in aeProcessEvents ()
#10 0x000000000041873b in aeMain ()
#11 0x0000000000420fce in main ()
жҳҫ然пјҢQuerybufferиў«йў‘з№Ғresizeзҡ„й—®йўҳе·Із»Ҹеҫ—еҲ°дәҶдјҳеҢ–пјҢдҪҶжҳҜиҝҳжҳҜдјҡеҮәзҺ°е®ўжҲ·з«ҜжҠҘй”ҷгҖӮиҝҷе°ұеҸҲйҷ·е…ҘдәҶеғөеұҖгҖӮйҡҫйҒ“иҝҳжңүе…¶д»–еӣ зҙ еҜјиҮҙquery buffer resizeеҸҳж…ўпјҹжҲ‘们еҶҚж¬ЎжҠ“еҸ–pstackгҖӮдҪҶиҝҷж—¶пјҢjemallocеј•иө·дәҶжҲ‘们зҡ„жіЁж„ҸгҖӮжӯӨж—¶еӣһжғіRedisзҡ„еҶ…еӯҳеҲҶй…ҚжңәеҲ¶пјҢRedisдёәйҒҝе…ҚlibcеҶ…еӯҳдёҚиў«йҮҠж”ҫеҜјиҮҙеӨ§йҮҸеҶ…еӯҳзўҺзүҮзҡ„й—®йўҳпјҢй»ҳи®ӨдҪҝз”Ёзҡ„жҳҜjemallocз”ЁдҪңеҶ…еӯҳеҲҶй…Қз®ЎзҗҶпјҢиҝҷж¬ЎжҠҘй”ҷзҡ„е Ҷж ҲдҝЎжҒҜдёӯйғҪжҳҜje_pages_purge () redisеңЁи°ғз”Ёjemallocеӣһ收и„ҸйЎөгҖӮжҲ‘们зңӢдёӢjemallocеҒҡдәҶдәӣд»Җд№Ҳпјҡ
arena_purge(arena.c)
static void
arena_purge(arena_t *arena, bool all)
{
arena_chunk_t *chunk;
size_t npurgatory;
if (config_debug) {
size_t ndirty = 0;
arena_chunk_dirty_iter(&arena->chunks_dirty, NULL,
chunks_dirty_iter_cb, (void *)&ndirty);
assert(ndirty == arena->ndirty);
}
assert(arena->ndirty > arena->npurgatory || all);
assert((arena->nactive >> opt_lg_dirty_mult) < (arena->ndirty -
arena->npurgatory) || all);
if (config_stats)
arena->stats.npurge++;
npurgatory = arena_compute_npurgatory(arena, all);
arena->npurgatory += npurgatory;
while (npurgatory > 0) {
size_t npurgeable, npurged, nunpurged;
/* Get next chunk with dirty pages. */
chunk = arena_chunk_dirty_first(&arena->chunks_dirty);
if (chunk == NULL) {
arena->npurgatory -= npurgatory;
return;
}
npurgeable = chunk->ndirty;
assert(npurgeable != 0);
if (npurgeable > npurgatory && chunk->nruns_adjac == 0) {
arena->npurgatory += npurgeable - npurgatory;
npurgatory = npurgeable;
}
arena->npurgatory -= npurgeable;
npurgatory -= npurgeable;
npurged = arena_chunk_purge(arena, chunk, all);
nunpurged = npurgeable - npurged;
arena->npurgatory += nunpurged;
npurgatory += nunpurged;
}
}JemallocжҜҸж¬Ўеӣһ收йғҪдјҡеҲӨж–ӯжүҖжңүе®һйҷ…еә”иҜҘжё…зҗҶзҡ„chunck并еҜ№жё…зҗҶеҒҡcountпјҢиҝҷдёӘж“ҚдҪңеҜ№дәҺй«ҳе“Қеә”иҰҒжұӮзҡ„зі»з»ҹжҳҜеҫҲеҘўдҫҲзҡ„пјҢжүҖд»ҘжҲ‘们иҖғиҷ‘йҖҡиҝҮеҚҮзә§jemallocзҡ„зүҲжң¬жқҘдјҳеҢ–purgeзҡ„жҖ§иғҪгҖӮRedis 4.0зүҲжң¬еҸ‘еёғеҗҺпјҢжҖ§иғҪжңүеҫҲеӨ§зҡ„ж”№иҝӣпјҢ并еҸҜд»ҘйҖҡиҝҮе‘Ҫд»Өеӣһ收еҶ…еӯҳпјҢжҲ‘们зәҝдёҠд№ҹжӯЈеҮҶеӨҮиҝӣиЎҢеҚҮзә§пјҢи·ҹйҡҸ4.0еҸ‘еёғзҡ„jemallocзүҲжң¬дёә4.1пјҢjemallocзҡ„зүҲжң¬дҪҝз”Ёзҡ„еңЁjemallocзҡ„4.0д№ӢеҗҺзүҲжң¬зҡ„arena_purge()еҒҡдәҶеҫҲеӨҡдјҳеҢ–пјҢеҺ»жҺүдәҶи®Ўж•°еҷЁзҡ„и°ғз”ЁпјҢз®ҖеҢ–дәҶеҫҲеӨҡеҲӨж–ӯйҖ»иҫ‘пјҢеўһеҠ дәҶarena_stash_dirty()ж–№жі•еҗҲ并дәҶд№ӢеүҚзҡ„и®Ўз®—е’ҢеҲӨж–ӯйҖ»иҫ‘пјҢеўһеҠ дәҶpurge_runs_sentinelпјҢз”ЁдҝқжҢҒи„Ҹеқ—еңЁжҜҸдёӘarena LRUдёӯзҡ„ж–№ејҸжӣҝд»Јд№ӢеүҚзҡ„дҝқжҢҒи„Ҹеқ—еңЁarenaж ‘зҡ„dirty-run-containing chunckдёӯзҡ„ж–№ејҸпјҢеӨ§е№…еәҰеҮҸе°‘дәҶи„Ҹеқ—purgeзҡ„дҪ“з§ҜпјҢ并且еңЁеҶ…еӯҳеӣһ收иҝҮзЁӢдёӯдёҚеҶҚ移еҠЁеҶ…еӯҳеқ—гҖӮд»Јз ҒеҰӮдёӢпјҡ
arena_purge(arena.c)
static void
arena_purge(arena_t *arena, bool all)
{
chunk_hooks_t chunk_hooks = chunk_hooks_get(arena);
size_t npurge, npurgeable, npurged;
arena_runs_dirty_link_t purge_runs_sentinel;
extent_node_t purge_chunks_sentinel;
arena->purging = true;
/*
* Calls to arena_dirty_count() are disabled even for debug builds
* because overhead grows nonlinearly as memory usage increases.
*/
if (false && config_debug) {
size_t ndirty = arena_dirty_count(arena);
assert(ndirty == arena->ndirty);
}
assert((arena->nactive >> arena->lg_dirty_mult) < arena->ndirty || all);
if (config_stats)
arena->stats.npurge++;
npurge = arena_compute_npurge(arena, all);
qr_new(&purge_runs_sentinel, rd_link);
extent_node_dirty_linkage_init(&purge_chunks_sentinel);
npurgeable = arena_stash_dirty(arena, &chunk_hooks, all, npurge,
&purge_runs_sentinel, &purge_chunks_sentinel);
assert(npurgeable >= npurge);
npurged = arena_purge_stashed(arena, &chunk_hooks, &purge_runs_sentinel,
&purge_chunks_sentinel);
assert(npurged == npurgeable);
arena_unstash_purged(arena, &chunk_hooks, &purge_runs_sentinel,
&purge_chunks_sentinel);
arena->purging = false;
}гҖҗи§ЈеҶій—®йўҳгҖ‘
е®һйҷ…дёҠжҲ‘们жңүеӨҡдёӘйҖүйЎ№гҖӮеҸҜд»ҘдҪҝз”ЁGoogleзҡ„tcmallocжқҘд»ЈжӣҝjemallocпјҢеҸҜд»ҘеҚҮзә§jemallocзҡ„зүҲжң¬зӯүзӯүгҖӮжҲ‘д»¬ж №жҚ®дёҠйқўзҡ„еҲҶжһҗпјҢе°қиҜ•йҖҡиҝҮеҚҮзә§jemallocзүҲжң¬пјҢе®һйҷ…ж“ҚдҪңдёәеҚҮзә§RedisзүҲжң¬жқҘи§ЈеҶігҖӮжҲ‘们е°ҶRedisзҡ„зүҲжң¬еҚҮзә§еҲ°4.0.9д№ӢеҗҺи§ӮеҜҹпјҢзәҝдёҠе®ўжҲ·з«ҜиҝһжҺҘи¶…ж—¶иҝҷдёӘжЈҳжүӢзҡ„й—®йўҳеҫ—еҲ°дәҶи§ЈеҶігҖӮ
гҖҗй—®йўҳжҖ»з»“гҖ‘
RedisеңЁз”ҹдә§зҺҜеўғдёӯеӣ е…¶ж”ҜжҢҒй«ҳ并еҸ‘пјҢе“Қеә”еҝ«пјҢжҳ“ж“ҚдҪңиў«е№ҝжіӣдҪҝз”ЁпјҢеҜ№дәҺиҝҗз»ҙдәәе‘ҳиҖҢиЁҖпјҢе…¶е“Қеә”ж—¶й—ҙзҡ„иҰҒжұӮеёҰжқҘдәҶеҗ„з§Қеҗ„ж ·зҡ„й—®йўҳпјҢRedisзҡ„иҝһжҺҘи¶…ж—¶й—®йўҳжҳҜе…¶дёӯжҜ”иҫғе…ёеһӢзҡ„дёҖз§ҚпјҢд»ҺеҸ‘зҺ°й—®йўҳпјҢе®ўжҲ·з«ҜиҝһжҺҘи¶…ж—¶пјҢеҲ°йҖҡиҝҮжҠ“еҸ–е®ўжҲ·з«ҜдёҺжңҚеҠЎз«Ҝзҡ„зҪ‘з»ңеҢ…пјҢеҶ…еӯҳе Ҷж Ҳе®ҡдҪҚй—®йўҳпјҢд№ҹиў«е…¶дёӯдёҖдәӣеҒҮиұЎжүҖиҝ·жғ‘пјҢжңҖз»ҲйҖҡиҝҮеҚҮзә§jemallocпјҲRedisпјүзҡ„зүҲжң¬и§ЈеҶій—®йўҳпјҢиҝҷж¬ЎжңҖеҖјеҫ—жҖ»з»“е’ҢеҖҹйүҙзҡ„жҳҜж•ҙдёӘеҲҶжһҗзҡ„жҖқи·ҜгҖӮ
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңRedisеҒ¶еҸ‘иҝһжҺҘеӨұиҙҘжҖҺд№ҲеҠһвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !





