这篇文章给大家分享的是有关python中sklearn包的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
preface:做着最近的任务,对数据处理,做些简单的提特征,用机器学习算法跑下程序得出结果,看看哪些特征的组合较好,这一系列流程必然要用到很多函数,故将自己常用函数记录上。应该说这些函数基本上都会用到,像是数据预处理,处理完了后特征提取、降维、训练预测、通过混淆矩阵看分类效果,得出报告。
1.输入
从数据集开始,提取特征转化为有标签的数据集,转为向量。拆分成训练集和测试集,这里不多讲,在上一篇博客中谈到用StratifiedKFold()函数即可。在训练集中有data和target开始。
2.处理
def my_preprocessing(train_data): from sklearn import preprocessing X_normalized = preprocessing.normalize(train_data ,norm = "l2",axis=0)#使用l2范式,对特征列进行正则 return X_normalized def my_feature_selection(data, target): from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 data_new = SelectKBest(chi2, k= 50).fit_transform(data,target) return data_new def my_PCA(data):#data without target, just train data, withou train target. from sklearn import decomposition pca_sklearn = decomposition.PCA() pca_sklearn.fit(data) main_var = pca_sklearn.explained_variance_ print sum(main_var)*0.9 import matplotlib.pyplot as plt n = 15 plt.plot(main_var[:n]) plt.show() def clf_train(data,target): from sklearn import svm #from sklearn.linear_model import LogisticRegression clf = svm.SVC(C=100,kernel="rbf",gamma=0.001) clf.fit(data,target) #clf_LR = LogisticRegression() #clf_LR.fit(x_train, y_train) #y_pred_LR = clf_LR.predict(x_test) return clf def my_confusion_matrix(y_true, y_pred): from sklearn.metrics import confusion_matrix labels = list(set(y_true)) conf_mat = confusion_matrix(y_true, y_pred, labels = labels) print "confusion_matrix(left labels: y_true, up labels: y_pred):" print "labels\t", for i in range(len(labels)): print labels[i],"\t", print for i in range(len(conf_mat)): print i,"\t", for j in range(len(conf_mat[i])): print conf_mat[i][j],'\t', print print def my_classification_report(y_true, y_pred): from sklearn.metrics import classification_report print "classification_report(left: labels):" print classification_report(y_true, y_pred)
my_preprocess()函数:
主要使用sklearn的preprocessing函数中的normalize()函数,默认参数为l2范式,对特征列进行正则处理。即每一个样例,处理标签,每行的平方和为1.
my_feature_selection()函数:
使用sklearn的feature_selection函数中SelectKBest()函数和chi2()函数,若是用词袋提取了很多维的稀疏特征,有必要使用卡方选取前k个有效的特征。
my_PCA()函数:
主要用来观察前多少个特征是主要特征,并且画图。看看前多少个特征占据主要部分。
clf_train()函数:
可用多种机器学习算法,如SVM, LR, RF, GBDT等等很多,其中像SVM需要调参数的,有专门调试参数的函数如StratifiedKFold()(见前几篇博客)。以达到最优。
my_confusion_matrix()函数:
主要是针对预测出来的结果,和原来的结果对比,算出混淆矩阵,不必自己计算。其对每个类别的混淆矩阵都计算出来了,并且labels参数默认是排序了的。
my_classification_report()函数:
主要通过sklearn.metrics函数中的classification_report()函数,针对每个类别给出详细的准确率、召回率和F-值这三个参数和宏平均值,用来评价算法好坏。另外ROC曲线的话,需要是对二分类才可以。多类别似乎不行。
主要参考sklearn官网
补充拓展:[sklearn] 混淆矩阵——多分类预测结果统计
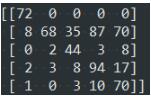
调用的函数:confusion_matrix(typeTrue, typePred)
typeTrue:实际类别,list类型
typePred:预测类别,list类型
结果如下面的截图:
第i行:实际为第i类,预测到各个类的样本数
第j列:预测为第j类,实际为各个类的样本数
true↓ predict→
感谢各位的阅读!关于“python中sklearn包的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





