иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶPythonзҲ¬еҸ–иұҶз“Ји§Ҷйў‘дҝЎжҒҜд»Јз Ғе®һдҫӢ,ж–ҮдёӯйҖҡиҝҮзӨәдҫӢд»Јз Ғд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢеҜ№еӨ§е®¶зҡ„еӯҰд№ жҲ–иҖ…е·ҘдҪңе…·жңүдёҖе®ҡзҡ„еҸӮиҖғеӯҰд№ д»·еҖј,йңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢ
from urllib.request
import quotefrom pyquery
import PyQuery as pqimport requestsimport pandas as pddef get_text_page
(movie_name): ''
' еҮҪж•°еҠҹиғҪпјҡиҺ·еҫ—жҢҮе®ҡз”өеҪұеҗҚзҡ„жәҗд»Јз Ғ еҸӮж•°пјҡз”өеҪұеҗҚ иҝ”еӣһеҖјпјҡз”өеҪұеҗҚз»“жһңзҡ„жәҗд»Јз Ғ '
''
url =
'https://www.douban.com/search?q=' +
movie_name headers = {
'Host': 'www.douban.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
}
r = requests.get(url, headers = headers,
timeout = 5) return r.textdef get_last_url(
this_text): ''
' еҮҪж•°еҠҹиғҪпјҡж №жҚ®жҢҮе®ҡзҡ„жәҗд»Јз Ғеҫ—еҲ°жңҖз»Ҳзҡ„зҪ‘йЎөең°еқҖ еҸӮж•°пјҡжҗңзҙўз»“жһңжәҗд»Јз Ғ иҝ”еӣһеҖјпјҡжңҖз»Ҳзҡ„зҪ‘йЎөең°еқҖ '
''
doc = pq(this_text) lis = doc(
'.title a').items() k = 0 this_str =
''
for i in lis: #print('иұҶз“Јжҗңзҙўз»“жһңдёә:{0}'.format(
i.text()))# print('ең°еқҖдёә:{0}'.format(i.attr
.href))# print('\n') if k == 0:
this_str = i.attr.href k += 1
return this_strdef the_last_page(
this_url): ''
' еҮҪж•°еҠҹиғҪпјҡиҺ·еҫ—жңҖз»Ҳз”өеҪұзҪ‘йЎөзҡ„жәҗд»Јз Ғ еҸӮж•°пјҡжңҖз»Ҳзҡ„ең°еқҖ иҝ”еӣһеҖјпјҡжңҖз»Ҳз”өеҪұзҪ‘йЎөзҡ„жәҗд»Јз Ғ '
''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
}
r = requests.get(this_url, headers =
headers, timeout = 20) return r.textdef the_last_text(
this_text, movie_name): ''
' еҮҪж•°еҠҹиғҪпјҡиҺ·еҫ—жҜҸдёҖйЎ№зҡ„ж•°жҚ® еҸӮж•°пјҡзҲ¬еҸ–йЎөйқўзҡ„жәҗд»Јз Ғ иҝ”еӣһеҖјпјҡиҝ”еӣһз©ә '
''
doc = pq(this_text)# иҺ·еҸ–ж Үйўҳ title = doc(
'#content h2').text()# иҺ·еҸ–жө·жҠҘ photo =
doc('.nbgnbg img') photo_url = photo.attr
.src r = requests.get(photo_url) with open(
'{m}.jpg'.format(m = movie_name),
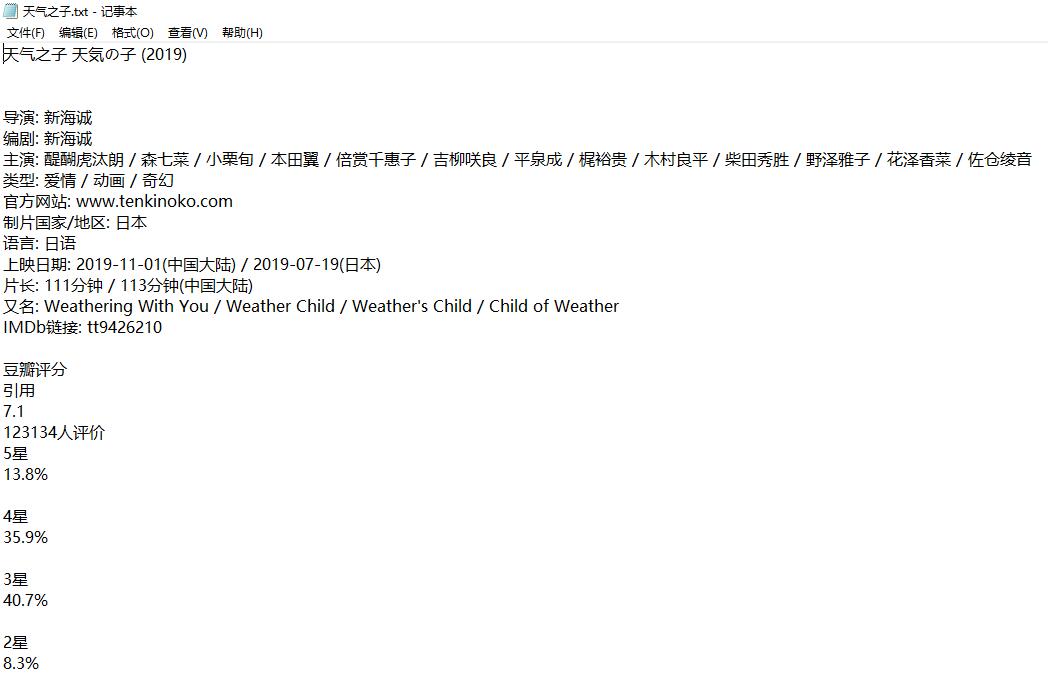
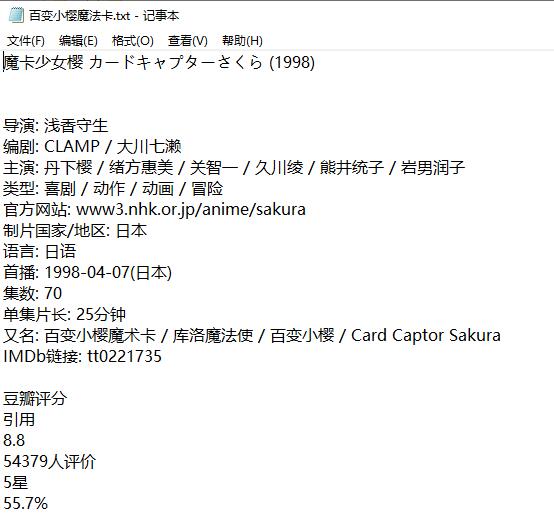
'wb') as f: f.write(r.content)# з”өеҪұдҝЎжҒҜ message =
doc('#info').text()# иұҶз“ЈиҜ„еҲҶ grade = doc(
'#interest_sectl').text()# еү§жғ… things =
doc('.related-info').text() with open(
'{0}.txt'.format(movie_name), 'w+') as f:
try: f.writelines([title, '\n', '\n\n',
message, '\n\n', grade, '\n\n',
things
]) except: f.writelines([title, '\n',
'\n\n', message, '\n\n', grade
])# жј”е‘ҳ# жј”е‘ҳеҗҚ name = [] person_name =
doc('.info').items() for i in
person_name: name.append(i.text())# жј”е‘ҳеӣҫзүҮең°еқҖ person_photo =
doc('#celebrities') j = 0
for i in person_photo.find('.avatar').items():
m = i.attr('style') person_download_url =
m[m.find('(') + 1: m.find(')')]# дёӢиҪҪжј”е‘ҳең°еқҖ r =
requests.get(person_download_url) try:
with open('{name}.jpg'.format(name =
name[j]), 'wb') as f: f.write(r.content) except:
continue j += 1 def lookUrl(this_text,
my_str): ''
' еҮҪж•°еҠҹиғҪпјҡиҺ·еҫ—и§ӮзңӢй“ҫжҺҘ еҸӮж•°пјҡзҲ¬еҸ–йЎөйқўзҡ„жәҗд»Јз Ғ иҝ”еӣһеҖјпјҡиҝ”еӣһз©ә '
''
doc = pq(this_text) all_url = doc(
'.bs li a').items() movie_f = [] movie_url = []
for i in all_url: movie_f.append(i.text()) movie_url
.append(i.attr.href) dataframe = pd.DataFrame({
'и§ӮзңӢе№іеҸ°': movie_f,
'и§ӮзңӢең°еқҖ': movie_url
}) dataframe.to_csv(
"{movie_name}зҡ„и§ӮзңӢең°еқҖ.csv".format(
movie_name = my_str), index = False,
encoding = 'utf_8_sig', sep = ',') def main():
name = input('') my_str = name movie_name =
quote(my_str) page_text =
get_text_page(movie_name)# еҫ—жҢҮе®ҡз”өеҪұеҗҚзҡ„жәҗд»Јз Ғ last_url =
get_last_url(page_text)# ж №жҚ®жҢҮе®ҡзҡ„жәҗд»Јз Ғеҫ—еҲ°жңҖз»Ҳзҡ„зҪ‘йЎөең°еқҖ page_text2 =
the_last_page(last_url)# иҺ·еҫ—жңҖз»Ҳз”өеҪұзҪ‘йЎөзҡ„жәҗд»Јз Ғ the_last_text(
page_text2, my_str)# иҺ·еҫ—жҜҸдёҖйЎ№зҡ„ж•°жҚ® lookUrl(
page_text2, my_str)# еҫ—еҲ°е№¶еӨ„зҗҶи§ӮзңӢй“ҫжҺҘmain()
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ