怎么在python中使用sklearn实现一个KNN分类算法?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
实现步骤:通过选取与该点距离最近的k个样本,在这k个样本中哪一个类别的数量多,就把k归为哪一类。
注意
该算法需要保存训练集的观察值,以此判定待分类数据属于哪一类
k需要进行自定义,一般选取k<30
距离一般用欧氏距离,即 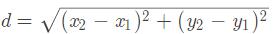
通过sklearn对数据使用KNN算法进行分类
代码如下:
## 导入鸢尾花数据集
iris = datasets.load_iris()
data = iris.data[:, :2]
target = iris.target
## 区分训练集和测试集,75%的训练集和25%的测试集
train_data, test_data = train_test_split(np.c_[data, target])
## 训练并预测,其中选取k=15
clf = neighbors.KNeighborsClassifier(15, 'distance')
clf.fit(train_data[:, :2], train_data[:, 2])
Z = clf.predict(test_data[:, :2])
print '准确率:' ,clf.score(test_data[:, :2], test_data[:, 2])
colormap = dict(zip(np.unique(target), sns.color_palette()[:3]))
plt.scatter(train_data[:, 0], train_data[:, 1], edgecolors=[colormap[x] for x in train_data[:, 2]],c='', s=80, label='all_data')
plt.scatter(test_data[:, 0], test_data[:, 1], marker='^', color=[colormap[x] for x in Z], s=20, label='test_data')
plt.legend()
plt.show()结果如下:
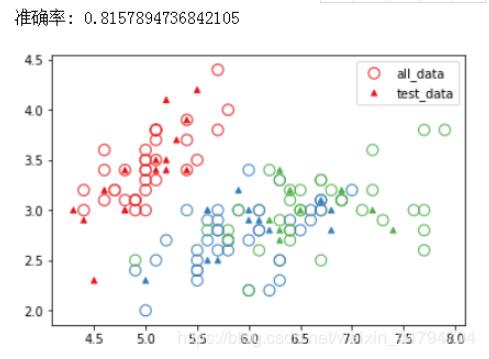
关于怎么在python中使用sklearn实现一个KNN分类算法问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



