1、Node模块机制
1.1 请介绍一下node里的模块是什么
Node中,每个文件模块都是一个对象,它的定义如下:
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
module.exports = Module;
var module = new Module(filename, parent);
所有的模块都是 Module 的实例。可以看到,当前模块(module.js)也是 Module 的一个实例。
1.2 请介绍一下require的模块加载机制
这道题基本上就可以了解到面试者对Node模块机制的了解程度基本上面试提到
1、先计算模块路径
2、如果模块在缓存里面,取出缓存
3、加载模块
4、的输出模块的exports属性即可
// require 其实内部调用 Module._load 方法
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
/********************************这里注意了**************************/
// 第三步:生成模块实例,存入缓存
// 这里的Module就是我们上面的1.1定义的Module
var module = new Module(filename, parent);
Module._cache[filename] = module;
/********************************这里注意了**************************/
// 第四步:加载模块
// 下面的module.load实际上是Module原型上有一个方法叫Module.prototype.load
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
接着上一题继续发问
1.3 加载模块时,为什么每个模块都有__dirname,__filename属性呢,new Module的时候我们看到1.1部分没有这两个属性的,那么这两个属性是从哪里来的
// 上面(1.2部分)的第四步module.load(filename)
// 这一步,module模块相当于被包装了,包装形式如下
// 加载js模块,相当于下面的代码(加载node模块和json模块逻辑不一样)
(function (exports, require, module, __filename, __dirname) {
// 模块源码
// 假如模块代码如下
var math = require('math');
exports.area = function(radius){
return Math.PI * radius * radius
}
});
也就是说,每个module里面都会传入__filename, __dirname参数,这两个参数并不是module本身就有的,是外界传入的
1.4 我们知道node导出模块有两种方式,一种是exports.xxx=xxx和Module.exports={}有什么区别吗
module.exports vs exports
很多时候,你会看到,在Node环境中,有两种方法可以在一个模块中输出变量:
方法一:对module.exports赋值:
// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
module.exports = {
hello: hello,
greet: greet
};
方法二:直接使用exports:
// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
function hello() {
console.log('Hello, world!');
}
exports.hello = hello;
exports.greet = greet;
但是你不可以直接对exports赋值:
// 代码可以执行,但是模块并没有输出任何变量:
exports = {
hello: hello,
greet: greet
};
如果你对上面的写法感到十分困惑,不要着急,我们来分析Node的加载机制:
首先,Node会把整个待加载的hello.js文件放入一个包装函数load中执行。在执行这个load()函数前,Node准备好了module变量:
var module = {
id: 'hello',
exports: {}
};
load()函数最终返回module.exports:
var load = function (exports, module) {
// hello.js的文件内容
...
// load函数返回:
return module.exports;
};
var exported = load(module.exports, module);
也就是说,默认情况下,Node准备的exports变量和module.exports变量实际上是同一个变量,并且初始化为空对象{},于是,我们可以写:
exports.foo = function () { return 'foo'; };
exports.bar = function () { return 'bar'; };
也可以写:
module.exports.foo = function () { return 'foo'; };
module.exports.bar = function () { return 'bar'; };
换句话说,Node默认给你准备了一个空对象{},这样你可以直接往里面加东西。
但是,如果我们要输出的是一个函数或数组,那么,只能给module.exports赋值:
module.exports = function () { return 'foo'; };
给exports赋值是无效的,因为赋值后,module.exports仍然是空对象{}。
结论
如果要输出一个键值对象{},可以利用exports这个已存在的空对象{},并继续在上面添加新的键值;
如果要输出一个函数或数组,必须直接对module.exports对象赋值。
所以我们可以得出结论:直接对module.exports赋值,可以应对任何情况:
module.exports = {
foo: function () { return 'foo'; }
};
或者:
module.exports = function () { return 'foo'; };
最终,我们强烈建议使用module.exports = xxx的方式来输出模块变量,这样,你只需要记忆一种方法。
2、Node的异步I/O
本章的答题思路大多借鉴于朴灵大神的《深入浅出的NodeJS》
2.1 请介绍一下Node事件循环的流程
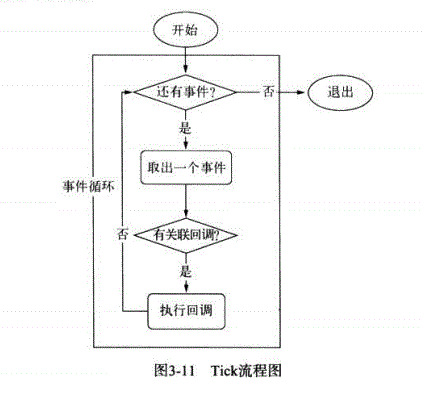
2.2 在每个tick的过程中,如何判断是否有事件需要处理呢?
2.3 请描述一下整个异步I/O的流程

3、V8的垃圾回收机制
3.1 如何查看V8的内存使用情况
使用process.memoryUsage(),返回如下
{
rss: 4935680,
heapTotal: 1826816,
heapUsed: 650472,
external: 49879
}
heapTotal和heapUsed代表V8的内存使用情况。external代表V8管理的,绑定到Javascript的C++对象的内存使用情况。rss, 驻留集大小, 是给这个进程分配了多少物理内存(占总分配内存的一部分) 这些物理内存中包含堆,栈,和代码段。
3.2 V8的内存限制是多少,为什么V8这样设计
64位系统下是1.4GB, 32位系统下是0.7GB。因为1.5GB的垃圾回收堆内存,V8需要花费50毫秒以上,做一次非增量式的垃圾回收甚至要1秒以上。这是垃圾回收中引起Javascript线程暂停执行的事件,在这样的花销下,应用的性能和影响力都会直线下降。
3.3 V8的内存分代和回收算法请简单讲一讲
在V8中,主要将内存分为新生代和老生代两代。新生代中的对象存活时间较短的对象,老生代中的对象存活时间较长,或常驻内存的对象。
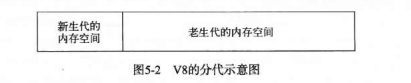
3.3.1 新生代
新生代中的对象主要通过Scavenge算法进行垃圾回收。这是一种采用复制的方式实现的垃圾回收算法。它将堆内存一份为二,每一部分空间成为semispace。在这两个semispace空间中,只有一个处于使用中,另一个处于闲置状态。处于使用状态的semispace空间称为From空间,处于闲置状态的空间称为To空间。

3.3.2 老生代
老生代主要采取的是标记清除的垃圾回收算法。与Scavenge复制活着的对象不同,标记清除算法在标记阶段遍历堆中的所有对象,并标记活着的对象,只清理死亡对象。活对象在新生代中只占叫小部分,死对象在老生代中只占较小部分,这是为什么采用标记清除算法的原因。
3.3.3 标记清楚算法的问题
主要问题是每一次进行标记清除回收后,内存空间会出现不连续的状态

3.3.4 哪些情况会造成V8无法立即回收内存
闭包和全局变量
3.3.5 请谈一下内存泄漏是什么,以及常见内存泄漏的原因,和排查的方法
什么是内存泄漏
一、全局变量
a = 10; //未声明对象。 global.b = 11; //全局变量引用 这种比较简单的原因,全局变量直接挂在 root 对象上,不会被清除掉。
二、闭包
function out() {
const bigData = new Buffer(100);
inner = function () {
}
}
闭包会引用到父级函数中的变量,如果闭包未释放,就会导致内存泄漏。上面例子是 inner 直接挂在了 root 上,那么每次执行 out 函数所产生的 bigData 都不会释放,从而导致内存泄漏。
需要注意的是,这里举得例子只是简单的将引用挂在全局对象上,实际的业务情况可能是挂在某个可以从 root 追溯到的对象上导致的。
三、事件监听
Node.js 的事件监听也可能出现的内存泄漏。例如对同一个事件重复监听,忘记移除(removeListener),将造成内存泄漏。这种情况很容易在复用对象上添加事件时出现,所以事件重复监听可能收到如下警告:
emitter.setMaxListeners() to increase limit
例如,Node.js 中 Agent 的 keepAlive 为 true 时,可能造成的内存泄漏。当 Agent keepAlive 为 true 的时候,将会复用之前使用过的 socket,如果在 socket 上添加事件监听,忘记清除的话,因为 socket 的复用,将导致事件重复监听从而产生内存泄漏。
原理上与前一个添加事件监听的时候忘了清除是一样的。在使用 Node.js 的 http 模块时,不通过 keepAlive 复用是没有问题的,复用了以后就会可能产生内存泄漏。所以,你需要了解添加事件监听的对象的生命周期,并注意自行移除。
排查方法
4、Buffer模块
4.1 新建Buffer会占用V8分配的内存吗
不会,Buffer属于堆外内存,不是V8分配的。
4.2 Buffer.alloc和Buffer.allocUnsafe的区别
Buffer.allocUnsafe创建的 Buffer 实例的底层内存是未初始化的。 新创建的 Buffer 的内容是未知的,可能包含敏感数据。 使用 Buffer.alloc() 可以创建以零初始化的 Buffer 实例。
4.3 Buffer的内存分配机制
为了高效的使用申请来的内存,Node采用了slab分配机制。slab是一种动态的内存管理机制。Node以8kb为界限来来区分Buffer为大对象还是小对象,如果是小于8kb就是小Buffer,大于8kb就是大Buffer。
例如第一次分配一个1024字节的Buffer,Buffer.alloc(1024),那么这次分配就会用到一个slab,接着如果继续Buffer.alloc(1024),那么上一次用的slab的空间还没有用完,因为总共是8kb,1024+1024 = 2048个字节,没有8kb,所以就继续用这个slab给Buffer分配空间。
如果超过8bk,那么直接用C++底层地宫的SlowBuffer来给Buffer对象提供空间。
4.4 Buffer乱码问题
例如一个份文件test.md里的内容如下:
床前明月光,疑是地上霜,举头望明月,低头思故乡
我们这样读取就会出现乱码:
var rs = require('fs').createReadStream('test.md', {highWaterMark: 11});
// 床前明???光,疑???地上霜,举头???明月,???头思故乡
一般情况下,只需要设置rs.setEncoding('utf8')即可解决乱码问题
5、webSocket
5.1 webSocket与传统的http有什么优势
5.2 webSocket协议升级时什么,能简述一下吗?
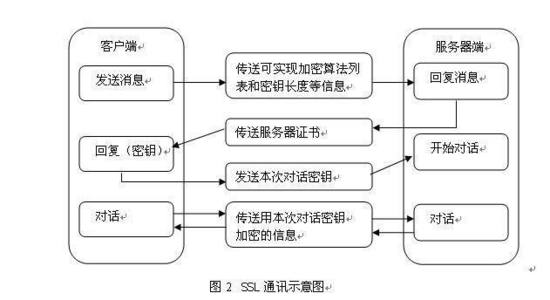
首先,WebSocket连接必须由浏览器发起,因为请求协议是一个标准的HTTP请求,格式如下:
GET ws://localhost:3000/ws/chat HTTP/1.1 Host: localhost Upgrade: websocket Connection: Upgrade Origin: http://localhost:3000 Sec-WebSocket-Key: client-random-string Sec-WebSocket-Version: 13
该请求和普通的HTTP请求有几点不同:
随后,服务器如果接受该请求,就会返回如下响应:
HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Sec-WebSocket-Accept: server-random-string
该响应代码101表示本次连接的HTTP协议即将被更改,更改后的协议就是Upgrade: websocket指定的WebSocket协议。
6、https
6.1 https用哪些端口进行通信,这些端口分别有什么用
6.2 身份验证过程中会涉及到密钥, 对称加密,非对称加密,摘要的概念,请解释一下
6.3 为什么需要CA机构对证书签名
如果不签名会存在中间人攻击的风险,签名之后保证了证书里的信息,比如公钥、服务器信息、企业信息等不被篡改,能够验证客户端和服务器端的“合法性”。
6.4 https验证身份也就是TSL/SSL身份验证的过程
简要图解如下
7、进程通信
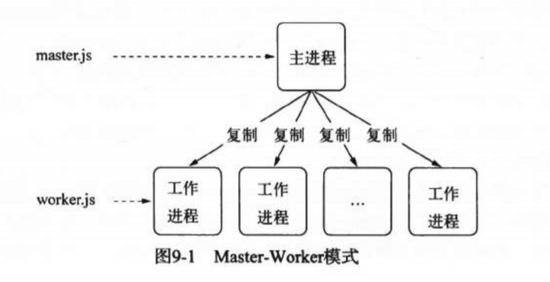
7.1 请简述一下node的多进程架构
面对node单线程对多核CPU使用不足的情况,Node提供了child_process模块,来实现进程的复制,node的多进程架构是主从模式,如下所示:
var fork = require('child_process').fork;
var cpus = require('os').cpus();
for(var i = 0; i < cpus.length; i++){
fork('./worker.js');
}
在linux中,我们通过ps aux | grep worker.js查看进程

这就是著名的主从模式,Master-Worker
7.2 请问创建子进程的方法有哪些,简单说一下它们的区别
创建子进程的方法大致有:
7.3 请问你知道spawn在创建子进程的时候,第三个参数有一个stdio选项吗,这个选项的作用是什么,默认的值是什么。
7.4 请问实现一个node子进程被杀死,然后自动重启代码的思路
在创建子进程的时候就让子进程监听exit事件,如果被杀死就重新fork一下
var createWorker = function(){
var worker = fork(__dirname + 'worker.js')
worker.on('exit', function(){
console.log('Worker' + worker.pid + 'exited');
// 如果退出就创建新的worker
createWorker()
})
}
7.5 在7.4的基础上,实现限量重启,比如我最多让其在1分钟内重启5次,超过了就报警给运维
7.6 如何实现进程间的状态共享,或者数据共享
我自己没用过Kafka这类消息队列工具,问了java,可以用类似工具来实现进程间通信,更好的方法欢迎留言
8、中间件
8.1 如果使用过koa、egg这两个Node框架,请简述其中的中间件原理,最好用代码表示一下
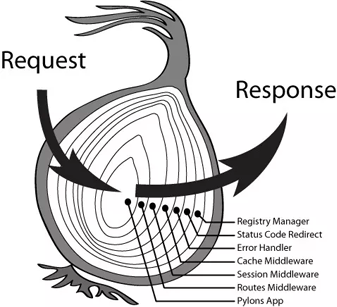
上面是在网上找的一个示意图,就是说中间件执行就像洋葱一样,最早use的中间件,就放在最外层。处理顺序从左到右,左边接收一个request,右边输出返回response
一般的中间件都会执行两次,调用next之前为第一次,调用next时把控制传递给下游的下一个中间件。当下游不再有中间件或者没有执行next函数时,就将依次恢复上游中间件的行为,让上游中间件执行next之后的代码
例如下面这段代码
const Koa = require('koa')
const app = new Koa()
app.use((ctx, next) => {
console.log(1)
next()
console.log(3)
})
app.use((ctx) => {
console.log(2)
})
app.listen(3001)
执行结果是1=>2=>3
koa中间件实现源码大致思路如下:
// 注意其中的compose函数,这个函数是实现中间件洋葱模型的关键
// 场景模拟
// 异步 promise 模拟
const delay = async () => {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve();
}, 2000);
});
}
// 中间间模拟
const fn1 = async (ctx, next) => {
console.log(1);
await next();
console.log(2);
}
const fn2 = async (ctx, next) => {
console.log(3);
await delay();
await next();
console.log(4);
}
const fn3 = async (ctx, next) => {
console.log(5);
}
const middlewares = [fn1, fn2, fn3];
// compose 实现洋葱模型
const compose = (middlewares, ctx) => {
const dispatch = (i) => {
let fn = middlewares[i];
if(!fn){ return Promise.resolve() }
return Promise.resolve(fn(ctx, () => {
return dispatch(i+1);
}));
}
return dispatch(0);
}
compose(middlewares, 1);
9、其它
现在在重新过一遍node 12版本的主要API,有很多新发现,比如说
const util = require('util');
const fs = require('fs');
const stat = util.promisify(fs.stat);
stat('.').then((stats) => {
// 处理 `stats`。
}).catch((error) => {
// 处理错误。
});
9.1 杂想
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





