1. 场景描述
一直做java,因项目原因,需要封装一些经典的算法到平台上去,就一边学习python,一边网上寻找经典算法代码,今天介绍下经典的K-means聚类算法,算法原理就不介绍了,只从代码层面进行介绍,包含:rest接口、连接mpp数据库、回传json数据、下载图片及数据。
2. 解决方案
2.1 项目套路
(1)python经典算法是单独的服务器部署,提供rest接口出来,供java平台调用,交互的方式是http+json;
(2)数据从mpp数据库-Greenplum中获取;
(3)返回的数据包括三个:1是生成聚类图片的地址;2是聚类项目完整数据地址;3是返回给前端的200条json预览数据。
2.2 restapi类
分两个类,第一个是restapi类,封装rest接口类,其他的经典算法在这里都有对应的方法,是个公共类。
完整代码:
# -*- coding: utf-8 -*-
from flask import Flask, request, send_from_directory
from k_means import exec
import logging
app = Flask(__name__)
#1.服务器上更改为服务器地址,用于存放数据
dirpath = 'E:\\ruanjianlaowang'
#2. 测试连通性,软件老王
@app.route('/')
def index():
return "Hello, World!"
#3. k-means算法 软件老王
@app.route('/getKmeansInfoByLaowang', methods=['POST'])
def getKmeansInfoByLaowang():
try:
result = exec(request.get_json(), dirpath)
except IndexError as e:
logging.error(str(e))
return 'exception:' + str(e)
except KeyError as e:
logging.error(str(e))
return 'exception:' + str(e)
except ValueError as e:
logging.error(str(e))
return 'exception:' + str(e)
except Exception as e:
logging.error(str(e))
return 'exception:' + str(e)
else:
return result
#4.文件下载(图片及csv)
@app.route("/<path:filename>")
def getImages(filename):
return send_from_directory(dirpath, filename, as_attachment=True)
#5.启动
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)代码说明:
使用的是第三方的flask提供的rest服务
(1)服务器上更改为服务器地址,用于存放数据
(2)测试连通性,软件老王
(3)k-means算法 软件老王
(4)文件下载(图片及csv)
(5)启动
2.3 k-means算法类
完整代码:
import pandas as pd
import dbgp as dbgp
from pandas.io import json
from numpy import *
import matplotlib.pyplot as plt
import numpy as np
plt.switch_backend('agg')
import logging
# 执行 软件老王
def exec(params, dirpath):
#1.获取参数,软件老王
sql = params.get("sql")
xlines = params.get("xlines")
ylines = params.get("ylines")
xlinesname = params.get("xlinesname")
ylinesname = params.get("ylinesname")
grouplinesname = params.get("grouplinesname")
times = int(params.get("times"))
groupnum = int(params.get("groupnum"))
url = params.get("url")
name = params.get("name")
#2. 校验是否为空,软件老王
flag = checkparam(sql, xlines, ylines, times, groupnum)
if not flag is None and len(flag) != 0:
return flag
#3. 从数据库获取数据,软件老王
try:
data = dbgp.queryGp(sql)
except IndexError:
return sql
except KeyError:
return sql
except ValueError:
return sql
except Exception:
return sql
if data.empty:
return "exception:此数据集无数据,请确认后重试"
#4 调用第三方sklearn的KMeans聚类算法,软件老王
# data_zs = 1.0 * (data - data.mean()) / data.std() 数据标准化,不需要标准话
from sklearn.cluster import KMeans
model = KMeans(n_clusters=groupnum, n_jobs=4, max_iter=times)
model.fit(data) # 开始聚类
return export(model, data, data, url, dirpath, name,grouplinesname,xlines, ylines,xlinesname,ylinesname)
# 5.生成导出excel 软件老王
def export(model, data, data_zs, url, dirpath, name,grouplinesname,xlines, ylines,xlinesname,ylinesname):
# #详细输出原始数据及其类别
detail_data = pd.DataFrame().append(data)
if not grouplinesname is None and len(grouplinesname) != 0:
detail_data.columns = grouplinesname.split(',')
r_detail_new = pd.concat([detail_data, pd.Series(model.labels_, index=detail_data.index)], axis=1) # 详细输出每个样本对应的类别
r_detail_new.columns = list(detail_data.columns) + [u'聚类类别'] # 重命名表头
outputfile = dirpath + name + '.csv'
r_detail_new.to_csv(outputfile, encoding='utf_8_sig') # 保存结果
#重命名表头
r1 = pd.Series(model.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) # 找出聚类中心
r = pd.concat([r2, r1], axis=1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + [u'类别数目'] # 重命名表头
return generateimage(r, data_zs, url, dirpath, name,model,xlines, ylines,xlinesname,ylinesname)
#6.生成图片及返回json,软件老王
def generateimage(r, data_zs, url, dirpath, name,model,xlines, ylines,xlinesname,ylinesname):
image = dirpath + name + '.jpg'
#6.1 中文处理,软件老王
plt.rcParams['font.sans-serif'] = ['simhei']
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['axes.unicode_minus'] = False
# 6.2 画图,生成图片,软件老王
labels = model.labels_
centers = model.cluster_centers_
data_zs['label'] = labels
data_zs['label'] = data_zs['label'].astype(np.int)
# 图标集合
markers = ['o', 's', '+', 'x', '^', 'v', '<', '>']
colors = ['b', 'c', 'g', 'k', 'm', 'r', 'y']
symbols = []
for m in markers:
for c in colors:
symbols.append((m, c))
# 画每个类别的散点及质心
for i in range(0, len(centers)):
df_i = data_zs.loc[data_zs['label'] == i]
symbol = symbols[i]
center = centers[i]
x = df_i[xlines].values.tolist()
y = df_i[ylines].values.tolist()
plt.scatter(x, y, marker=symbol[0], color=symbol[1], s=10)
plt.scatter(center[0], center[1], marker='*', color=symbol[1], s=50)
plt.title(name)
plt.xlabel(xlinesname)
plt.ylabel(ylinesname)
plt.savefig(image, dpi=150)
plt.clf()
plt.close(0)
# 6.3 返回json数据给前端展示,软件老王
result = {}
result['image_url'] = url + '/' + name + '.jpg'
result['details_url'] = url + '/' + name + '.csv'
result['data'] = r[:200] #显示200,多的话,相当于预览
result = json.dumps(result, ensure_ascii=False)
result = result.replace('\\', '')
return result
def checkparam(sql, xlines, ylines, times, groupnum):
if sql is None or sql.strip() == '' or len(sql.strip()) == 0:
return "数据集或聚类数据列,不能为空"
if xlines is None or xlines.strip() == '' or len(xlines.strip()) == 0:
return "X轴,不能为空"
if ylines is None or ylines.strip() == '' or len(ylines.strip()) == 0:
return "Y轴,不能为空"
if times is None or times <= 0:
return "聚类个数,不能为空或小于等于0"
if groupnum is None or groupnum <= 0:
return "迭代次数,不能为空或小于等于0"代码说明:
(1)获取参数,软件老王;
(2)校验是否为空,软件老王;
(3)从数据库获取数据,软件老王;
(4)第三方sklearn的KMeans聚类算法,软件老王;
(5)生成导出excel 软件老王
(6)生成图片及返回json,软件老王
(6.1) 中文处理,软件老王
(6.2) 画图,生成图片,软件老王
(6.3) 返回json数据给前端展示,软件老王
2.4 执行效果
2.4.1 json返回
{"image_url":"http://10.192.168.1:5000/ruanjianlaowang_65652.jpg","details_url":"http://10.192.168.1:5000/ruanjianlaowang_65652.csv","data":{"empno":{"0":7747.2,"1":7699.625,"2":7839.0},"mgr":{"0":7729.8,"1":7745.25,"2":7566.0},"sal":{"0":2855.0,"1":1218.75,"2":5000.0},"comm":{"0":29.5110766,"1":117.383964625,"2":31.281453},"deptno":{"0":20.0,"1":25.0,"2":10.0},"类别数目":{"0":5,"1":8,"2":1}}}2.4.2 返回图片
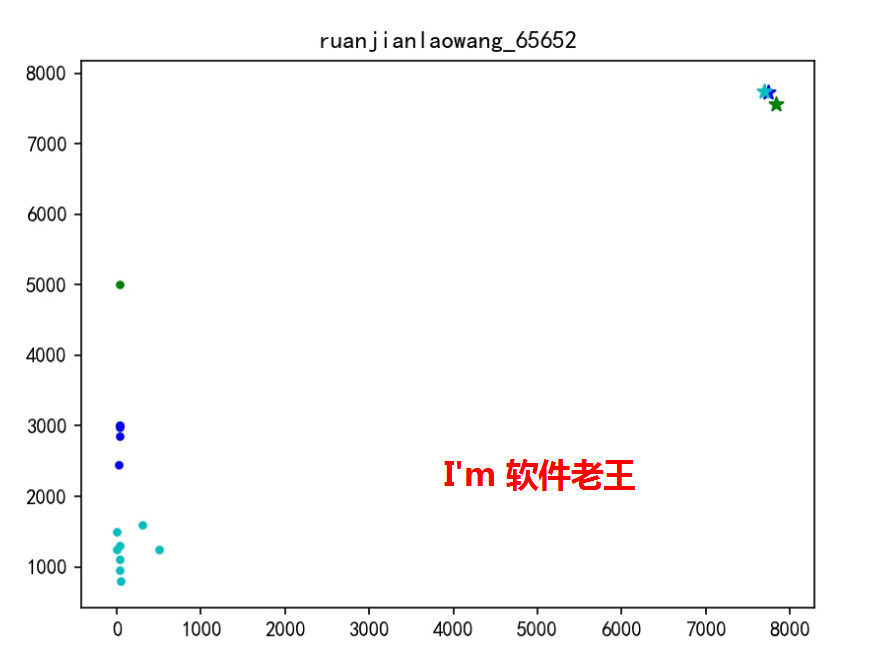
2.4.3 返回的数据
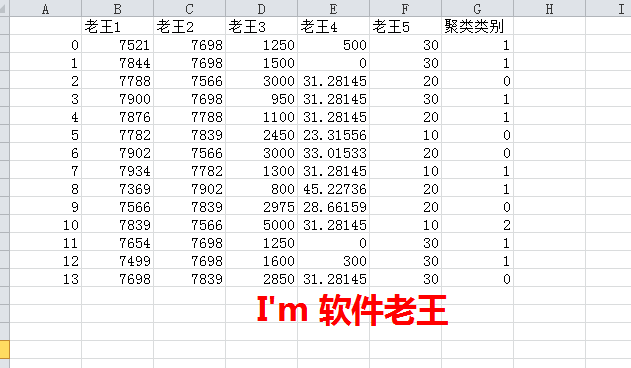
另外说明: 目前项目环境上用的是8核16G的虚拟机,执行数据量是30万,运行状况良好。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



