学习《Python3爬虫、数据清洗与可视化实战》时自己的一些实践。
DataFrame分组操作
注意分组后得到的就是Series对象了,而不再是DataFrame对象。
import pandas as pd
# 还是读取这份文件
df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0)
# 计算'成交量'按'位置'分组的平均值
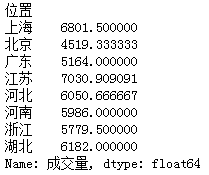
grouped1 = df['成交量'].groupby(df['位置']).mean()
# print(grouped1)
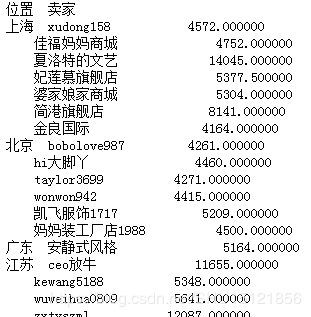
# 计算'成交量'先按'位置'再按'卖家'分组后的平均值 grouped2 = df['成交量'].groupby([df['位置'], df['卖家']]).mean() # print(grouped2)
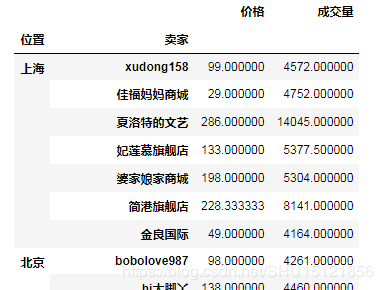
# 计算先按'位置'再按'卖家'分组后的所有指标(如果可以计算平均值)的平均值 grouped3 = df.groupby([df['位置'], df['卖家']]).mean() # print(grouped3)
DataFrame数据分割和合并
这里其实可以操作得很复杂,这里是一些比较基本的用法。
import pandas as pd
# 还是读取这份文件
df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0)
# 计算销售额
df['销售额'] = df['价格'] * df['成交量']
# (1)前面学了ix,loc,iloc,这里是直接用[]运算做分割
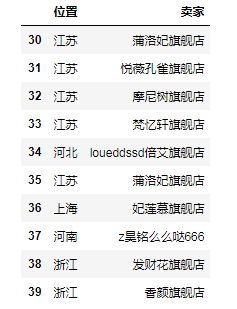
df1 = df[30:40][['位置', '卖家']]
# print(df1) # 从30号行到39号行
df2 = df[80:90][['卖家', '销售额']]
# (2)内联接操作(相当于JOIN,INNER JOIN) df3 = pd.merge(df1, df2) # 不指定列名,默认选择列名相同的'卖家'列 # print(df3) df4 = pd.merge(df1, df2, on='卖家') # 指定按照'卖家'相同做联接 # print(df4)

# (3)全外联接操作(相当于FULL JOIN),没有值的补NaN df5 = pd.merge(df1, df2, how='outer') # print(df5)
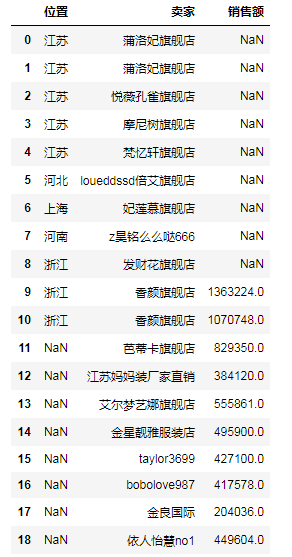
# (4)左外联接操作(相当于LEFT JOIN),即左边的都要,'销售额'没有就NaN df6 = pd.merge(df1, df2, how='left') # print(df6)
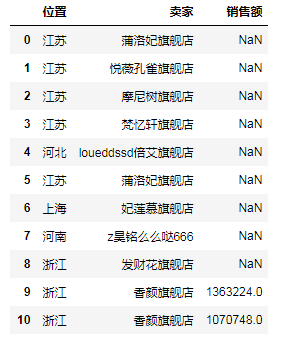
# (5)右外联接操作(相当于RIGHT JOIN),即右边的都要,'位置'没有就NaN df7 = pd.merge(df1, df2, how='right') # print(df7)
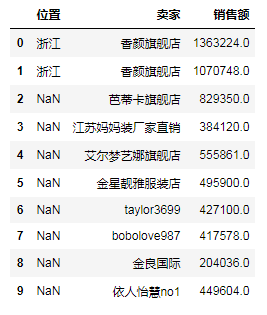
# (6)按索引相同做联接 df_a = df[:10][['位置', '卖家']] df_b = df[3:13][['价格', '成交量']] df_c_1 = pd.merge(df_a, df_b, left_index=True, right_index=True) # 内联接 # print(df_c_1) # 只有从3到9的
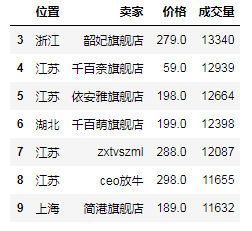
df_c_2 = df_a.join(df_b) # 左外联接 # print(df_c_2) # 从0到10
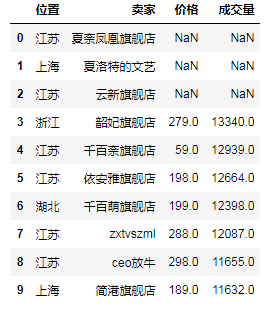
df_c_3 = df_b.join(df_a) # "右"外联接(其实还是左外联接,就是b在左边a在右边) # print(df_c_3) # 从3到12
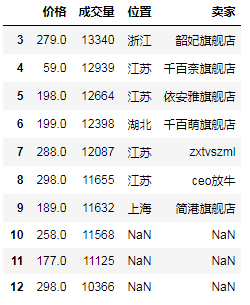
# (7)轴向堆叠操作(上下堆叠时就相当于UNION ALL,默认不去重) df8 = df[2:5][['价格']] # 注意这里只取一个列也要用[[]] df9 = df[3:8][['销售额', '宝贝']] df10 = df[6:11][['卖家', '位置']] # (7.1)默认axis=0即上下堆叠,上下堆叠时,堆叠顺序和传进concat的顺序一致,最终列=所有列数去重,缺失的补NaN # 关于axis=0需要设置sort属性的问题,还没查到有讲这个的,这个问题先留着... df11 = pd.concat([df10, df9, df8], sort=False) # print(df11)
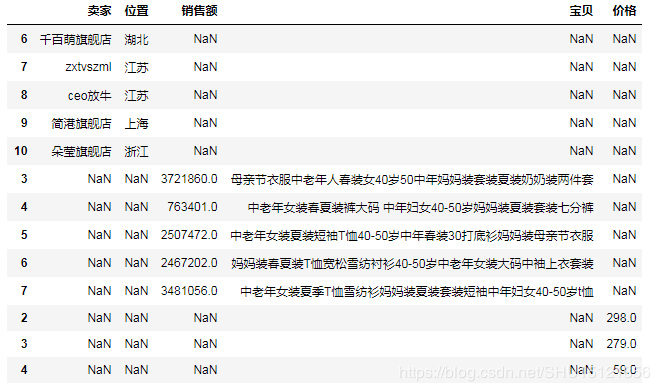
# (7.2)设置axis=1即左右堆叠,左右堆叠不允许索引重复,相同索引的将被合并到一行 # 左右堆叠中,堆叠顺序仅仅影响列的出现顺序 # 这很好理解,毕竟不是从上到下"摞"在一起的,而是从左到右"卡"在一起的 df12 = pd.concat([df10, df9, df8], axis=1) df13 = pd.concat([df8, df9, df10], axis=1) # print(df12) # print(df13)
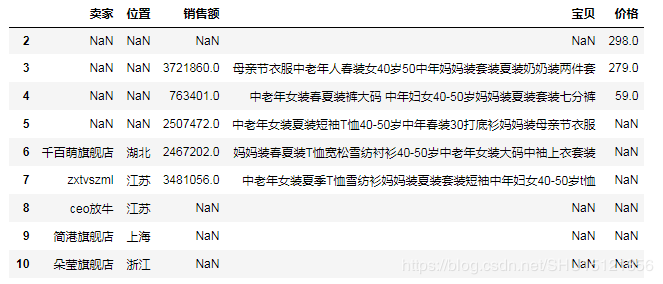

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





