在机器学习中,我们经常在训练集上训练模型,在测试集上测试模型。最终的目标是希望我们的模型在测试集上有最好的表现。
但是,我们往往只有一个包含m个观测的数据集D,我们既要用它进行训练,又要对它进行测试。此时,我们就需要对数据集D进行划分。
对于数据集D的划分,我们尽量需要满足三个要求:
我们将分别介绍留出法、交叉验证法,以及各自的python实现。自助法(bootstrapping)将在下篇中加以介绍。
1.留出法
留出法是最常用最直接最简单的方法,它直接将数据集D拆分成两个互斥的集合,其中一个作为训练集R,另一个作为测试集T。 即
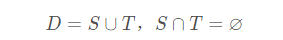
在使用留出法时,需要注意:
当然留出法的缺点也非常明显,即它会损失一定的样本信息;同时需要大样本。
python实现留出法,只需要使用sklearn包就可以
from sklearn.model_selection import train_test_split
#使用train_test_split划分训练集和测试集
train_X , test_X, train_Y ,test_Y = train_test_split(
X, Y, test_size=0.2,random_state=0)
'''
X为原始数据的自变量,Y为原始数据因变量;
train_X,test_X是将X按照8:2划分所得;
train_Y,test_Y是将X按照8:2划分所得;
test_size是划分比例;
random_state设置是否使用随机数
'''2.交叉验证法
交叉验证法(cross validation)可以很好地解决留出法的问题,它对数据量的要求不高,并且样本信息损失不多。
交叉验证法先将数据集D划分为k个大小相似的互斥子集,即
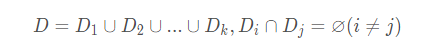
为了保证数据分布的一致性,从D中随机分层抽样即可。
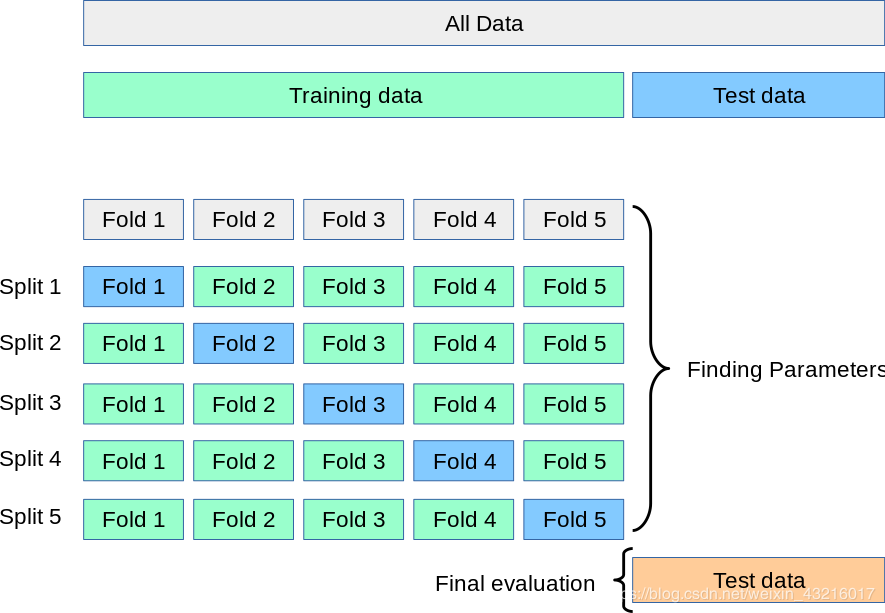
之后,每次都用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样我们就可以获得k组训练/测试集,从而进行k次训练和测试,最终返回这k组测试的均值。
具体说来,我们以k=10为例:
第一次我们选取第10份数据为测试集,前9份为训练集;
第二次我们选取第9份数据为测试集,第1-8和10为训练集;
…
第十次我们选取第1份数据为测试集,第2-9为训练集;
由此,我们共获得10组训练集和测试集,进行10次训练和测试,最终返回10次测试结果的均值。
显然,交叉验证法结果的稳定性和保真性很大程度取决于k的选择,为了强调这一点,交叉验证法也称作“k折交叉验证法”,k最常取的是10,也有取5或者20的。
同时,我们也需要避免由于数据划分的随机性造成的误差,我们可以重复进行p次实验。
p次k折交叉验证法,相当于做了pk次留出法(比例为k-1:1)
python实现交叉验证法,只需要使用sklearn包就可以。注意,函数返回的是样本序号。
import pandas as pd
from sklearn.model_selection import KFold
data = pd.read_excel('') #导入数据
kf = KFold(n_splits = 4,shuffle = False,random_state = None)
'''n_splits表示将数据分成几份;shuffle和random_state表示是否随机生成。
如果shuffle = False,random_state = None,重复运行将产生同样的结果;
如果shuffle = True,random_state = None,重复运行将产生不同的结果;
如果shuffle = True,random_state = (一个数值),重复运行将产生相同的结果;
'''
for train, test in kf.split(data):
print("%s %s" % (train, test))
'''
结果
[ 5 6 7 8 9 10 11 12 13 14 15 16 17 18] [0 1 2 3 4]
[ 0 1 2 3 4 10 11 12 13 14 15 16 17 18] [5 6 7 8 9]
[ 0 1 2 3 4 5 6 7 8 9 15 16 17 18] [10 11 12 13 14]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14] [15 16 17 18]
'''如果想对数据集重复几次使用交叉验证法划分的话,使用RepeatedKFold函数即可,其中多了一个参数n_repeats
与留出法相比,交叉验证法的数据损失较小,更加适合于小样本,但是其计算复杂度变高,存储空间变大。极端的说来,如果将数据集D(m个样本)分成m份,每次都取m-1个样本为训练集,余下的那一个为测试集。共进行m次训练和测试。这种方法被叫做留一法。
留一法的优点显而易见,其数据损失只有一个样本,并且不会受到样本随即划分的影响。但是,其计算复杂度过高,空间存储占用过大。
python实现交叉验证法,只需要使用sklearn包就可以
from sklearn.model_selection import LeaveOneOut
X = [1, 2, 3, 4]
loo = LeaveOneOut()
for train, test in loo.split(data):
print("%s %s" % (train, test))
'''结果
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
'''
综上所述:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



