怎么在Python中使用PyQt5实现可视化爬虫工具?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
Python主要应用于:1、Web开发;2、数据科学研究;3、网络爬虫;4、嵌入式应用开发;5、游戏开发;6、桌面应用开发。
import urllib.request
from urllib import parse
from lxml import etree
import ssl
from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox
import sys
# 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context
class TextEditMeiJu(QWidget):
def __init__(self, parent=None):
super(TextEditMeiJu, self).__init__(parent)
# 定义窗口头部信息
self.setWindowTitle('美剧天堂')
# 定义窗口的初始大小
self.resize(500, 600)
# 创建单行文本框
self.textLineEdit = QLineEdit()
# 创建一个按钮
self.btnButton = QPushButton('确定')
# 创建多行文本框
self.textEdit = QTextEdit()
# 实例化垂直布局
layout = QVBoxLayout()
# 相关控件添加到垂直布局中
layout.addWidget(self.textLineEdit)
layout.addWidget(self.btnButton)
layout.addWidget(self.textEdit)
# 设置布局
self.setLayout(layout)
# 将按钮的点击信号与相关的槽函数进行绑定,点击即触发
self.btnButton.clicked.connect(self.buttonClick)
# 点击确认按钮
def buttonClick(self):
# 爬取开始前提示一下
start = QMessageBox.information(
self, '提示', '是否开始爬取《' + self.textLineEdit.text() + "》",
QMessageBox.Ok | QMessageBox.No, QMessageBox.Ok
)
# 确定爬取
if start == QMessageBox.Ok:
self.page = 1
self.loadSearchPage(self.textLineEdit.text(), self.page)
# 取消爬取
else:
pass
# 加载输入美剧名称后的页面
def loadSearchPage(self, name, page):
# 将文本转为 gb2312 编码格式
name = parse.quote(name.encode('gb2312'))
# 请求发送的 url 地址
url = "https://www.meijutt.com/search/index.asp?page=" + str(page) + "&searchword=" + name + "&searchtype=-1"
# 请求报头
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
# 发送请求
request = urllib.request.Request(url, headers=headers)
# 获取请求的 html 文档
html = urllib.request.urlopen(request).read()
# 对 html 文档进行解析
text = etree.HTML(html)
# xpath 获取想要的信息
pageTotal = text.xpath('//div[@class="page"]/span[1]/text()')
# 判断搜索内容是否有结果
if pageTotal:
self.loadDetailPage(pageTotal, text, headers)
# 搜索内容无结果
else:
self.infoSearchNull()
# 加载点击搜索页面点击的本季页面
def loadDetailPage(self, pageTotal, text, headers):
# 取出搜索的结果一共多少页
pageTotal = pageTotal[0].split('/')[1].rstrip("页")
# 获取每一季的内容(剧名和链接)
node_list = text.xpath('//a[@class="B font_14"]')
items = {}
items['name'] = self.textLineEdit.text()
# 循环获取每一季的内容
for node in node_list:
# 获取信息
title = node.xpath('@title')[0]
link = node.xpath('@href')[0]
items["title"] = title
# 通过获取的单季链接跳转到本季的详情页面
requestDetail = urllib.request.Request("https://www.meijutt.com" + link, headers=headers)
htmlDetail = urllib.request.urlopen(requestDetail).read()
textDetail = etree.HTML(htmlDetail)
node_listDetail = textDetail.xpath('//div[@class="tabs-list current-tab"]//strong//a/@href')
self.writeDetailPage(items, node_listDetail)
# 爬取完毕提示
if self.page == int(pageTotal):
self.infoSearchDone()
else:
self.infoSearchContinue(pageTotal)
# 将数据显示到图形界面
def writeDetailPage(self, items, node_listDetail):
for index, nodeLink in enumerate(node_listDetail):
items["link"] = nodeLink
# 写入图形界面
self.textEdit.append(
"<div>"
"<font color='black' size='3'>" + items['name'] + "</font>" + "\n"
"<font color='red' size='3'>" + items['title'] + "</font>" + "\n"
"<font color='orange' size='3'>第" + str(index + 1) + "集</font>" + "\n"
"<font color='green' size='3'>下载链接:</font>" + "\n"
"<font color='blue' size='3'>" + items['link'] + "</font>"
"<p></p>"
"</div>"
)
# 搜索不到结果的提示信息
def infoSearchNull(self):
QMessageBox.information(
self, '提示', '搜索结果不存在,请重新输入搜索内容',
QMessageBox.Ok, QMessageBox.Ok
)
# 爬取数据完毕的提示信息
def infoSearchDone(self):
QMessageBox.information(
self, '提示', '爬取《' + self.textLineEdit.text() + '》完毕',
QMessageBox.Ok, QMessageBox.Ok
)
# 多页情况下是否继续爬取的提示信息
def infoSearchContinue(self, pageTotal):
end = QMessageBox.information(
self, '提示', '爬取第' + str(self.page) + '页《' + self.textLineEdit.text() + '》完毕,还有' + str(int(pageTotal) - self.page) + '页,是否继续爬取',
QMessageBox.Ok | QMessageBox.No, QMessageBox.No
)
if end == QMessageBox.Ok:
self.page += 1
self.loadSearchPage(self.textLineEdit.text(), self.page)
else:
pass
if __name__ == '__main__':
app = QApplication(sys.argv)
win = TextEditMeiJu()
win.show()
sys.exit(app.exec_())以上是实现功能的所有代码,可以运行 Python 的小伙伴直接复制到本地运行即可。都说 Python 是做爬虫最好的工具,写完之后发现确实是这样。
我们一点点分析代码:
import urllib.request from urllib import parse from lxml import etree import ssl from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox, QLabel import sys
以上为我们引入的所需要的库,前 4 行是爬取 美剧天堂 官网所需要的库,后两个是实现图形化应用所需的库。
我们先来看一下如何爬取网站信息。
由于现在 美剧天堂 使用的是 https 协议,进入页面需要代理验证,为了不必要的麻烦,我们干脆取消代理验证,所以用到了 ssl 模块。
然后我们就可以正大光明的进入网站了:
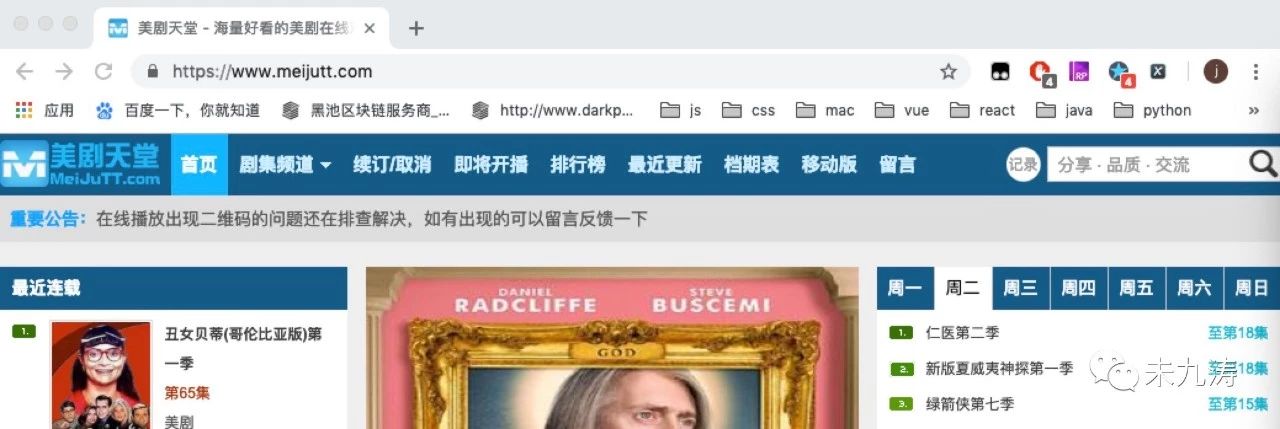
令人遗憾的是 url 链接为https://www.meijutt.com/search/index.asp,显然没有为我们提供任何有用的信息,当我们刷新页面时,如下图:
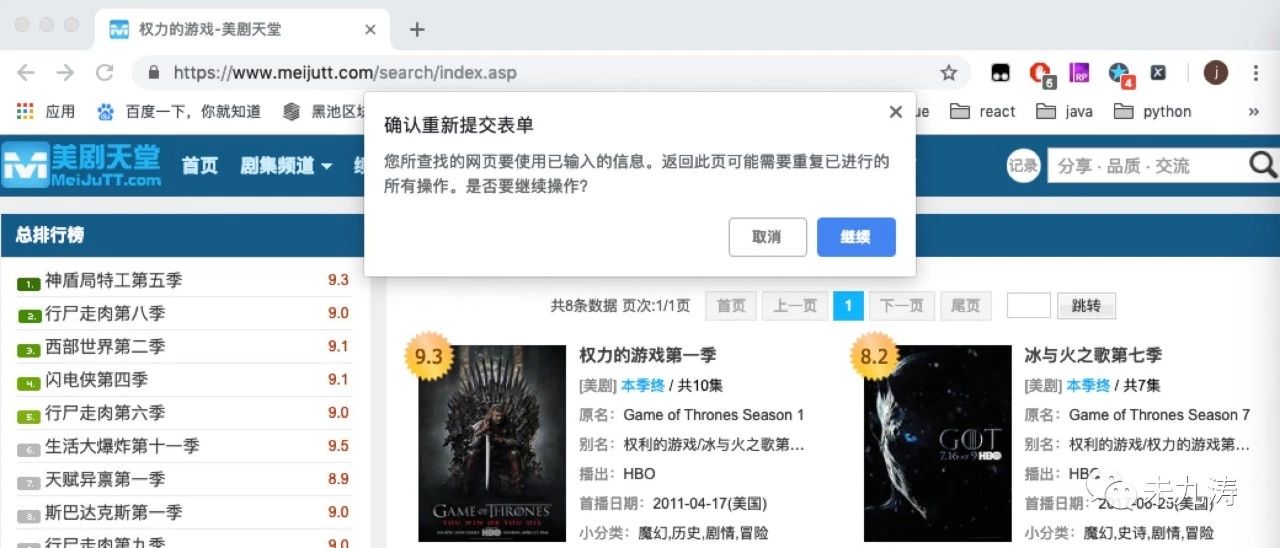
当我们手动输入 ulr 链接https://www.meijutt.com/search/index.asp进行搜索时:
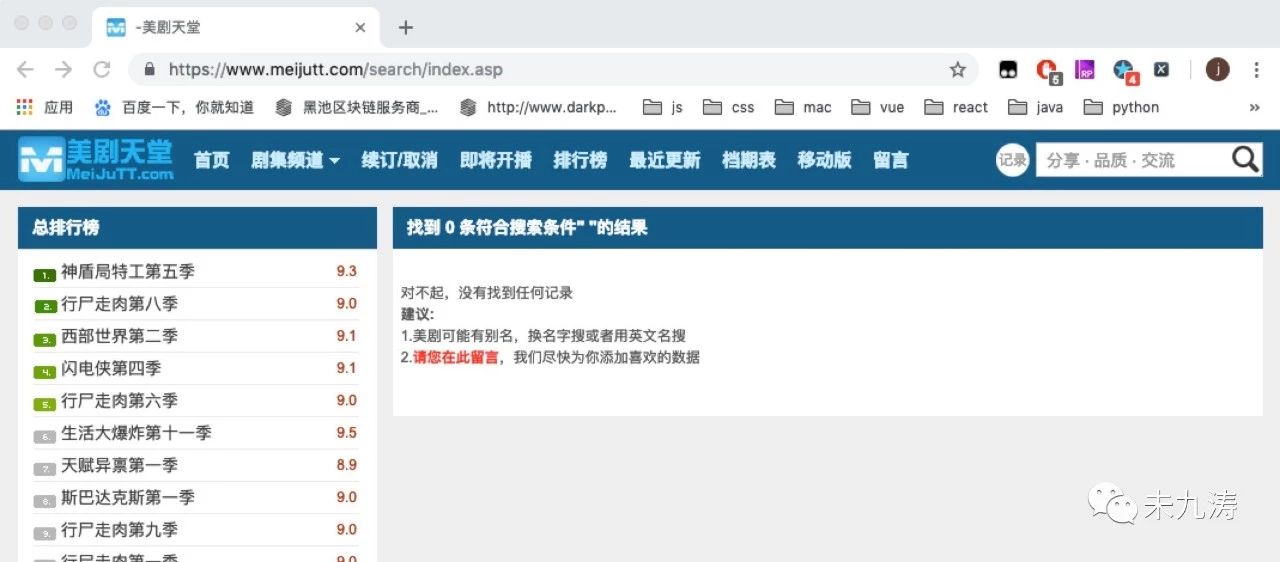
很明显了,当我们在首页输入想看的美剧并搜索时网站将我们的请求表单信息隐藏了,并没有给到 url 链接里,但是本人可不想每次都从首页进行搜索再提交表单获取信息,很不爽,还好本人发现了一个更好的方法。如下图:
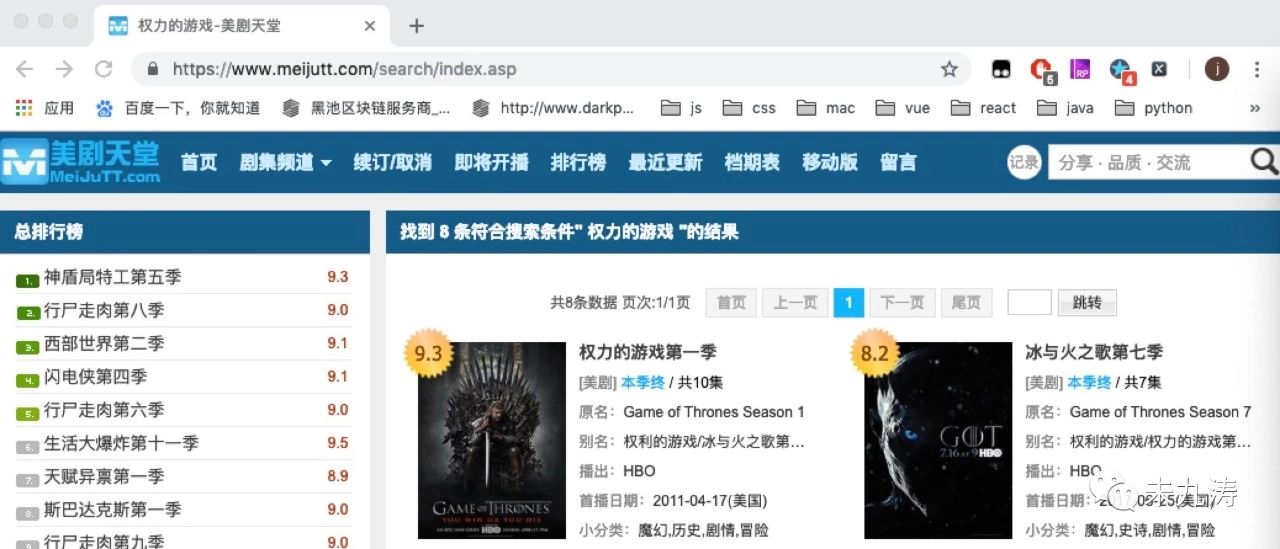
在页面顶部有一个页面跳转的按钮,我们可以选择跳转的页码,当选择跳转页码后,页面变成了如下:
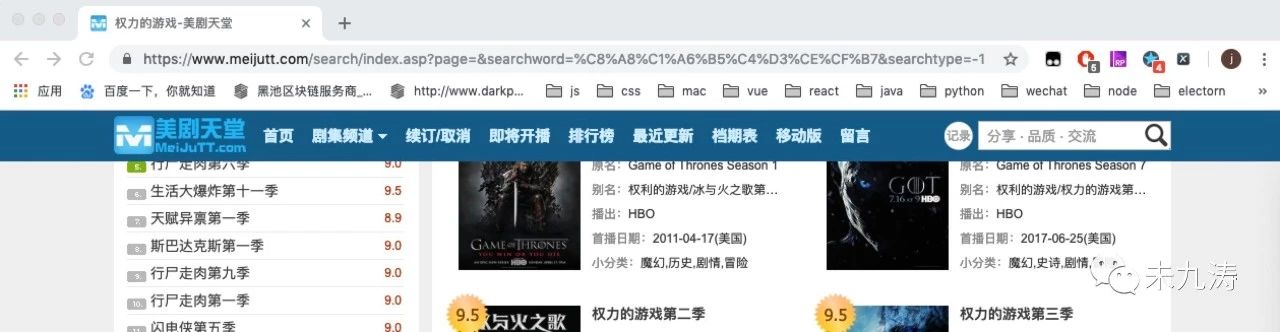
url 链接已经改变了:https://www.meijutt.com/search/index.asp?page=&searchword=%C8%A8%C1%A6%B5%C4%D3%CE%CF%B7&searchtype=-1
我们再将 page 中动态添加为page=1,页面效果不变。
经过搜索多个不同的美剧的多次验证发现只有 page 和 searchword 这两个字段是改变的,其中 page 字段默认为 1 ,而其本人搜索了许多季数很长的美剧,比如《老友记》、《生活大爆炸》、《邪恶力量》,这些美剧也就一页,但仍有更长的美剧,比如《辛普森一家》是两页,《法律与秩序》是两页,这就要求我们对页数进行控制,但是需要特别注意的是如果随意搜索内容,比如在搜索框只搜索了一个 ”i“,整整搜出了219页,这要扒下来需要很长的时间,所以就需要对其搜索的页数进行控制。
我们再来看一下 searchword 字段,将 searchword 字段解码转成汉字:
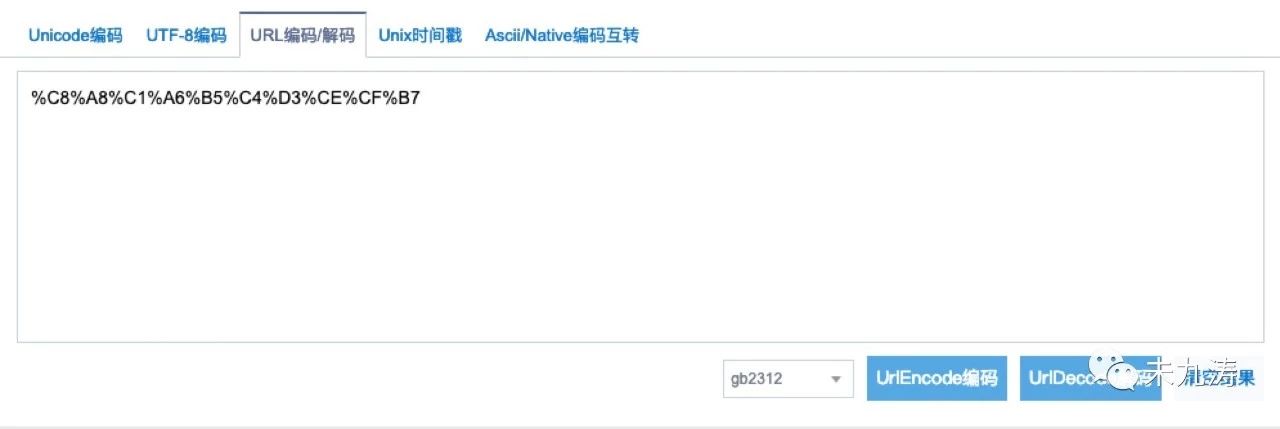
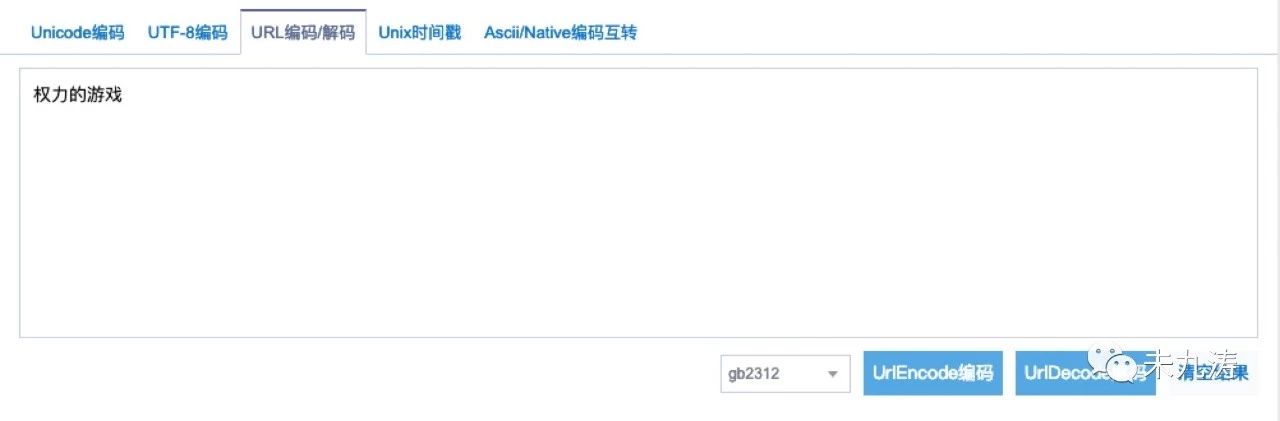
没错,正是我们想要的,万里长征终于实现了第一步。
# 加载输入美剧名称后的页面
def loadSearchPage(self, name, page):
# 将文本转为 gb2312 编码格式
name = parse.quote(name.encode('gb2312'))
# 请求发送的 url 地址
url = "https://www.meijutt.com/search/index.asp?page=" + str(page) + "&searchword=" + name + "&searchtype=-1"
# 请求报头
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
# 发送请求
request = urllib.request.Request(url, headers=headers)
# 获取请求的 html 文档
html = urllib.request.urlopen(request).read()
# 对 html 文档进行解析
text = etree.HTML(html)
# xpath 获取想要的信息
pageTotal = text.xpath('//div[@class="page"]/span[1]/text()')
# 判断搜索内容是否有结果
if pageTotal:
self.loadDetailPage(pageTotal, text, headers)
# 搜索内容无结果
else:
self.infoSearchNull()接下来我们只需要将输入的美剧名转化成 url 编码格式就可以了。如上代码,通过 urllib 库对搜索的网站进行操作。
其中我们还需要做判断,搜索结果是否存在,比如我们搜索 行尸跑肉,结果不存在。
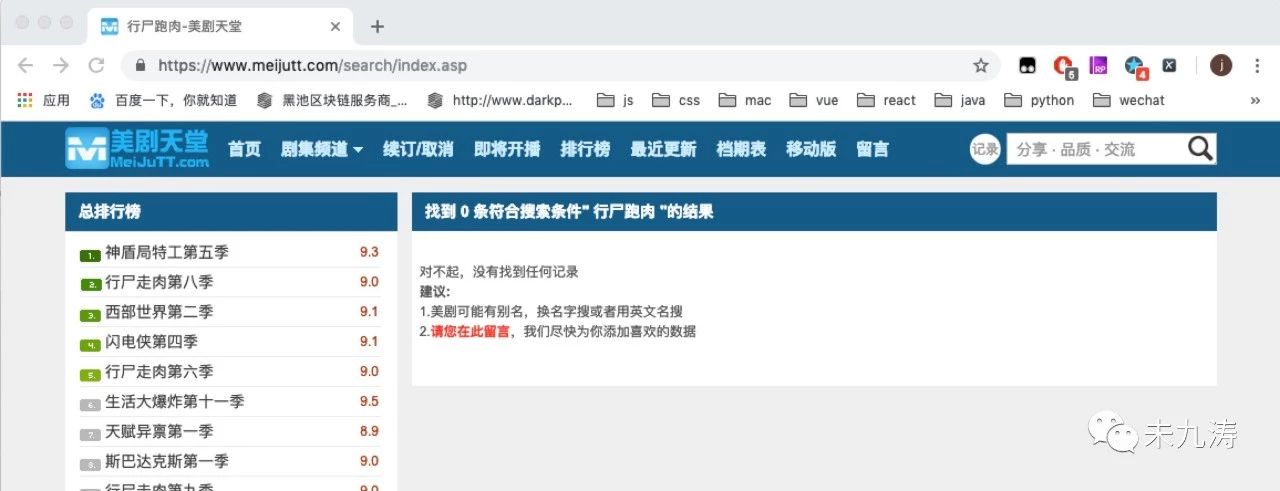
当搜索结果存在时:
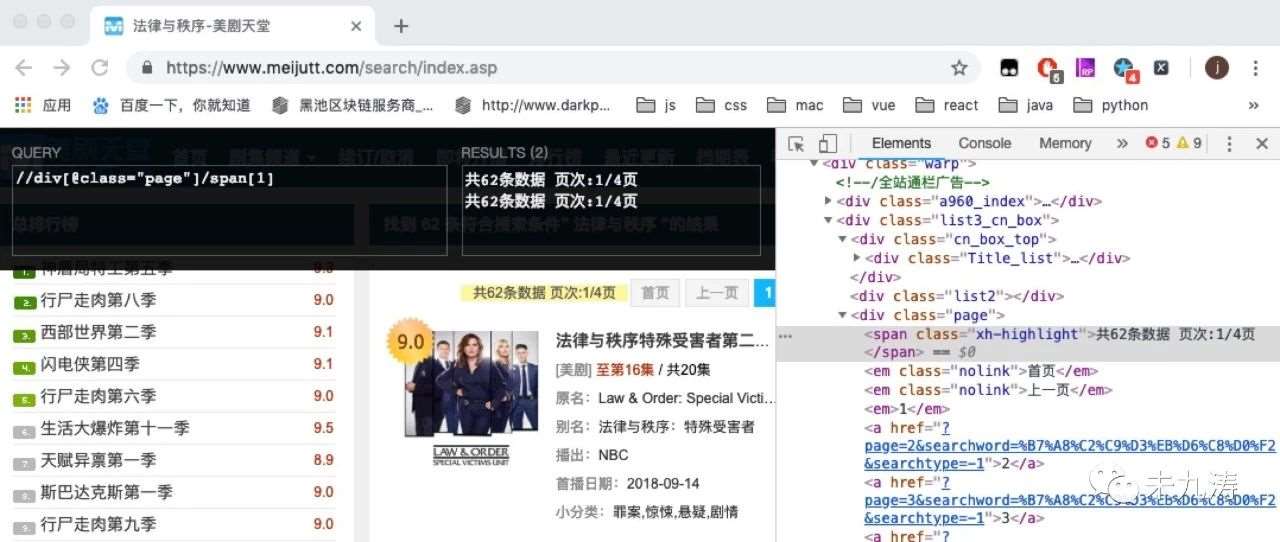
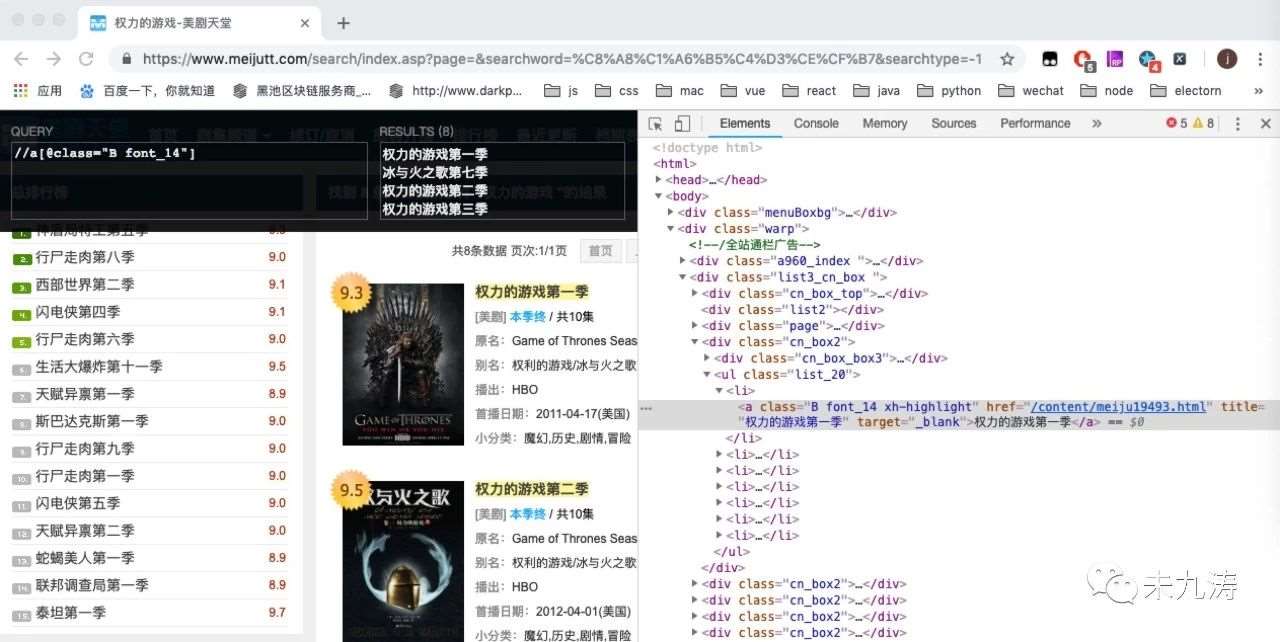
我们通过谷歌的 xpath 插件对页面内的 dom 进行搜索,发现我们要选取的 class 类名。
我们根据获取到的页数,找到所有页面里我们要搜索的信息:
# 加载点击搜索页面点击的本季页面
def loadDetailPage(self, pageTotal, text, headers):
# 取出搜索的结果一共多少页
pageTotal = pageTotal[0].split('/')[1].rstrip("页")
# 获取每一季的内容(剧名和链接)
node_list = text.xpath('//a[@class="B font_14"]')
items = {}
items['name'] = self.textLineEdit.text()
# 循环获取每一季的内容
for node in node_list:
# 获取信息
title = node.xpath('@title')[0]
link = node.xpath('@href')[0]
items["title"] = title
# 通过获取的单季链接跳转到本季的详情页面
requestDetail = urllib.request.Request("https://www.meijutt.com" + link, headers=headers)
htmlDetail = urllib.request.urlopen(requestDetail).read()
textDetail = etree.HTML(htmlDetail)
node_listDetail = textDetail.xpath('//div[@class="tabs-list current-tab"]//strong//a/@href')
self.writeDetailPage(items, node_listDetail)
# 爬取完毕提示
if self.page == int(pageTotal):
self.infoSearchDone()
else:
self.infoSearchContinue(pageTotal)我们根据获取到的链接,再次通过 urllib 库进行页面访问,即我们手动点击进入其中的一个页面,比如 权利的游戏第一季,再次通过 xpath 获取到我们所需要的下载链接:
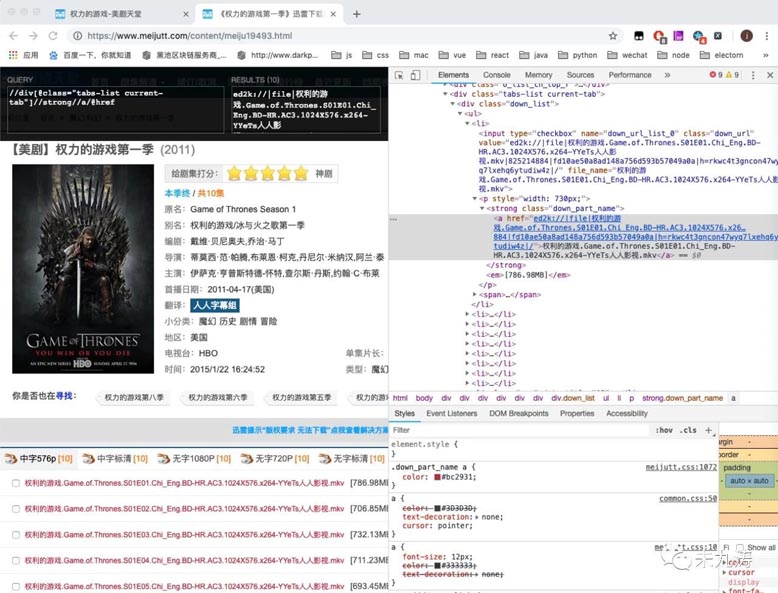
至此我们就将所有我们搜索到的 权力的游戏 的下载链接拿到手了,接下来就是写图形界面了。
本人选用了 PyQt5 这个框架,它内置了 QT 的操作语法,对于本人这种小白用起来也很友好。至于如何使用本人也都在代码上添加了注释,在这儿做一下简单的说明,就不过多解释了。
from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox, QLabel import sys
将获取的信息写入搜索结果内:
# 将数据显示到图形界面 def writeDetailPage(self, items, node_listDetail): for index, nodeLink in enumerate(node_listDetail): items["link"] = nodeLink # 写入图形界面 self.textEdit.append( "<div>" "<font color='black' size='3'>" + items['name'] + "</font>" + "\n" "<font color='red' size='3'>" + items['title'] + "</font>" + "\n" "<font color='orange' size='3'>第" + str(index + 1) + "集</font>" + "\n" "<font color='green' size='3'>下载链接:</font>" + "\n" "<font color='blue' size='3'>" + items['link'] + "</font>" "<p></p>" "</div>" )
因为可能有多页情况,所以我们得做一次判断,提示一下剩余多少页,可以选择继续爬取或停止,做到人性化交互。
# 搜索不到结果的提示信息 def infoSearchNull(self): QMessageBox.information( self, '提示', '搜索结果不存在,请重新输入搜索内容', QMessageBox.Ok, QMessageBox.Ok ) # 爬取数据完毕的提示信息 def infoSearchDone(self): QMessageBox.information( self, '提示', '爬取《' + self.textLineEdit.text() + '》完毕', QMessageBox.Ok, QMessageBox.Ok ) # 多页情况下是否继续爬取的提示信息 def infoSearchContinue(self, pageTotal): end = QMessageBox.information( self, '提示', '爬取第' + str(self.page) + '页《' + self.textLineEdit.text() + '》完毕,还有' + str(int(pageTotal) - self.page) + '页,是否继续爬取', QMessageBox.Ok | QMessageBox.No, QMessageBox.No ) if end == QMessageBox.Ok: self.page += 1 self.loadSearchPage(self.textLineEdit.text(), self.page) else: pass
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





