环境zabbix 4.0 + pgpool + postgres 11.0 cluster + Centos 7.5 +Python2.7.5【3.6】引起故障的原因,PG Master 磁盘空间150G,由于zabbix监控设备众多(约1000个点,模板监控项也较多),导致数据库的归档文件增长速度非常快,通常五分钟左右吃掉一个G的空间。磁盘空间消耗完毕之后,pg&pgpool的服务会停止,进而影响zabbix系统的使用.为了解决这个问题,创建了bash shell 脚本和crontab 任务定时清理归档文件.
1. 登录 postgres : docker run -ti postgres /bin/bash【不是docker环境直接跳过此步骤】
2. 切换到 postgres 用户
3. 执行修复命令:/usr/pgsql-11/bin/pg_resetwal -f /var/lib/pgsql/11/data
【根据环境和安装方式的不同,可能文件路径不同,具体可以使用locate或find 命令搜索 pg_resetwal】
【pg_resetxlog -f DATADIR postgres 低于10.0 以下的版本可以使用该命令;-f 强制执行更新】
4. 如果看到“Write-ahead log reset”,表示修复成功。
# systemctl start postgresql-11.service
# systemctl status postgresql-11.service
# systemctl start pgpool-II-11.service
# systemctl status pgpool-II-11.service
# netstat -pltn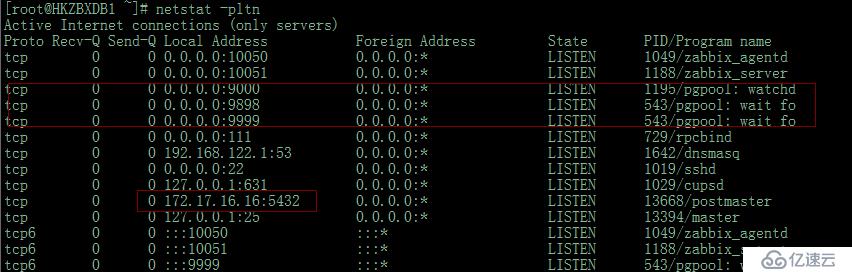
此时PG的服务起来了,但是未必数据库可以正常使用,继续使用命令检查
-bash-4.2$ psql
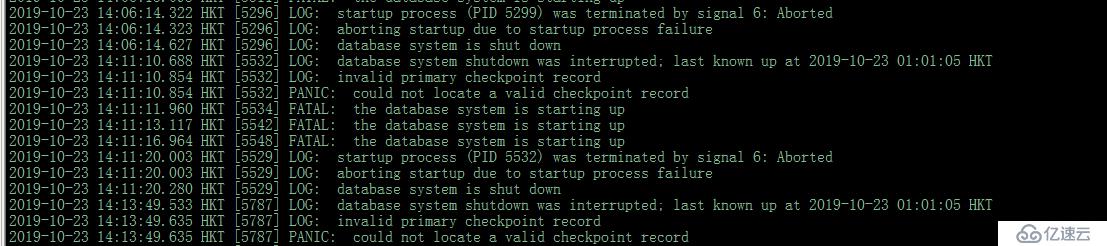
psql: FATAL: xlog flush request 399/FCA1D7D8 is not satisfied --- flushed only to 399/E720DE18
CONTEXT: writing block 2225 of relation base/16385/17835
--此时报的这个错误,可以耐心等待一段时间(约十几分吧),经验而谈pg和pgpool从故障恢复过来都要等一段时间才可正常使用;
-bash-4.2$ psql
psql (11.4)
Type "help" for help.
postgres=# 
备注:只需要点击红色箭头所指“返回/断开连接” & "重新加载“”,集群业务即可恢复使用,比命令行管理方便已维护;免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





