今天就跟大家聊聊有关怎么在MySQL中查询重复数据,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
表结构如下图所示:
表明:brand
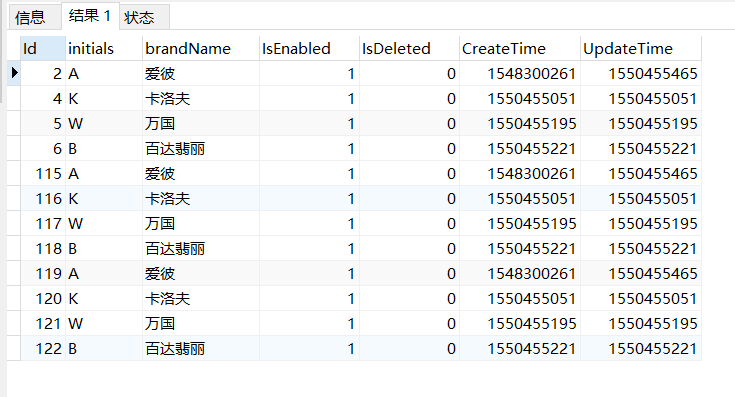
操作:
使用SQL语句查询重复的数据有哪些:
SELECT * from brand WHERE brandName IN(
select brandName from brand GROUP BY brandName HAVING COUNT(brandName)>1 #条件是数量大于1的重复数据
)使用SQL删除多余的重复数据,并保留Id最小的一条唯一数据:
注意点:
错误SQL:DELETE FROM brand WHERE brandName IN (select brandName from brand GROUP BY brandName HAVING COUNT(brandName)>1)
AND Id NOT IN (select MIN(Id) from brand GROUP BY brandName HAVING COUNT(brandName)>1)
提示: You can't specify target table 'brand' for update in FROM clause 不能为FROM子句中的更新指定目标表“brand”
原因是:不能将直接查处来的数据当做删除数据的条件,我们应该先把查出来的数据新建一个临时表,然后再把临时表作为条件进行删除功能
正确SQL写法:
DELETE FROM brand WHERE brandName IN (SELECT brandName FROM (SELECT brandName FROM brand GROUP BY brandName HAVING COUNT(brandName)>1) e)
AND Id NOT IN (SELECT Id FROM (SELECT MIN(Id) AS Id FROM brand GROUP BY brandName HAVING COUNT(brandName)>1) t)
#查询显示重复的数据都是显示最前面的几条,因此不需要查询是否最小值结果如下图:
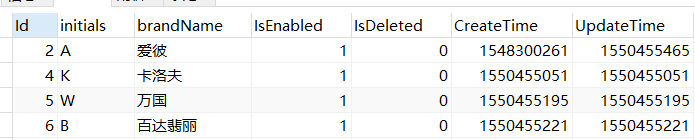
看完上述内容,你们对怎么在MySQL中查询重复数据有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



