PYTHON Pandas批量读取csv文件到DATAFRAME

首先使用glob.glob获得文件路径。然后定义一个列表,读取文件后再使用concat合并读取到的数据。
#读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f in file: dl.append(pd.read_excel(f,header=[0,1],index_col=None)) df=pd.concat(dl)
下面看下Python使用pandas处理CSV文件的方法
Python中有许多方便的库可以用来进行数据处理,尤其是Numpy和Pandas,再搭配matplot画图专用模块,功能十分强大。
CSV(Comma-Separated Values)格式的文件是指以纯文本形式存储的表格数据,这意味着不能简单的使用Excel表格工具进行处理,而且Excel表格处理的数据量十分有限,而使用Pandas来处理数据量巨大的CSV文件就容易的多了。
我用到的是自己用其他硬件工具抓取得数据,硬件环境是在Linux平台上搭建的,当时数据是在运行脚本后直接输出在terminal里的,数据量十分庞大,为了保存获得的数据,在Linux下使用了数据流重定向,把数据全部保存到了文本文件中,形成了一个本地csv文件。
Pandas读取本地CSV文件并设置Dataframe(数据格式)
import pandas as pd
import numpy as np
df=pd.read_csv('filename',header=None,sep=' ') #filename可以直接从盘符开始,标明每一级的文件夹直到csv文件,header=None表示头部为空,sep=' '表示数据间使用空格作为分隔符,如果分隔符是逗号,只需换成 ‘,'即可。
print df.head()
print df.tail()
#作为示例,输出CSV文件的前5行和最后5行,这是pandas默认的输出5行,可以根据需要自己设定输出几行的值
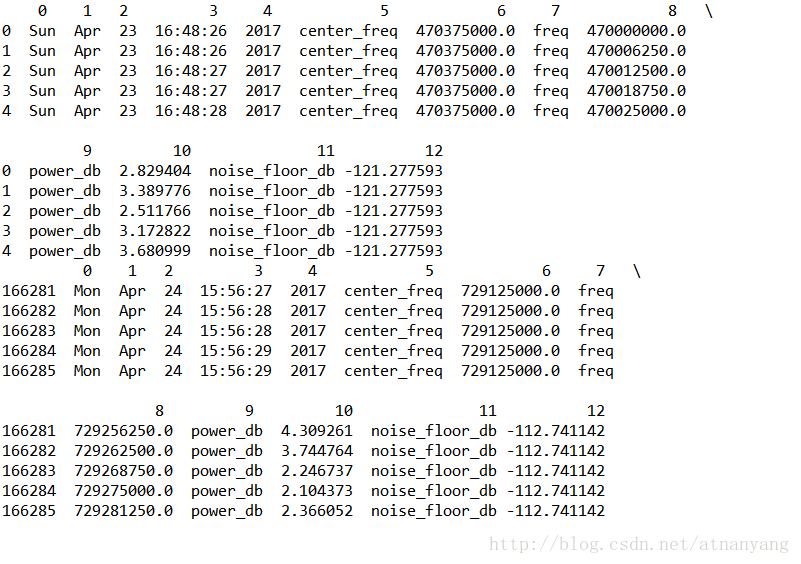
图片中显示了我本地数据的前5行与最后5行,最前面一列没有标号的是行号,数据一共有13列,标号从0到12,一行显示不完全,在第9列以后换了行,并且用反斜杠“\”标注了出来。
2017年4月28日更新
使用pandas直接读取本地的csv文件后,csv文件的列索引默认为从0开始的数字,重定义列索引的语句如下:
import pandas as pd
import numpy as np
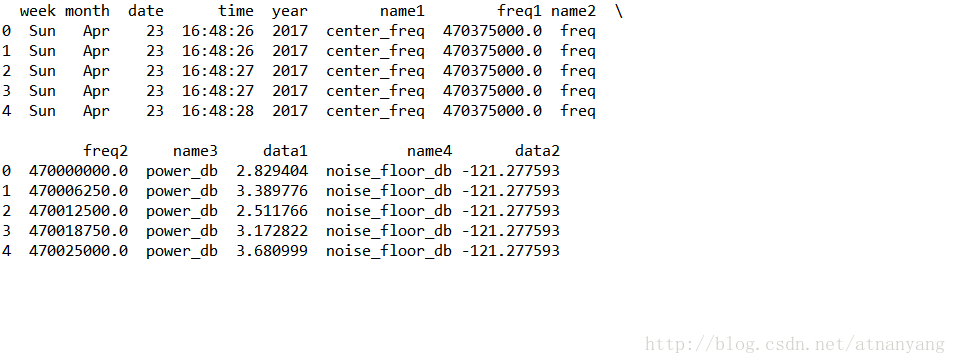
df=pd.read_csv('filename',header=None,sep=' ',names=["week",'month','date','time','year','name1','freq1','name2','freq2','name3','data1','name4','data2'])
print df1234
此时打印出的文件信息如下,列索引已经被重命名:
总结
以上所述是小编给大家介绍的Python Pandas批量读取csv文件到dataframe的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对亿速云网站的支持!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





