NodejsдёӯTcpе°ҒеҢ…е’Ңи§ЈеҢ…зҡ„зӨәдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іNodejsдёӯTcpе°ҒеҢ…е’Ңи§ЈеҢ…зҡ„зӨәдҫӢеҲҶжһҗзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
1гҖҒзІҳеҢ…й—®йўҳи§ЈеҶіж–№жЎҲеҸҠеҜ№жҜ”
еҫҲз®ҖеҚ•пјҢ既然ж¶ҲжҒҜжІЎжңүиҫ№з•ҢпјҢйӮЈжҲ‘们еңЁж¶ҲжҒҜеҫҖдёӢдј д№ӢеүҚз»ҷе®ғеҠ дёҖдёӘиҫ№з•ҢиҜҶеҲ«е°ұеҘҪдәҶгҖӮ
еҸ‘йҖҒеӣәе®ҡй•ҝеәҰзҡ„ж¶ҲжҒҜ
дҪҝз”Ёзү№ж®Ҡж Үи®°жқҘеҢәеҲҶж¶ҲжҒҜй—ҙйҡ”
жҠҠж¶ҲжҒҜзҡ„е°әеҜёдёҺж¶ҲжҒҜдёҖеқ—еҸ‘йҖҒ
第дёҖз§Қж–№жЎҲдёҚеӨҹзҒөжҙ»пјӣ第дәҢз§ҚжңүйЈҺйҷ©пјҢеҰӮжһңж•°жҚ®еҶ…еҲҡеҘҪжңүиҜҘзү№ж®Ҡеӯ—з¬ҰдјҡеҮәй—®йўҳпјӣ第дёүз§Қж–№жЎҲиҷҪ然иҰҒеўһеҠ еҜ№ж¶ҲжҒҜеӨҙзҡ„и§ЈжһҗпјҢдёҚиҝҮзӣёеҜ№иҖҢиЁҖиҝҳжҳҜиҰҒе®үе…ЁдёҖдәӣгҖӮ
2гҖҒеҲҶеҢ…дёҺжӢҶеҢ…
既然дҪҝ用第дёүз§Қж–№жЎҲпјҢе°ұеҝ…然ж¶үеҸҠеҲ°е°ҒеҢ…е’ҢжӢҶеҢ…зҡ„й—®йўҳгҖӮ
йҰ–е…ҲиӮҜе®ҡйңҖиҰҒе®ҡд№үж•°жҚ®еҢ…зҡ„з»“жһ„пјҢиҝҷзұ»дјјHttpеҢ…дёҖж ·пјҢжңүеҢ…еӨҙе’ҢеҢ…дҪ“гҖӮеҢ…еӨҙе…¶е®һдёҠжҳҜдёӘеӨ§е°Ҹеӣәе®ҡзҡ„з»“жһ„дҪ“пјҢе…¶дёӯжңүдёӘз»“жһ„дҪ“жҲҗе‘ҳеҸҳйҮҸиЎЁзӨәеҢ…дҪ“зҡ„й•ҝеәҰпјҢе…¶д»–зҡ„з»“жһ„дҪ“жҲҗе‘ҳеҸҜж №жҚ®йңҖиҰҒиҮӘе·ұе®ҡд№үгҖӮж №жҚ®еҢ…еӨҙй•ҝеәҰеӣәе®ҡд»ҘеҸҠеҢ…еӨҙдёӯеҗ«жңүеҢ…дҪ“й•ҝеәҰзҡ„еҸҳйҮҸе°ұиғҪжӯЈзЎ®зҡ„жӢҶеҲҶеҮәдёҖдёӘе®Ңж•ҙзҡ„ж•°жҚ®еҢ…гҖӮеҢ…дҪ“еҲҷеӯҳж”ҫж•°жҚ®еҶ…е®№гҖӮ
еңЁеҸ‘йҖҒз«ҜпјҢйңҖиҰҒиҝӣиЎҢе°ҒеҢ…гҖӮе°ҒеҢ…е°ұжҳҜз»ҷдёҖж®өж•°жҚ®еҠ дёҠеҢ…еӨҙ,иҝҷж ·дёҖжқҘж•°жҚ®еҢ…е°ұеҲҶдёәеҢ…еӨҙе’ҢеҢ…дҪ“дёӨйғЁеҲҶеҶ…е®№дәҶгҖӮ
еңЁжҺҘеҸ—з«ҜпјҢеҲҷйңҖиҰҒиҝӣиЎҢжӢҶеҢ…гҖӮдё»иҰҒжөҒзЁӢеҰӮдёӢпјҡ
1. дёәжҜҸдёҖдёӘиҝһжҺҘеҠЁжҖҒеҲҶй…ҚдёҖдёӘзј“еҶІеҢә,еҗҢж—¶жҠҠжӯӨзј“еҶІеҢәе’ҢSOCKETе…іиҒ”.
е…¶дёӯеҜ№дәҺзј“еҶІеҢәзҡ„и®ҫи®ЎпјҢдё»иҰҒз”ұдҝ©з§Қпјҡ
1. йҮҮз”ЁеҠЁжҖҒеҸҳеҢ–зҡ„зј“еҶІеҢәжҡӮеӯҳпјҢж №жҚ®ж•°жҚ®еӨ§е°Ҹи°ғж•ҙзј“еҶІеҢәеӨ§е°ҸгҖӮиҝҷдёӘж–№жЎҲжңүдёӘзјәзӮ№пјҢдёәдәҶйҒҝе…Қзј“еҶІеҢәдёҚж–ӯеўһй•ҝпјҢжҜҸж¬Ўи§ЈжһҗеҮәдёҖдёӘе®Ңж•ҙеҢ…еҗҺйңҖиҰҒе°Ҷзј“еҶІеҢәж®Ӣз•ҷзҡ„ж•°жҚ®жӢ·иҙқеҲ°зј“еҶІеҢәйҰ–йғЁпјҢиҝҷеўһеҠ дәҶзі»з»ҹиҙҹиҪҪгҖӮ
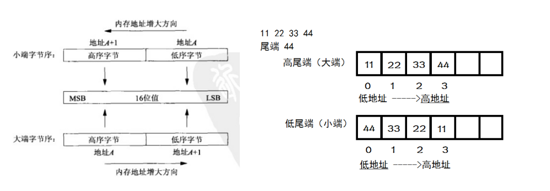
3гҖҒзҪ‘з»ңеӯ—иҠӮеәҸе’Ңжң¬жңәеӯ—иҠӮеәҸ
е®ҡд№үдәҶж¶ҲжҒҜз»“жһ„д№ӢеҗҺпјҢеҸ‘йҖҒз«Ҝе’ҢжҺҘ收з«ҜиҝҳйңҖиҰҒз»ҹдёҖеӯ—иҠӮеәҸгҖӮжҲ‘们зҹҘйҒ“пјҢдёҚеҗҢжңәеҷЁзҡ„жң¬жңәеӯ—иҠӮеәҸдёҚеҗҢпјҢз»қеӨ§еӨҡж•°X86жңәеҷЁйғҪжҳҜе°Ҹз«Ҝеӯ—иҠӮеәҸпјҢ然еҗҺиҝҳжҳҜз”ұе°‘ж•°жңәеҷЁжҳҜеӨ§з«ҜеӯҳеӮЁзҡ„гҖӮеӣ жӯӨеңЁж•°жҚ®жөҒиҝӣиЎҢдј иҫ“ж—¶пјҢеҝ…йЎ»е…Ҳз»ҹдёҖеӯ—иҠӮеәҸгҖӮдёҖиҲ¬зәҰе®ҡеңЁдј иҫ“ж—¶йҮҮз”ЁзҪ‘з»ңеӯ—иҠӮеәҸпјҲеӨ§з«ҜпјүпјҢз»ҹдёҖз”Ёunicodeзј–з ҒгҖӮ
4гҖҒд»Јз Ғе®һзҺ°
дәҶи§Јд»ҘдёҠзҹҘиҜҶд№ӢеҗҺпјҢжҲ‘们зҺ°еңЁд№ӢеҗҺиҰҒеҒҡд»Җд№ҲдәҶгҖӮеҸ‘йҖҒз«ҜжҢүе®ҡд№үзҡ„еҚҸ议规еҲҷе°ҒеҢ…пјҢжҺҘеҸ—з«ҜжҠҠжҺҘ收еҲ°зҡ„bufferж”ҫе…Ҙзј“еҶІеҢәпјҢеҪ“зј“еҶІеҢәеҶ…жңүе®Ңж•ҙеҢ…ж—¶ејҖе§ӢжӢҶеҢ…гҖӮе°ҒеҢ…жӢҶеҢ…иҝҮзЁӢйңҖиҰҒжіЁж„ҸпјҢиҜ»еҶҷи¶…иҝҮдёҖдёӘеӯ—иҠӮзҡ„ж•°жҚ®ж—¶йңҖиҰҒжҢүеӨ§з«Ҝеӯ—иҠӮеәҸиҜ»еҸ–гҖӮдёӢйқўзңӢnodeзҡ„д»Јз Ғе®һзҺ°пјҲеҸӘжҸҗдҫӣж ёеҝғе®һзҺ°зүҮж®өпјүпјҡ
1пјүеҸ‘йҖҒз«Ҝе°ҒеҢ…пјҡ
let head = new Buffer(4);
let jsonStr = JSON.stringify(json);
let body = new Buffer(jsonStr);
//и¶…иҝҮдёҖеӯ—иҠӮзҡ„еӨ§з«ҜеҶҷе…Ҙ
head.writeInt32BE(body.byteLength, 0);
let buffer = Buffer.concat([head, body]); 2пјүжҺҘ收з«Ҝ收еҲ°bufferе…Ҙзј“еҶІеҢәпјҡ
let dataReadStart = 0; //ж–°ж•°жҚ®зҡ„иө·е§ӢдҪҚзҪ®
let dataLength = buffer.length; // иҰҒжӢ·иҙқж•°жҚ®зҡ„й•ҝеәҰ
let availableLen = _bufferLength - _dataLen; // зј“еҶІеҢәеү©дҪҷеҸҜз”Ёз©әй—ҙ
// bufferеү©дҪҷз©әй—ҙдёҚи¶іеӨҹеӯҳеӮЁжң¬ж¬Ўж•°жҚ®
if (availableLen < dataLength) {
let newLength = Math.ceil((_dataLen + dataLength) / _bufferLength) * _bufferLength;
let _tempBuffer = Buffer.alloc(newLength);
// е°Ҷж—§ж•°жҚ®еӨҚеҲ¶еҲ°ж–°buffer并且дҝ®жӯЈзӣёе…іеҸӮж•°
if (_writePointer < _readPointer) { // ж•°жҚ®еӯҳеӮЁеңЁж—§bufferзҡ„е°ҫйғЁ+еӨҙйғЁзҡ„йЎәеәҸ
let dataTailLen = _bufferLength - _readPointer;
_buffer.copy(_tempBuffer, 0, _readPointer, _readPointer + dataTailLen);
_buffer.copy(_tempBuffer, dataTailLen, 0, _writePointer);
} else { // ж•°жҚ®жҳҜжҢүз…§йЎәеәҸиҝӣиЎҢзҡ„е®Ңж•ҙеӯҳеӮЁ
_buffer.copy(_tempBuffer, 0, _readPointer, _writePointer);
}
_bufferLength = newLength;
_buffer = _tempBuffer;
_tempBuffer = null;
_readPointer = 0;
_writePointer = _dataLen;
//еӯҳеӮЁж–°еҲ°жқҘзҡ„buffer
buffer.copy(_buffer, _writePointer, dataReadStart, dataReadStart + dataLength);
_dataLen += dataLength;
_writePointer += dataLength;
} else if (_writePointer + dataLength > _bufferLength) {
// з©әй—ҙеӨҹз”Ёжғ…еҶөдёӢпјҢдҪҶжҳҜж•°жҚ®дјҡеҶІз ҙзј“еҶІеҢәе°ҫйғЁпјҢйғЁеҲҶеӯҳеҲ°зј“еҶІеҢәж—§ж•°жҚ®еҗҺпјҢдёҖйғЁеҲҶеӯҳеҲ°зј“еҶІеҢәејҖе§ӢдҪҚзҪ®
// зј“еҶІеҢәе°ҫйғЁеү©дҪҷз©әй—ҙзҡ„й•ҝеәҰ
let bufferTailLength = _bufferLength - _writePointer;
// ж•°жҚ®е°ҫйғЁдҪҚзҪ®
let dataEndPosition = dataReadStart + bufferTailLength;
buffer.copy(_buffer, _writePointer, dataReadStart, dataEndPosition);
// dataеү©дҪҷжңӘжӢ·иҙқиҝӣзј“еӯҳзҡ„й•ҝеәҰ
let restDataLen = dataLength - bufferTailLength;
buffer.copy(_buffer, 0, dataEndPosition, dataLength);
_dataLen = _dataLen + dataLength;
_writePointer = restDataLen
} else { // еү©дҪҷз©әй—ҙи¶іеӨҹеӯҳеӮЁж•°жҚ®пјҢзӣҙжҺҘжӢ·иҙқж•°жҚ®еҲ°зј“еҶІеҢә
buffer.copy(_buffer, _writePointer, dataReadStart, dataReadStart + dataLength);
_dataLen = _dataLen + dataLength;
_writePointer = _writePointer + dataLength
} 3пјүеҸ–еҮәзј“еҶІеҢәжүҖжңүе®Ңж•ҙж•°жҚ®еҢ…пјҲ收еҲ°зҡ„bufferе…Ҙзј“еҶІеҢәеҗҺпјү
let _dataHeadLen = 4;
timer && clearInterval(timer);
timer = setInterval(()=>{
// зј“еҶІеҢәж•°жҚ®дёҚеӨҹи§ЈжһҗеҮәеҢ…еӨҙ
if (_dataLen < _dataHeadLen) {
console.log('ж•°жҚ®й•ҝеәҰе°ҸдәҺеҢ…еӨҙ规е®ҡй•ҝеәҰпјҢзӯүеҫ…ж•°жҚ®......')
clearInterval(timer);
}
// и§ЈжһҗеҢ…еӨҙй•ҝеәҰ
// е°ҫйғЁжңҖеҗҺеү©дҪҷеҸҜиҜ»еӯ—иҠӮй•ҝеәҰ
let restDataLen = _bufferLength - _readPointer;
let dataLen = 0;
let headBuffer = Buffer.alloc(_dataHeadLen);
// ж•°жҚ®еҢ…дёәеҲҶж®өеӯҳеӮЁпјҢдёҚиғҪзӣҙжҺҘи§ЈжһҗеҮәеҢ…еӨҙпјҢе…ҲжӢјжҺҘ
if (restDataLen < _dataHeadLen) {
// еҸ–еҮә第дёҖйғЁеҲҶеӨҙйғЁеӯ—иҠӮ
_buffer.copy(headBuffer, 0, _readPointer, _bufferLength)
// еҸ–еҮә第дәҢйғЁеҲҶеӨҙйғЁеӯ—иҠӮ
let unReadHeadLen = _dataHeadLen - restDataLen;
_buffer.copy(headBuffer, restDataLen, 0, unReadHeadLen)
dataLen = headBuffer.readUInt32BE(0);
} else {
_buffer.copy(headBuffer, 0, _readPointer, _readPointer + _dataHeadLen);
dataLen = headBuffer.readUInt32BE(0);;
}
// ж•°жҚ®й•ҝеәҰдёҚеӨҹиҜ»еҸ–пјҢзӣҙжҺҘиҝ”еӣһ
if (_dataLen - _dataHeadLen < dataLen) {
log.info("зј“еҶІеҢәе·Іжңүbodyж•°жҚ®й•ҝеәҰе°ҸдәҺеҢ…еӨҙе®ҡд№үbodyзҡ„й•ҝеәҰпјҢзӯүеҫ…ж•°жҚ®......")
clearInterval(timer);
} else { // ж•°жҚ®еӨҹиҜ»пјҢиҜ»еҸ–ж•°жҚ®еҢ…
let package = Buffer.alloc(dataLen);
// ж•°жҚ®жҳҜеҲҶж®өеӯҳеӮЁпјҢйңҖиҰҒеҲҶдёӨж¬ЎиҜ»еҸ–
if (_bufferLength - _readPointer < dataLen) {
let firstPartLen = _bufferLength - _readPointer;
// иҜ»еҸ–第дёҖйғЁеҲҶпјҢзӣҙжҺҘеҲ°еӯ—з¬Ұе°ҫйғЁзҡ„ж•°жҚ®
_buffer.copy(package, 0, _readPointer, firstPartLen + _readPointer);
// иҜ»еҸ–第дәҢйғЁеҲҶпјҢеӯҳеӮЁеңЁејҖеӨҙзҡ„ж•°жҚ®
let secondPartLen = dataLen - firstPartLen;
_buffer.copy(package, firstPartLen, 0, secondPartLen);
_readPointer = secondPartLen; //жӣҙж–°еҸҜиҜ»иө·зӮ№
} else { // зӣҙжҺҘиҜ»еҸ–ж•°жҚ®
_buffer.copy(package, 0, _readPointer, _readPointer + dataLen);
_readPointer += dataLen; //жӣҙж–°еҸҜиҜ»иө·зӮ№
}
_dataLen -= readData.length; //жӣҙж–°ж•°жҚ®й•ҝеәҰ
// е·Із»ҸиҜ»еҸ–е®ҢжүҖжңүж•°жҚ®
if (_readPointer === _writePointer) {
clearInterval(timer)
}
//ејҖе§Ӣи§ЈеҢ…
callback(package);
}
}, 50); 4пјүжӢҶеҢ…еҫ—еҲ°ж•°жҚ®
let headBytes = 4;
let head = new Buffer(headBytes);
buffer.copy(head, 0, 0, headBytes);
let dataLen = head.readUInt32BE();
const body = new Buffer(dataLen);
buffer.copy(body, 0, headBytes, headBytes + dataLen)
let content = null;
try {
const str = body.toString('utf-8');
if(str === ''){
content = null;
}else{
content = JSON.parse(body);
}
} catch (e) {
log.error('headжҢҮе®ҡbodyй•ҝеәҰжңүй—®йўҳ')
}
//дј йҖ’з»ҷдёҡеҠЎеұӮ
callback(content); ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңNodejsдёӯTcpе°ҒеҢ…е’Ңи§ЈеҢ…зҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ