Sed是文本处理工具,依赖于正则表达式,可以读取文本内容,根据指定条件对数据进行添加、删除、替换等操作,广泛应用于shell脚本,以完成自动化处理任务。
Sed在处理数据时默认不直接修改源文件,而是把当前处理的行存储在临时缓冲区中,所有指令都在缓冲区中操作,处理完成后,把缓冲区内容默认输出到屏幕,接着处理下一行内容,这样不断重复,直到文件末尾,文件本身内容并没有做任何改变。
一、Sed三大功能:
(1)读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中;
(2)执行:默认情况下,所有的 sed 命令都在模式空间中顺序地执行,除非指定了行的地址,否则 sed 命令将会在所有的行上依次执行;
(3)显示:发送修改后的内容到输出流,再发送数据后,模式空间将会被清空。
***注意:默认情况下,所有的 sed 命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。
二、Sed命令两种格式:
其中,“参数”是指操作的目标文件,当存在多个操作对象时用,文件之间用逗号“,”分隔;而 scriptfile 表示脚本文件,需要用“-f”选项指定,当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。
sed [选项] ‘操作’ 参数
sed [选项] -f scriptfile 参数
(1)常见的 sed命令选项:-e :表示用指定命令或者脚本来处理输入的文本文件;
-f :表示用指定的脚本文件来处理输入的文本文件;
-h :显示帮助;
-n :表示仅显示处理后的结果;
-i :直接编辑文本文件;
(2)常见的操作选项:
a:增加,在当前行下面增加一行指定内容;
c:替换,将选定行替换为指定内容;
d:删除,删除选定的行;
i :插入,在选定行上面插入一行指定内容;
p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容,通常与 -n选项一起使用;
s :替换,替换指定字符;
y :字符转换;
一、awk简介:
在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互的情况下实现相当复杂的文本操作,被广泛应用于 Shell 脚本,完成各种自动化配置任务。
二、常见用法:
单引号加上大括号“{}”用于设置对数据进行的处理动作。awk 可以直接处理目标文件,也可以通过“-f”读取脚本对目标文件进行处理。
awk 将文本文件中的一行视为一个记录,而将一行中的某一部分(列)作为记录中的一个字(域)。为了操作这些不同的字段,awk 借用 shell 中类似于位置变量的方法, 用$1、$2、$3…顺序地表示行(记录)中的不同字段。另外 awk 用$0 表示整个行(记录)。不同的字段之间是通过指定的字符分隔。awk 默认的分隔符是空格。awk 允许在命令行中用“-F 分隔符”的形式来指定分隔符。
awk 【选项】‘模式或条件 {编辑指令}’ 文件1 文件2
awk -f 脚本文件 文件1 文件2
1)特殊的内建变量(可直接用)
FS:指定每行文本的字段分隔符,默认为空格或制表位(tab键);
NF:当前处理的行的字段个数;
NR:当前处理的行的行号(序数);
$0:当前处理的行的整行内容;
$n:当前处理行的第 n 个字段(第 n 列);
FILENAME:被处理的文件名;
RS:数据记录分隔,默认为\n,即每行为一条记录;
(2)关系运算符号:只有当条件为真,才执行指定的动作。
大于(>);小于(<);大于等于(>=);小于等于(<=);
等于(==)、不等于(!=);
&&(与)、||(或)、!(非);
加(+)、减(-)、乘(*)、除(/)、取余(%)、乘方(^);
一、grep命令
-n: 表示显示行号
-i : 表示不区分大小写刷选
-v : 表示方向查找
(1)查找特定的字符:
grep -n 'the' abc.txt //查找有the的行,并显示出行号
1
grep -in ‘the’ abc.txt //不区分大小写查找有the的行,并显示行号
1
如果是想查找不包含the的行,-vn选项即可:
grep -vn ‘the’ abc.txt //查找不包括the的行,并显示出行号
1
(2)中括号 [ ] 查找集合字符:
例如:当我们需要查找两个字符 “aboyz” 和 “abiyz” 这两个字符时,其中ab和yz都是相同的,可以利用 [ ]来匹配字符,[ ]中不论有几个字符,都仅代表一个字符,
元字符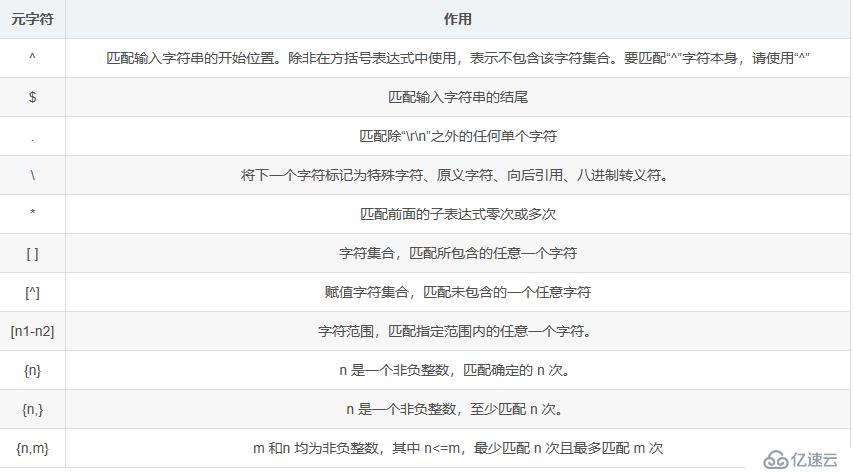
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





