本文实例讲述了Python基于pyCUDA实现GPU加速并行计算功能。分享给大家供大家参考,具体如下:
Nvidia的CUDA 架构为我们提供了一种便捷的方式来直接操纵GPU 并进行编程,但是基于 C语言的CUDA实现较为复杂,开发周期较长。而python 作为一门广泛使用的语言,具有 简单易学、语法简单、开发迅速等优点。作为第四种CUDA支持语言,相信python一定会 在高性能计算上有杰出的贡献–pyCUDA。

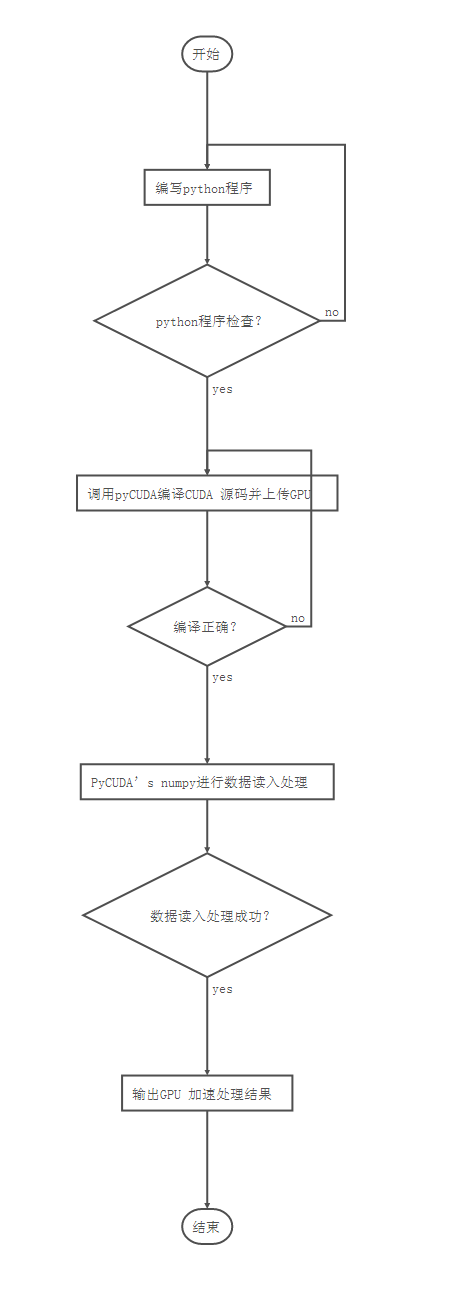
具体的调用流程如下:
import pycuda.autoinit
import pycuda.driver as drv
import numpy
from pycuda.compiler import SourceModule
mod = SourceModule("""
__global__ void multiply_them(float *dest, float *a, float *b)
{
const int i = threadIdx.x;
dest[i] = a[i] * b[i];
}
""")
multiply_them = mod.get_function("multiply_them")
a = numpy.random.randn(400).astype(numpy.float32)
b = numpy.random.randn(400).astype(numpy.float32)
dest = numpy.zeros_like(a)
multiply_them(
drv.Out(dest), drv.In(a), drv.In(b),
block=(400,1,1), grid=(1,1))
print dest-a*b
#tips: copy from hello_gpu.py in the package.
补充内容:
对于GPU 加速python还有功能包,例如处理图像的pythonGPU加速包—— pyGPU
以及专门的GPU 加速python机器学习包—— scikitCUDA
Matlab对应的工具包并行计算工具箱和GPU计算技术
以及教程和介绍文档
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



