一、正则表达式:
正则表达式(regular expression, RE)是一种字符模式,用于在查找过程中匹配指定的字符。在大多数程序里,正则表达式都被置于两个正斜杠之间;例如/l[oO]ve/就是由正斜杠界定的正则表达式,正则表达式具备很强大的文本匹配功能,能够在文本海洋中快速高效地处理文本。
它将匹配被查找的行中任何位置出现的相同模式。在正则表达式中,元字符是最重要的概念。
二、元字符:
定义:元字符是这样一类字符,它们表达的是不同于字面本身的含义
shell 元字符(也称为通配符) 由 shell 来解析,如 rm -rf *.pdf,元字符* Shell 将其解析为任意多个字符
正则表达式元字符 由各种执行模式匹配操作的程序来解析,比如 vi、grep、sed、awk、python
1、正则表达式的分类:
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用的正则表达式的最基础的部分。
在 Linux 系统中常见的文件处理工具中 grep 与 sed 支持基础正则表达式,而 egrep 与 awk 支持扩展正则表达式。
==基本正则表达式元字符(gerp)
元字符 功能 示例
^ 行首定位符: ^love
$ 行尾定位符 :love$
. 匹配单个字符 :l..e
* 匹配前导符 0 到多次: ab*love
.* 任意多个字符
[] 匹配指定范围内的一个字符: [lL]ove
[ - ] 匹配指定范围内的一个字符: [a-z0-9]ove
[^] 匹配不在指定组内的字符 :[^a-z0-9]ove
\ 用来转义元字符 :love\.
\< 词首定位符 :\<love
\> 词尾定位符 :love\>
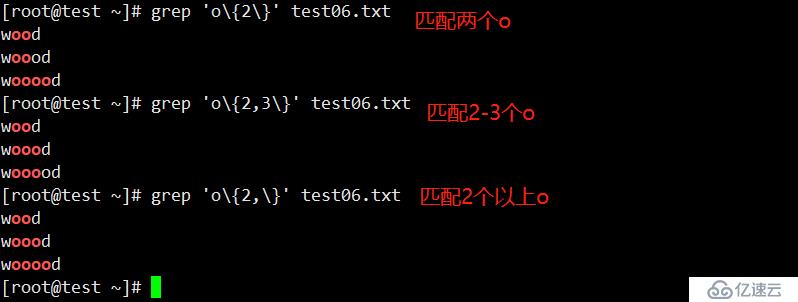
x\{m\} 字符 x 重复出现 m 次: o\{5\}
x\{m,\} 字符 x 重复出现 m 次以上: o\{5,\}
x\{m,n\} 字符 x 重复出现 m 到 n 次: o\{5,10\}“*”仅匹配前导符这一个字符

“[ ]”匹配范围内一个字符

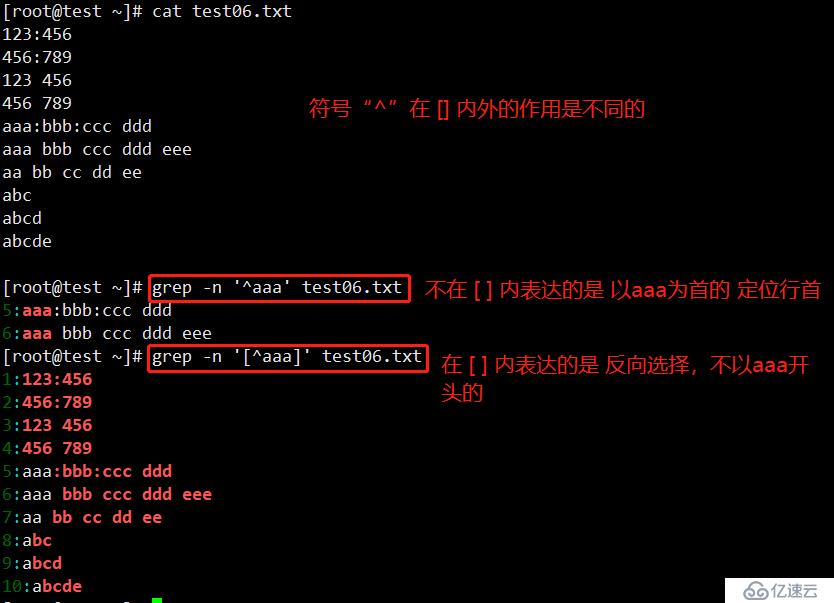
“^”在元字符集合“[ ]”符号内外的作用不同
转义符“\”的使用,及特殊元字符的使用

{}限定匹配个数
===扩展正则表达式元字符(egrep)
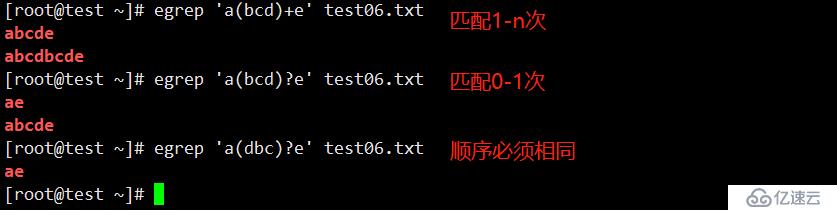
+ 匹配一个或多个前导字符 [a-z]+ove
? 匹配零个或一个前导字符 lo?ve
a|b 匹配 a 或 b love|hate
() 组字符 loveable|rs love(able|rs) ov+
(..)(..)\1\2 标签匹配字符 (love)able\1er
x{m} 字符 x 重复 m 次 o{5}
x{m,} 字符 x 重复至少 m 次 o{5,}
x{m,n} 字符 x 重复 m 到 n 次 o{5,10}()匹配()里的所有字符,顺序相同
2、文本处理器:在 Linux 系统中常见的文件处理工具中 grep 与 sed 支持基础正则表达式,而 egrep 与 awk 支持扩展正则表达式。
grep/egrep:过滤,查找。
grep [选项] ‘操作’ 参数
常用选项
-n:显示行号 -i:不分大小写 -v:反向查找 -c:统计数量
awk与sed请看下章。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





