这篇文章将为大家详细讲解有关利用python处理百万条数据的案例,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
1、前言
因为负责基础服务,经常需要处理一些数据,但是大多时候采用awk以及java程序即可,但是这次突然有百万级数据需要处理,通过awk无法进行匹配,然后我又采用java来处理,文件一分为8同时开启8个线程并发处理,但是依然处理很慢,处理时长起码在1天+所以无法忍受这样的处理速度就采用python来处理,结果速度有了质的提升,大约处理时间为1个小时多一点,这个时间可以接受,后续可能继续采用大数据思想来处理,相关的会在后续继续更新。
2、安装python
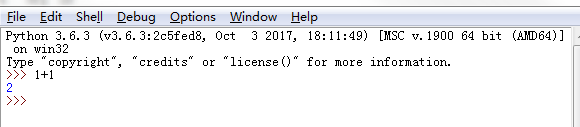
第一步首先下载python软件,在官网可以根据自己情况合理下载,大家也可以通过亿速云进行下载其余就是下一步搞定,然后在开始里面找到python的exe,点击开然后输入1+1就可以看出是否安装成功了.如下图
3、IEDA编辑器如何使用python
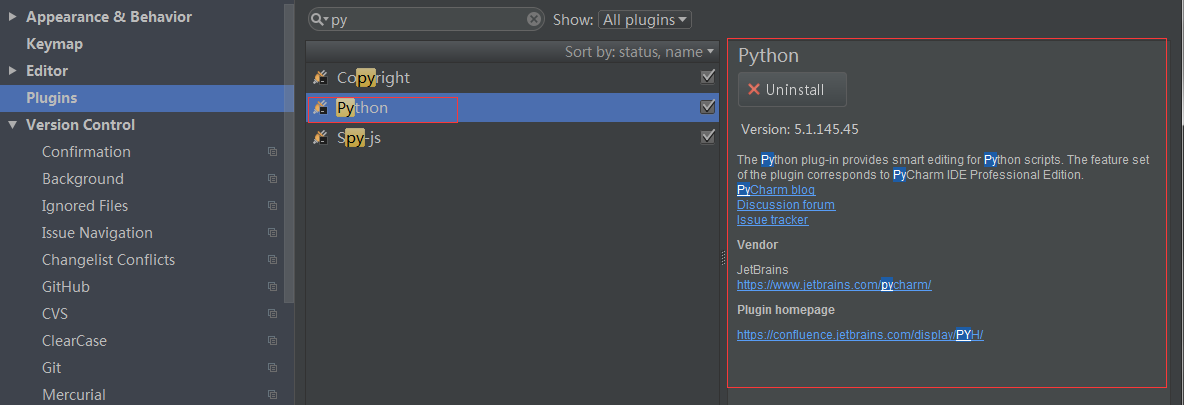
首先我们在idea中打开设置然后点击plugins,在里面有个输入框中输入python,根据提示找到如下的这个(idea版本不同可能影响python版本)
然后开始创建idea工程
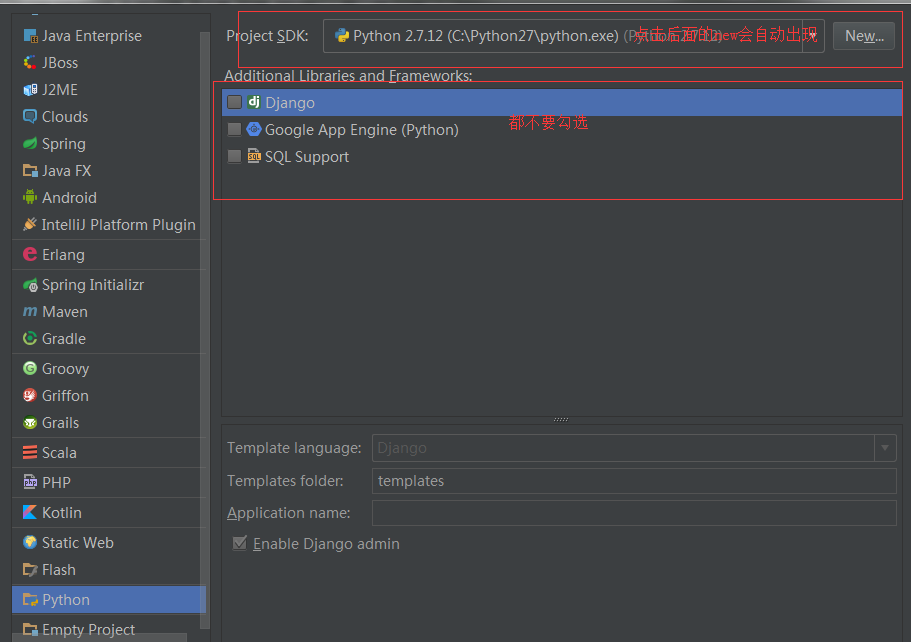
file->New->Project->python然后出现如下图情况(其他的下一步然后就会创建工程了)
4、开发前知识准备
文件的读取,python读取文件非常的简单,我现在直接贴代码提供给大家
def readData(fileName): result = "" count=0 with open(fileName, 'r') as f: for line in f.readlines(): result += line count += 1 print count return result """写入文件""" def writeData(fileName, data): with open(fileName, 'a+')as f: f.write(data)
其中def是函数的定义,如果我们写定义一个函数直接前面加上def,返回值可以获取后直接用return即可
python我们直接采用with open('文件路径',模式) as f的方式来打开文件
模式:
| r | 只读 | 文件不存在则出错 |
| r+ | 支持读写 | 文件不存在则出错,写入时,会覆盖源文件 |
| w | 只写 | 如果文件不存在则创建文件,会覆盖源文件,如果写入内容少则保留为覆盖的内容 |
| w+ | 支持读写 | 同上 |
| a | 只写 | 如果文件不存在则创建文件,会采用追加模式 |
| a+ | 读写 | 同上 |
| b | 二进制读写 |
跨文件引用:
同一个层级python是采用import直接导入文件名的方式,看下一个代码
import IoUtils
fileName1 = 'D:\\works\\pythons\\files\\userids.txt'
userIds = IoUtils.readData(fileName1).split('\n')
fileName2 = 'D:\\works\\pythons\\files\\records.txt'
records = IoUtils.readData(fileName2).strip()
recordsArr = records.split('\n')
count=0;
for data in recordsArr:
count+=1
if data.split('\t')[2] in userIds:
IoUtils.writeData('D:\\works\\pythons\\files\\20180604.txt', data + '\n')
print count其他说明:
其中split和java程序的split一样,strip是去掉空格换行符等,循环(for in)模式,判断某个元素是否在数组中存在则直接使用 元素 in 数组
关于“利用python处理百万条数据的案例”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





