最近这段时间连续两次处理同一客户的Skype前端服务不能启动的问题,客户的环境总是会有前端服务器意外关机的情况出现,每次处理都会浪费大把时间。今天系统的梳理下Skype for business Server前端的工作原理,以及对应的排错过程。
Skype for Business Server前端高可用是基于Windows Fabric进行的,Windows Fabric不需要手动安装,在规划拓扑和安装Skype for business Server组件的时候会自动安装这个Windows功能并进行自动配置。可以在每台FE服务器上打开如下文件夹查看整个Fabric的配置。
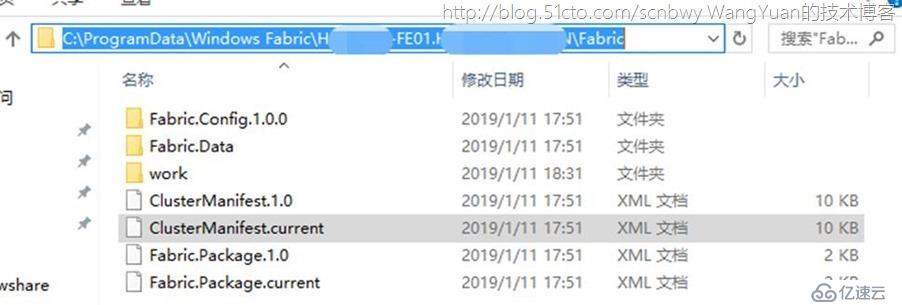
ClusterManifest.current文件是在每次Windows系统重启后会自动生成一个且会覆盖之前的文件,所以千万不要去手动更改里面的配置,如果手动更改配置会导致路由仲裁丢失严重会导致池仲裁丢失,最终导致整个池故障客户端将无法登录任何一台FE服务器。

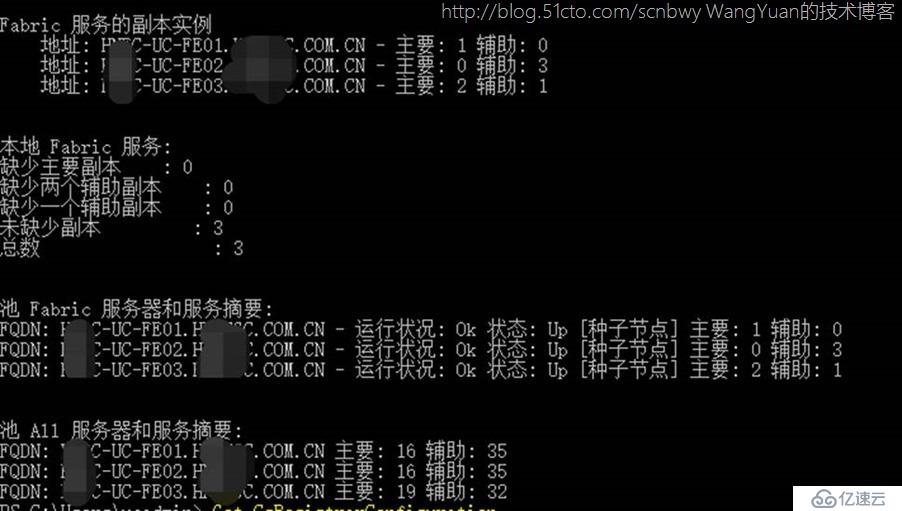
使用Get-CsUserPoolInfo可以清楚的查看到用户当前所在的池,以及池中主要的前端服务器是哪一台
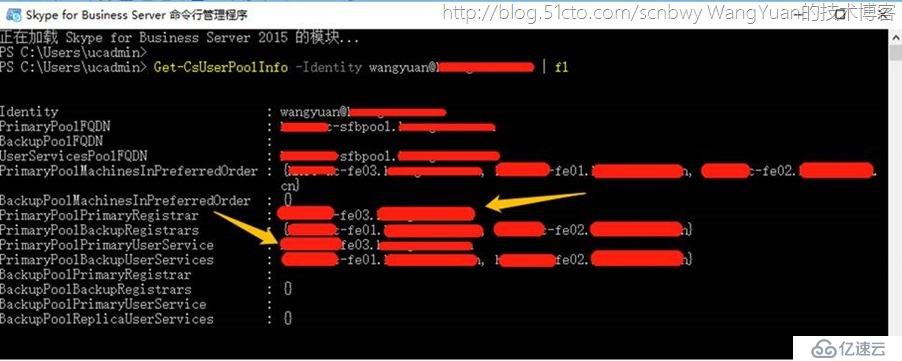
主要注册服务器 是FE03
主要用户服务服务器 是FE03
次要服务器是FE01
空闲服务器是FE02
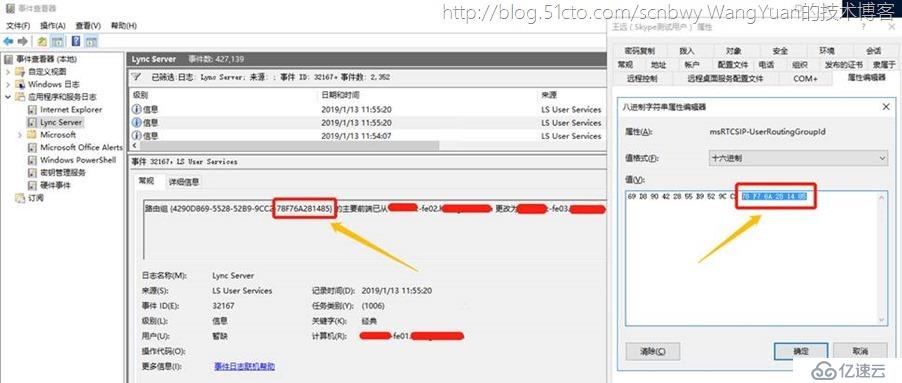
从事件查看器中也看到主要的服务器从FE02转到FE03,同时用户属性的msRTCSIP-UserRoutingGroupID值也是指向到FE03的路由组,这些路由组都是存放到FE前端服务器的SQL数据库中,并不依赖后端SQL
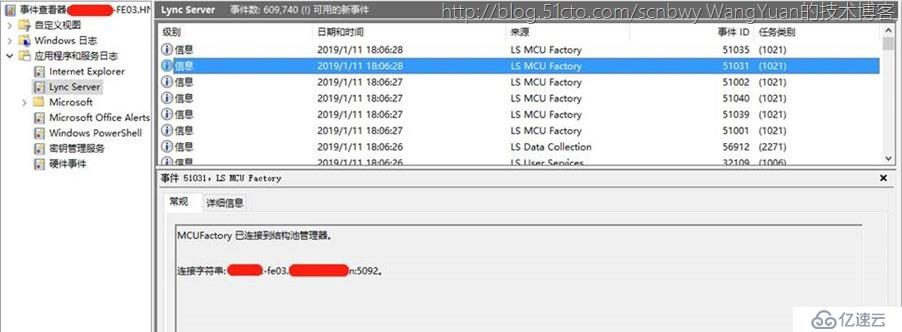
所以可以看出来整个前端高可用基于Windows Fabric,而Fabric基于路由组来进行主服务器的分发,而这一切都是基于FE前端进行的。
而根据微软官方文档的描述知道前端服务器有偶数台或奇数台服务器,如果是奇数台前端服务器,Fabric路由仲裁将在这几台前端服务器中进行自我投票,如果是偶数台前端服务器那么路由投票将会增加一个后端SQL成员,如果这时候后端数据库使用的是SQL镜像技术,而这时候SQL服务器又要参与前端FE Fabric路由投票,而如果此时将主服务器故障转移到镜像服务器上那么投票将会失败,进而导致整个前端服务停掉。
所以如果最好可以选择前端池中有奇数台前端服务器。
前面讲到了Fabric是基于前端服务器来进行的,而后端数据库是提供整个前端服务的基础,如果手动关闭后端数据库其实可以发现一个有意思的现象那就是Skype客户端将继续正常使用,当达到一定时间后就再也无法使用了,通过Get-CsRegistrarConfiguration命令查询其实可以发现在没有后端SQL的情况下Skype前端依然可以存活30分钟,当然也可以通过Set-CsRegistrarConfiguration去修改这个存活时间,但是微软官方并不建议这样做。
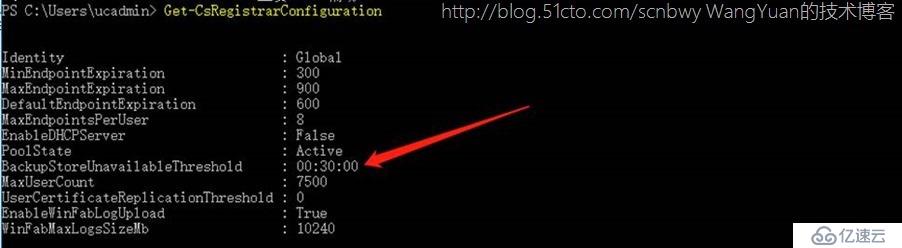
以上就分析了Fabric的路由仲裁及投票,以及存在后端SQL的必然性。那么有些同学就要有疑问了,是不是Skype前端高可用必须是3台?这个答案我更想说:如果要实现前端的高可用那么前端服务器至少需要3台服务器(当然最多只能有12台服务器)
但是更多的乙方工程师在项目实施的时候是在前端池中创建的两台服务器,这样一来就不能满足Windows Fabric的基本条件,无法实现主要服务器,次要服务器,空闲服务器。这时候相当于每一台前端都是直连后端数据库了,而不会像我前面所说的那样后端数据库宕机的情况下会有存活时间,而是Skype客户端立刻进入断开状态导致无法使用。
接下来我跟大家分享一下最近接连两次处理同一客户三台前端全部同时宕机导致整个Windows Fabric路由仲裁,池仲裁全部丢失的情况下怎么恢复前端服务运行正常。
先描述下事情的经过:某天客户的Vmware虚拟化平台宿主机报警资源不足,需要将虚拟机迁移到另外的宿主机上,3台前端服务器进行同时迁移,这个并没有什么问题,悲剧的是Vmware在迁移过程中物理服务器压力过大直接崩了,导致三台前端服务器全部意外关机,要知道这个是对Windows Fabric最大的伤害,手动迁移后重新启动Skype前端虚拟机预料中的情况出现了,Skype前端服务器上所有的服务都无法启动,客户慌了,项目经理也慌了,客户给出的处理时间是3个小时,因为3小时后整个集团领导将使用Skype进行音视频通话。
我刚得到这个消息的时候,其实压力是非常大的,但是基于之前已经处理过一次这种问题,首先也找到客户沟通,第一件绝对不能做的事情就是恢复虚拟机的快照,因为一恢复快照整个前端的高可用架构就全部乱套了,无形之中增加了解决问题的难度。
接下来我的操作过程如下:
首先手动启动整个前端服务器上的所有Skype服务,发现没有一个可以启动,而事件查看器中一大堆报错,都是因为无法连接到后端数据库,前端结构池无法正常启动之类的。
接下来切到SQL服务器上(SQL做了镜像高可用),解决所有SQL数据库服务不能正常运行。
然后肯定就是重置前端的结构池了,通过Reset-CsPoolRegistrarState命令来进行重置。而这条命令后面跟的-ResetType参数有以下类型:
ServiceReset:意思是停止并重新启动RtcSrv和FabricHostSvc服务
QuorumLo***ecovery:意思是为当前处于仲裁丢失的任何路由组重新加载备份存储中的用户数据
FullReset:将会执行与QuorumLo***ecovery相同类型的重置,但此外,还重建本地Skype for Business Server数据库
MachineStateRemoved:从池中删除指定的服务器。仅当有问题的服务器(或其数据库)已永久丢失时,才应使用此类型的重置。
其中FullReset参数我至今没有使用过,这算是一个大绝招,因为风险实在太大了,所以微软官网都贴出了这样一句话:在使用FullReset时最好先咨询微软技术工程师。

而我首先的尝试是使用ServiceReset参数,通过重启Fabric服务来重新规整整个路由,然后重新启动整个前端服务,在执行完命令后惊喜的发现除了Skype for Business Server前端服务意外的所有服务都已经启动了,业内人士都知道前端服务如果没有运行起来,那么所有的客户端将无法登录进而无法使用Skype。

此时回到日志中查看依然显示的错误警告是结构池没有完成用户初始化
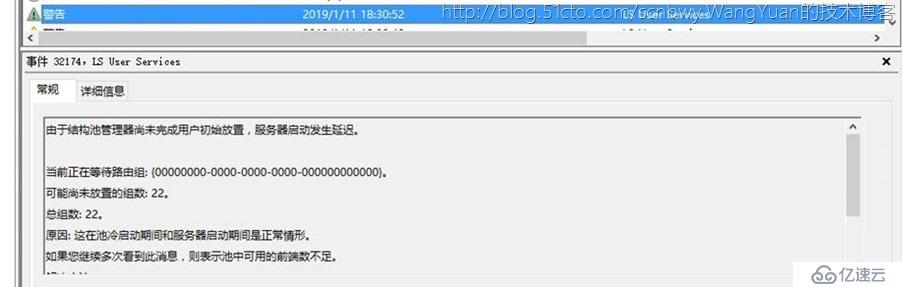
意思就是虽然上面的ServiceReset参数重置了路由组,但是这个路由组并没有加载到结构池中去,那么接下来就进行QuorumLo***ecovery命令,直接从备份的存储中重新加载用户数据。

在运行完命令后会重置整个Windows Fabric和重建整个存储服务。但是此时Skype for business Server前端服务并不见的会启动,因为文章一开始就说了Windows Fabric的配置是每次重启机器后自动会生成一个ClusterManifest.current的XML文件里面都是配置整个Windows Fabric的主要服务器次要服务器和空闲服务器以及整个路由和仲裁,而且手动更改的文件是无效的,所以最好的也是最靠谱的解决方法是等待Skype前端服务器自动停止后将所有前端服务器关机,然后再依次开机,开机后让三台前端自动去进行Windows Fabric的路由仲裁投票和结构池仲裁重新设定(这个过程花费的时间视前端服务器数量而定,我这里3台前端总共等待了大约30分钟)
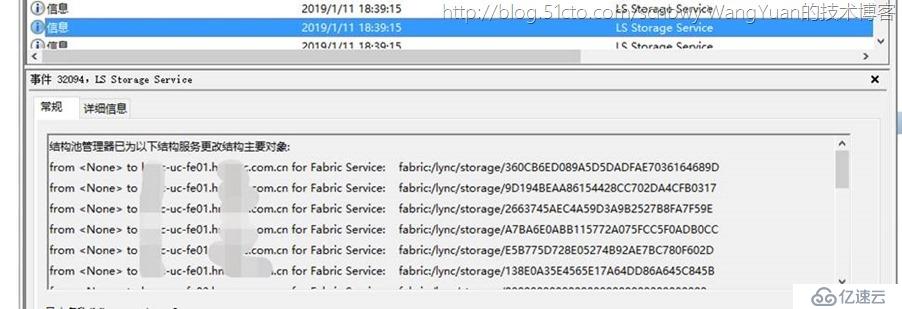
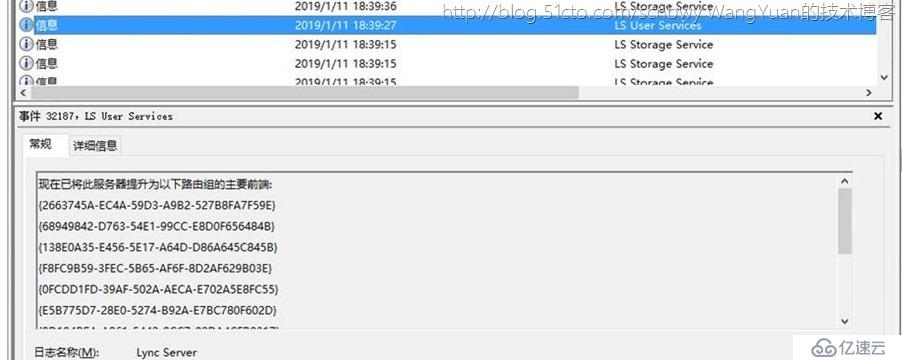
最终将所有结构池和路由仲裁全部自动设定正常,Skype for Business Server前端服务正常运行
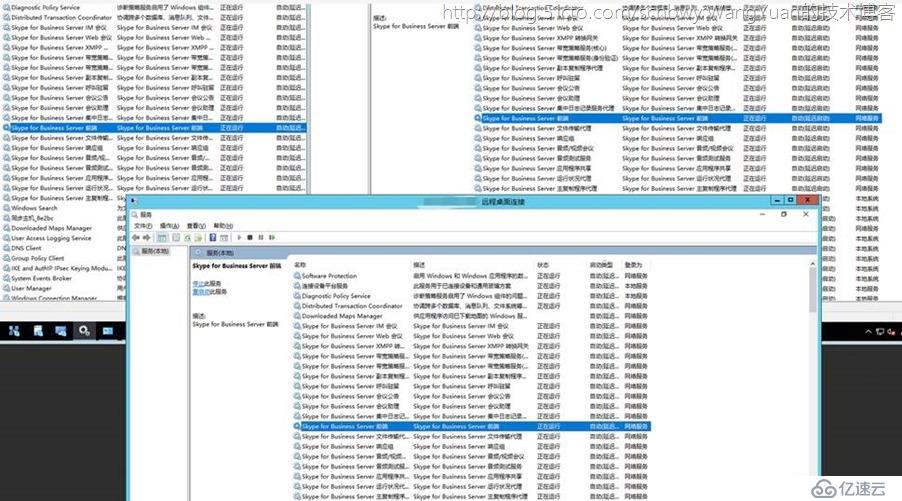
最终还是在客户规定的时间内解决了这个问题,总算是有惊无险。
所以基于以上的实际案例,强烈建议以下几点:
1、 后端数据库尽量使用SQL故障转移群集或者Alwayson,SQL故障转移群集和Alwayson可以参考我之前的文章
2、 不要把所有“鸡蛋”放到一个“篮子”里面,建议将不同的前端服务器放到不同的数据中心或者最起码放到不同的宿主机上
3、 关于前端池中前端服务器的数量:如果只有一个就直接做标准版把,强烈不建议使用两台前端服务器,至少3台前端服务去,同时建议前端服务器的数量为奇数台(3台或者5台是最佳配置,如果是7台或者9台就涉及到需要通过命令获取前5台服务器名称,重启必须按照前5台的顺序启动,这种大型池故障处理起来更加麻烦)
4、 任何数量的前端池,如果需要更新补丁,一定要使用Invoke-CsComputerFailOver -ComputerName命令将服务器离线,然后再使用Invoke-CsComputerFailBack -ComputerName命令将服务器联机,最好是一台更新完了再更新第二台,更新完所有前端服务去后一定记得升级下后端数据库。
以上是我个人的一些知识分享,不代表微软或者任何产品组,可能措辞不准或描述不准,但希望能帮到各位在实际环境中解决Skype/Lync Server企业版前端服务不能启动的问题,特别是由于结构池异常导致的。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





