这篇文章给大家介绍nodejs中有哪些爬虫框架,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
第一步:安装 Crawl-pet
nodejs 就不用多介绍吧,用 npm 安装 crawl-pet
$ npm install crawl-pet -g --production
运行,程序会引导你完成配置,首次运行,会在项目目录下生成 info.json 文件
$ crawl-pet > Set project dir: ./test-crawl-pet > Create crawl-pet in ./test-crawl-pet [y/n]: y > Set target url: http://foodshot.co/ > Set save rule [url/simple/group]: url > Set file type limit: > The limit: not limit > Set parser rule module: > The module: use default crawl-pet.parser
这里使用的测试网站 http://foodshot.co/ 是一个自由版权的,分享美食图片的网站,网站里的图片质量非常棒,这里用它只是为测试学习用,大家可以换其它网站测试
如果使用默认解析器的话,已经可以运行,看看效果:
$ crawl-pet -o ./test-crawl-pet
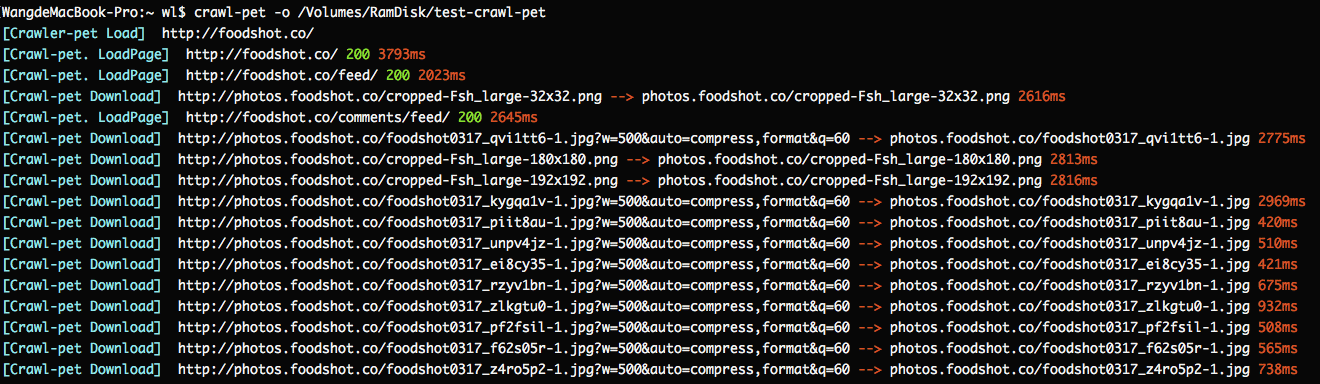
试试看
这是下载后的目录结构
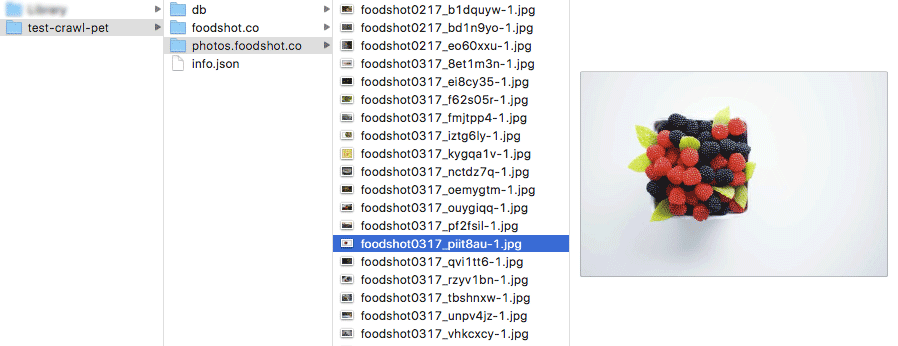
本地目录结构
第二步:写自己的解析器
现在我们来看一看如何写自己的解析器,有三种方法来生成我们自己的解析器
在新建项目时, 在 Set parser rule module 输入自己的解释器路径。修改 info.json 下的 parser 项这个最简单,直接在项目录下新建一个 parser.js 文件
使用 crawl-pet, 新建一个解析器模板
$ crawl-pet --create-parser ./test-crawl-pet/parser.js
打开 ./test-crawl-pet/parser.js 文件
// crawl-pet 支持使用 cheerio,来进行页面分析,如果你有这个需要
const cheerio = require("cheerio")
/*
* header 函数是在请求发送前调用,可以配置请求的头信息,如果返回 false,则中断请求
*
* 参数:
* options: 详细设置请看 https://github.com/request/request
* crawler_handle: 与队列通信的对象,详情见下
*
* header 函数是可选的,可不写
*/
exports.header = function(options, crawler_handle) {
}
/*
* body 函数是在请求返回后调用,用来解析返回结果
*
* 参数:
* url: 请求的 url
* body: 请求返回结果, string 类型
* response: 请求的响应,详情请看: https://github.com/request/request
* crawler_handle: 与队列通信的对象,该对象包含以下方法
* .info : crawl-pet 的配置信息
* .uri : 当前请求的 uri 信息
* .addPage(url) : 向队列里添加一个待解析页面
* .addDown(url) : 向队列里添加一个待下载文件
* .save(content, ext) : 保存文本到本地,ext 设置保存文件的后缀名
* .over() : 结束当前队列,取出下一条队列数据
*/
exports.body = function(url, body, response, crawler_handle) {
const re = /\b(href|src)\s*=\s*["']([^'"#]+)/ig
var m = null
while (m = re.exec(body)){
let href = m[2]
if (/\.(png|gif|jpg|jpeg|mp4)\b/i.test(href)) {
// 这理添加了一条下载
crawler_handle.addDown(href)
}else if(!/\.(css|js|json|xml|svg)/.test(href)){
// 这理添加了一个待解析页面
crawler_handle.addPage(href)
}
}
// 记得在解析结束后一定要执行
crawler_handle.over()
}在最后会有一个分享,懂得的请往下看
第三步:查看爬取下来的数据
根据以下载到本地的文件,查找下载地址
$ crawl-pet -f ./test-crawl-pet/photos.foodshot.co/*.jpg
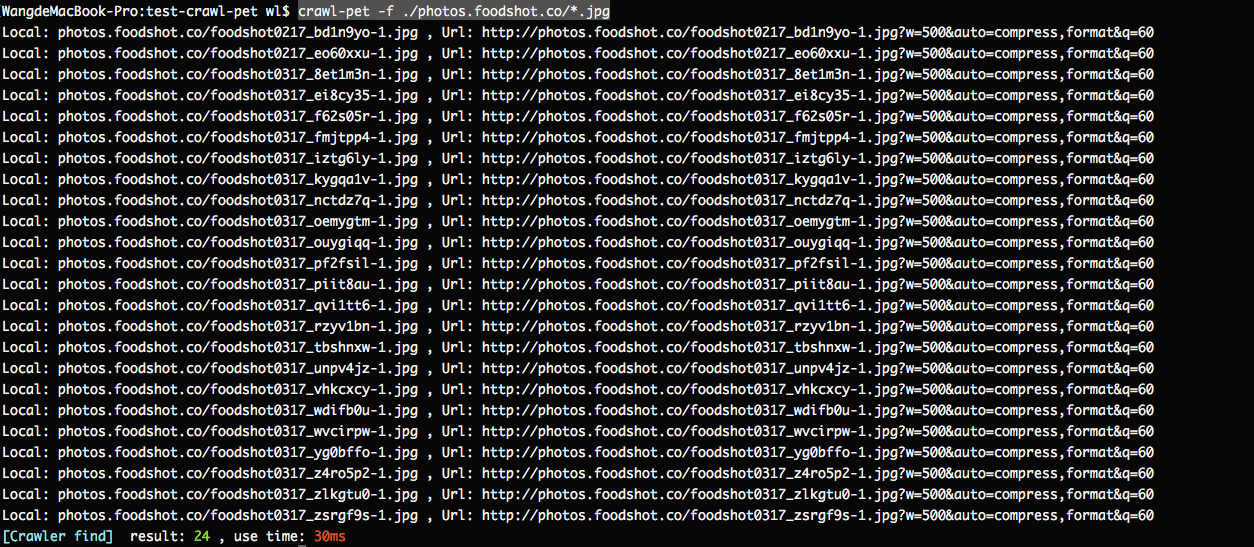
查找下载地址
查看等待队列
$ crawl-pet -l queue
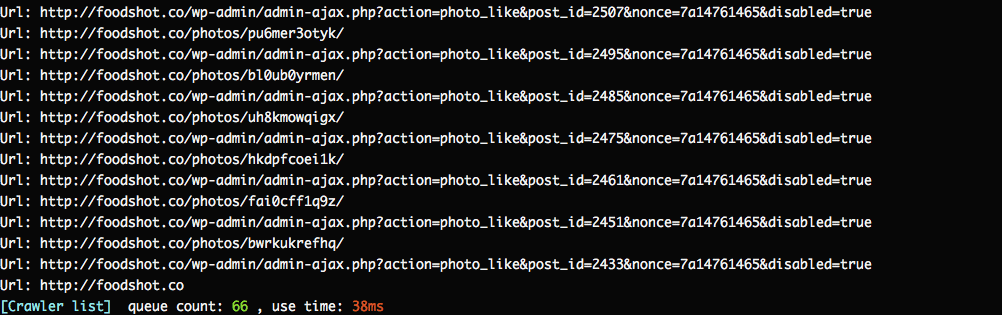
查看等待队列
查看已下载的文件列表
复制代码 代码如下:
$ crawl-pet -l down # 查看已下载列表中第 0 条后的5条数据 $ crawl-pet -l down,0,5 # --json 参数表示输出格式为 json $ crawl-pet -l down,0,5 --json
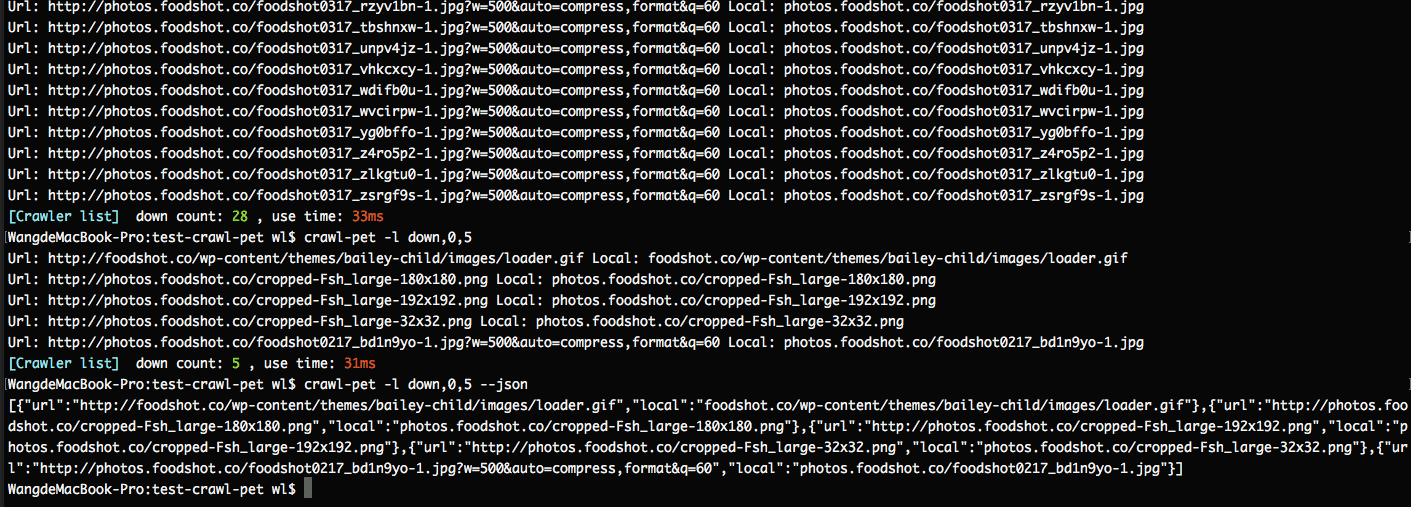
已下载的文件
查看已解析页面列表,参数与查看已下载的相同
复制代码 代码如下:
$ crawl-pet -l page
基本功能就这些了,看一下它的帮助吧
该爬虫框架是开源的,GIthub 地址在这里:https://github.com/wl879/Crawl-pet
$ crawl-pet --help Crawl-pet options help: -u, --url string Destination address -o, --outdir string Save the directory, Default use pwd -r, --restart Reload all page --clear Clear queue --save string Save file rules following options = url: Save the path consistent with url = simple: Save file in the project path = group: Save 500 files in one folder --types array Limit download file type --limit number=5 Concurrency limit --sleep number=200 Concurrent interval --timeout number=180000 Queue timeout --proxy string Set up proxy --parser string Set crawl rule, it's a js file path! The default load the parser.js file in the project path --maxsize number Limit the maximum size of the download file --minwidth number Limit the minimum width of the download file --minheight number Limit the minimum height of the download file -i, --info View the configuration file -l, --list array View the queue data e.g. [page/down/queue],0,-1 -f, --find array Find the download URL of the local file --json Print result to json format -v, --version View version -h, --help View help
最后分享一个配置
$ crawl-pet -u https://www.reddit.com/r/funny/ -o reddit --save group
info.json
{
"url": "https://www.reddit.com/r/funny/",
"outdir": ".",
"save": "group",
"types": "",
"limit": "5",
"parser": "my_parser.js",
"sleep": "200",
"timeout": "180000",
"proxy": "",
"maxsize": 0,
"minwidth": 0,
"minheight": 0,
"cookie": "over18=1"
}my_parser.js
exports.body = function(url, body, response, crawler_handle) {
const re = /\b(data-url|href|src)\s*=\s*["']([^'"#]+)/ig
var m = null
while (m = re.exec(body)){
let href = m[2]
if (/thumb|user|icon|\.(css|json|js|xml|svg)\b/i.test(href)) {
continue
}
if (/\.(png|gif|jpg|jpeg|mp4)\b/i.test(href)) {
crawler_handle.addDown(href)
continue
}
if(/reddit\.com\/r\//i.test(href)){
crawler_handle.addPage(href)
}
}
crawler_handle.over()
}关于nodejs中有哪些爬虫框架就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





