简介
用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京、上海、广州、深圳、杭州、西安、成都7个城市的数据,分别以前端、PHP、java、c++、python、Android、ios作为关键词进行爬取,爬到的数据以json格式储存到本地,为了方便观察,我将数据整理了一下供大家参考
数据结果
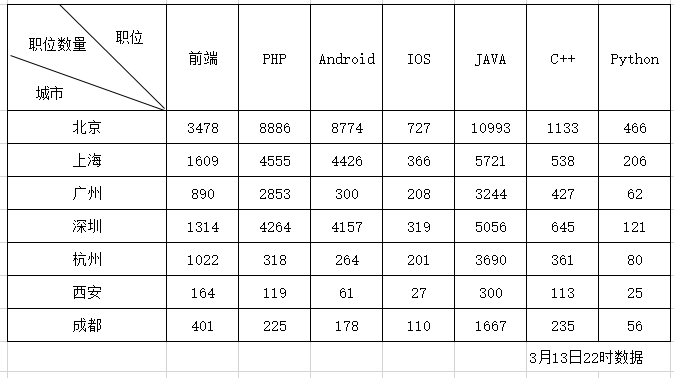
上述数据为3月13日22时爬取的数据,可大致反映各个城市对不同语言的需求量。
爬取过程展示
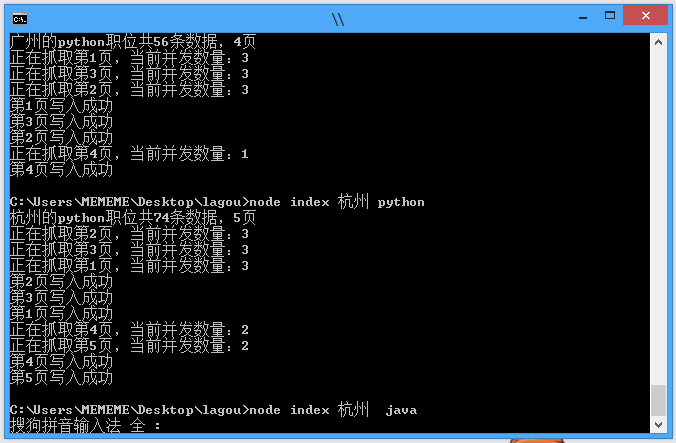
控制并发进行爬取
爬取到的数据文件
json数据文件
爬虫程序
实现思路
请求拉钩网的 “https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&city=城市&kd=关键词&pn=页数”可以返回一个json格式的数据,该数据包含所要请求职位的信息,省去了使用chreio解析的麻烦,所以直接用superagent来进行请求上述地址,并将数据储存在本地即可,其中参数city是为城市,kd为所要搜索的关键词,pn为要请求的页数,当中使用到了async来控制异步流程,使得并发数不超过3,防止被封ip。
代码地址及使用
github:https://github.com/zsqosos/positionAnalysis
代码请在github上查看,使用该程序需要安装node环境,如果觉得还不错的话烦请给个star,欢迎大家修改使用该程序。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持亿速云!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





