LZ77еҺӢзј©з®—жі•еҺҹзҗҶзҡ„зҗҶи§Ј
LZ77еҺӢзј©з®—жі•еҺҹзҗҶзҡ„зҗҶи§Ј
ж•°жҚ®еҺӢзј©жҳҜдёҖдёӘеҮҸе°Ҹж•°жҚ®еӯҳеӮЁз©әй—ҙзҡ„иҝҮзЁӢпјҢзӣ®еүҚиў«еә”з”ЁеңЁиҪҜ件е·ҘзЁӢзҡ„еҗ„дёӘең°ж–№пјҢдәҶи§Је…¶дёҖдәӣеҺҹзҗҶпјҢж–№дҫҝжҲ‘们жӣҙеҘҪзҡ„з”„йҖүеҺӢзј©ж–№жЎҲгҖӮ
еҺӢзј©ж–№жЎҲжңүеҫҲеӨҡз§ҚпјҢеёёи§Ғзҡ„е°ұжҳҜжңүжҚҹе’Ңж— жҚҹеҺӢзј©гҖӮйңҚеӨ«жӣјзј–з Ғе’ҢLZ77(Lempel-Ziv-1977)йғҪжҳҜж— жҚҹеҺӢзј©пјҢе…¶дёӯйңҚеӨ«жӣјжҳҜйҮҮз”ЁжңҖе°ҸеҶ—дҪҷзј–з Ғзҡ„з®—жі•иҝӣиЎҢеҺӢзј©пјҢиҖҢLZ77жҳҜйҮҮз”Ёеӯ—е…ёзҡ„ж–№ејҸиҝӣиЎҢеҺӢзј©гҖӮе…ідәҺйңҚеӨ«жӣјзј–з Ғзҡ„з®—жі•пјҢзҪ‘дёҠжңүеҫҲеӨҡеҜ№е…¶иҜҰз»Ҷзҡ„и®Іи§ЈпјҢжҲ‘们жң¬зҜҮе№…дёҚеңЁз»ҶиҜҙпјҢдё»иҰҒеӣҫи§ЈдёҖдёӢLZ77еҺӢзј©з®—жі•зҡ„ж–№ејҸпјҢзңӢзңӢе…¶жңүе“ӘдәӣдјҳзјәзӮ№гҖӮ
дҝЎжҒҜзҶө
ж•°жҚ®дёәдҪ•жҳҜеҸҜд»ҘеҺӢзј©зҡ„пјҢеӣ дёәж•°жҚ®йғҪдјҡиЎЁзҺ°еҮәдёҖе®ҡзҡ„зү№жҖ§пјҢз§°дёәзҶөгҖӮз»қеӨ§еӨҡж•°зҡ„ж•°жҚ®жүҖиЎЁзҺ°еҮәжқҘзҡ„е®№йҮҸеҫҖеҫҖеӨ§дәҺе…¶зҶөжүҖе»әи®®зҡ„жңҖдҪіе®№йҮҸгҖӮжҜ”еҰӮжүҖжңүзҡ„ж•°жҚ®йғҪдјҡжңүдёҖе®ҡзҡ„еҶ—дҪҷжҖ§пјҢжҲ‘们еҸҜд»ҘжҠҠеҶ—дҪҷзҡ„ж•°жҚ®йҮҮз”Ёжӣҙе°‘зҡ„дҪҚеҜ№йў‘з№ҒеҮәзҺ°зҡ„еӯ—з¬ҰиҝӣиЎҢж Үи®°пјҢд№ҹеҸҜд»ҘеҹәдәҺж•°жҚ®зҡ„дёҖдәӣзү№жҖ§еҹәдәҺеӯ—е…ёзј–з ҒпјҢд»ЈжӣҝйҮҚеӨҚеӨҡдҪҷзҡ„зҹӯиҜӯгҖӮ
LZ77з®—жі•еҺҹзҗҶ
LZ77еҺӢзј©з®—жі•йҮҮз”Ёеӯ—е…ёзҡ„ж–№ејҸиҝӣиЎҢеҺӢзј©пјҢжҳҜдёҖдёӘз®ҖеҚ•дҪҶеҚҒеҲҶй«ҳж•Ҳзҡ„ж•°жҚ®еҺӢзј©з®—жі•гҖӮе…¶ж–№ејҸе°ұжҳҜжҠҠж•°жҚ®дёӯдёҖдәӣеҸҜд»Ҙз»„з»ҮжҲҗзҹӯиҜӯ(жңҖй•ҝеӯ—з¬Ұ)зҡ„еӯ—з¬ҰеҠ е…Ҙеӯ—е…ёпјҢ然еҗҺеҶҚжңүзӣёеҗҢеӯ—з¬ҰеҮәзҺ°йҮҮз”Ёж Үи®°жқҘд»Јжӣҝеӯ—е…ёдёӯзҡ„зҹӯиҜӯпјҢеҰӮжӯӨйҖҡиҝҮж Үи®°д»ЈжӣҝеӨҡж•°йҮҚеӨҚеҮәзҺ°зҡ„ж–№ејҸд»ҘиҝӣиЎҢеҺӢзј©гҖӮиҰҒзҗҶи§Јиҝҷз§Қз®—жі•пјҢжҲ‘们е…ҲдәҶи§Ј3дёӘе…ій”®иҜҚ:зҹӯиҜӯеӯ—е…ёпјҢж»‘еҠЁзӘ—еҸЈе’Ңеҗ‘еүҚзј“еҶІеҢәгҖӮ
е…ій”®иҜҚпјҡ
1.еүҚеҗ‘зј“еҶІеҢә
жҜҸж¬ЎиҜ»еҸ–ж•°жҚ®зҡ„ж—¶еҖҷпјҢе…ҲжҠҠдёҖйғЁеҲҶж•°жҚ®йў„иҪҪе…ҘеүҚеҗ‘зј“еҶІеҢәгҖӮдёә移е…Ҙж»‘еҠЁзӘ—еҸЈеҒҡеҮҶеӨҮ
2.ж»‘еҠЁзӘ—еҸЈ
дёҖж—Ұж•°жҚ®йҖҡиҝҮзј“еҶІеҢәпјҢйӮЈд№Ҳе®ғе°Ҷ移еҠЁеҲ°ж»‘еҠЁзӘ—еҸЈдёӯпјҢ并еҸҳжҲҗеӯ—е…ёзҡ„дёҖйғЁеҲҶгҖӮ
3.зҹӯиҜӯеӯ—е…ё
д»Һеӯ—з¬ҰеәҸеҲ—S1...SnпјҢз»„жҲҗnдёӘзҹӯиҜӯгҖӮжҜ”еҰӮеӯ—з¬Ұ(A,B,D) ,еҸҜд»Ҙз»„еҗҲзҡ„зҹӯиҜӯдёә{(A),(A,B),(A,B,D),(B),(B,D),(D)},еҰӮжһңиҝҷдәӣеӯ—з¬ҰеңЁж»‘еҠЁзӘ—еҸЈйҮҢйқўпјҢе°ұеҸҜд»Ҙи®°дёәеҪ“еүҚзҡ„зҹӯиҜӯеӯ—е…ёпјҢеӣ дёәж»‘еҠЁзӘ—еҸЈдёҚж–ӯзҡ„еҗ‘еүҚж»‘еҠЁпјҢжүҖд»ҘзҹӯиҜӯеӯ—е…ёд№ҹжҳҜдёҚж–ӯзҡ„еҸҳеҢ–гҖӮ
LZ77зҡ„дё»иҰҒз®—жі•йҖ»иҫ‘е°ұжҳҜпјҢе…ҲйҖҡиҝҮеүҚеҗ‘зј“еҶІеҢәйў„иҜ»ж•°жҚ®пјҢ然еҗҺеҶҚеҗ‘ж»‘еҠЁзӘ—еҸЈз§»е…ҘпјҲж»‘еҠЁзӘ—еҸЈжңүдёҖе®ҡзҡ„й•ҝеәҰпјүпјҢдёҚж–ӯзҡ„еҜ»жүҫиғҪдёҺеӯ—е…ёдёӯзҹӯиҜӯеҢ№й…Қзҡ„жңҖй•ҝзҹӯиҜӯпјҢ然еҗҺйҖҡиҝҮж Үи®°з¬Ұж Үи®°гҖӮжҲ‘们иҝҳд»Ҙеӯ—з¬ҰABDдёәдҫӢеӯҗпјҢзңӢеҰӮдёӢеӣҫ:
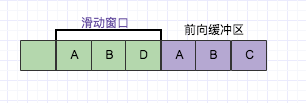
зӣ®еүҚд»ҺеүҚеҗ‘зј“еҶІеҢәдёӯеҸҜд»Ҙе’Ңж»‘еҠЁзӘ—еҸЈдёӯеҸҜд»ҘеҢ№й…Қзҡ„жңҖй•ҝзҹӯиҜӯе°ұжҳҜпјҲA,Bпјү,然еҗҺеҗ‘еүҚ移еҠЁзҡ„ж—¶еҖҷеҶҚж¬ЎйҒҮеҲ°пјҲA,Bпјүзҡ„ж—¶еҖҷйҮҮз”Ёж Үи®°з¬Ұд»ЈжӣҝгҖӮ
еҺӢзј©
еҪ“еҺӢзј©ж•°жҚ®зҡ„ж—¶еҖҷпјҢеүҚеҗ‘зј“еҶІеҢәдёҺ移еҠЁзӘ—еҸЈд№Ӣй—ҙеңЁеҒҡзҹӯиҜӯеҢ№й…Қзҡ„жҳҜеҗҺдјҡеӯҳеңЁ2з§Қжғ…еҶө:
- жүҫдёҚеҲ°еҢ№й…Қж—¶пјҡе°ҶжңӘеҢ№й…Қзҡ„з¬ҰеҸ·зј–з ҒжҲҗз¬ҰеҸ·ж Үи®°пјҲеӨҡж•°йғҪжҳҜеӯ—з¬Ұжң¬иә«пјү
- жүҫеҲ°еҢ№й…Қж—¶:е°Ҷе…¶жңҖй•ҝзҡ„еҢ№й…Қзј–з ҒжҲҗзҹӯиҜӯж Үи®°гҖӮ
- зҹӯиҜӯж Үи®°еҢ…еҗ«дёүйғЁеҲҶдҝЎжҒҜ:пјҲж»‘еҠЁзӘ—еҸЈдёӯзҡ„еҒҸ移йҮҸпјҲд»ҺеҢ№й…ҚејҖе§Ӣзҡ„ең°ж–№и®Ўз®—пјүгҖҒеҢ№й…Қдёӯзҡ„з¬ҰеҸ·дёӘж•°гҖҒеҢ№й…Қз»“жқҹеҗҺзҡ„еүҚеҗ‘зј“еҶІеҢәдёӯзҡ„第дёҖдёӘз¬ҰеҸ·пјүгҖӮ
дёҖж—ҰжҠҠnдёӘз¬ҰеҸ·зј–з Ғ并з”ҹжҲҗе“Қеә”зҡ„ж Үи®°пјҢе°ұе°ҶиҝҷnдёӘз¬ҰеҸ·д»Һж»‘еҠЁзӘ—еҸЈзҡ„дёҖз«Ҝ移еҮәпјҢ并用еүҚеҗ‘зј“еҶІеҢәдёӯеҗҢж ·ж•°йҮҸзҡ„з¬ҰеҸ·жқҘд»Јжӣҝе®ғ们пјҢеҰӮжӯӨпјҢж»‘еҠЁзӘ—еҸЈдёӯе§Ӣз»ҲжңүжңҖж–°зҡ„зҹӯиҜӯгҖӮ
жҲ‘们йҮҮз”ЁеӣҫдҫӢжқҘзңӢ:
1гҖҒејҖе§Ӣ

2гҖҒж»‘еҠЁзӘ—еҸЈдёӯжІЎжңүж•°жҚ®пјҢжүҖд»ҘжІЎжңүеҢ№й…ҚеҲ°зҹӯиҜӯпјҢе°Ҷеӯ—з¬ҰAж Үи®°дёәA

3гҖҒж»‘еҠЁзӘ—еҸЈдёӯжңүA,жІЎжңүд»Һзј“еҶІеҢәдёӯеӯ—з¬ҰпјҲBABCпјүдёӯеҢ№й…ҚеҲ°зҹӯиҜӯпјҢдҫқ然жҠҠBж Үи®°дёәB

4гҖҒзј“еҶІеҢәеӯ—з¬ҰпјҲABCBпјүеңЁж»‘еҠЁзӘ—еҸЈзҡ„дҪҚ移6дҪҚзҪ®жүҫеҲ°AB,жҲҗеҠҹеҢ№й…ҚеҲ°зҹӯиҜӯAB,е°ҶABзј–з Ғдёә(6,2,C)

5гҖҒзј“еҶІеҢәеӯ—з¬ҰпјҲBABAпјүеңЁж»‘еҠЁзӘ—еҸЈдҪҚ移4зҡ„дҪҚзҪ®еҢ№й…ҚеҲ°зҹӯиҜӯBAB,е°ҶBABзј–з Ғдёә(4,3,A)

6гҖҒзј“еҶІеҢәеӯ—з¬ҰпјҲBCADпјүеңЁж»‘еҠЁзӘ—еҸЈдҪҚ移2зҡ„дҪҚзҪ®еҢ№й…ҚеҲ°зҹӯиҜӯBCпјҢе°ҶBCзј–з ҒдёәпјҲ2,2,Aпјү

7гҖҒзј“еҶІеҢәеӯ—з¬ҰD,еңЁж»‘еҠЁзӘ—еҸЈдёӯжІЎжңүжүҫеҲ°еҢ№й…ҚзҹӯиҜӯпјҢж Үи®°дёәD

8гҖҒзј“еҶІеҢәдёӯжІЎжңүж•°жҚ®иҝӣе…ҘдәҶпјҢз»“жқҹ

и§ЈеҺӢ
и§ЈеҺӢзұ»дјјдәҺеҺӢзј©зҡ„йҖҶеҗ‘иҝҮзЁӢпјҢйҖҡиҝҮи§Јз Ғж Үи®°е’ҢдҝқжҢҒж»‘еҠЁзӘ—еҸЈдёӯзҡ„з¬ҰеҸ·жқҘжӣҙж–°и§ЈеҺӢж•°жҚ®гҖӮ
еҪ“и§Јз Ғеӯ—з¬Ұж Үи®°:е°Ҷж Үи®°зј–з ҒжҲҗеӯ—з¬ҰжӢ·иҙқеҲ°ж»‘еҠЁзӘ—еҸЈдёӯ
и§Јз ҒзҹӯиҜӯж Үи®°:еңЁж»‘еҠЁзӘ—еҸЈдёӯжҹҘжүҫе“Қеә”еҒҸ移йҮҸпјҢеҗҢж—¶жүҫеҲ°жҢҮе®ҡй•ҝзҹӯзҡ„зҹӯиҜӯиҝӣиЎҢжӣҝжҚўгҖӮ
жҲ‘们иҝҳжҳҜйҮҮз”ЁеӣҫдҫӢжқҘзңӢдёӢ:
1гҖҒејҖе§Ӣ

2гҖҒз¬ҰеҸ·ж Үи®°Aи§Јз Ғ

3гҖҒз¬ҰеҸ·ж Үи®°Bи§Јз Ғ

4гҖҒзҹӯиҜӯж Үи®°(6,2,C)и§Јз Ғ

5гҖҒзҹӯиҜӯж Үи®°(4,3,A)и§Јз Ғ

6гҖҒзҹӯиҜӯж Үи®°(2,2,A)и§Јз Ғ

7гҖҒз¬ҰеҸ·ж Үи®°Dи§Јз Ғ

дјҳзјәзӮ№
еӨ§еӨҡж•°жғ…еҶөдёӢLZ77еҺӢзј©з®—жі•зҡ„еҺӢзј©жҜ”зӣёеҪ“й«ҳпјҢеҪ“然дәҶд№ҹе’ҢдҪ йҖүжӢ©ж»‘еҠЁзӘ—еҸЈеӨ§е°ҸпјҢд»ҘеҸҠеүҚеҗ‘зј“еҶІеҢәеӨ§е°ҸпјҢд»ҘеҸҠж•°жҚ®зҶөжңүе…ізі»гҖӮе…¶еҺӢзј©иҝҮзЁӢжҳҜжҜ”иҫғиҖ—ж—¶зҡ„пјҢеӣ дёәиҰҒиҠұиҙ№еҫҲеӨҡж—¶й—ҙеҜ»жүҫж»‘еҠЁзӘ—еҸЈдёӯзҡ„зҹӯиҜӯеҢ№й…ҚпјҢдёҚиҝҮи§ЈеҺӢиҝҮзЁӢдјҡеҫҲеҝ«пјҢеӣ дёәжҜҸдёӘж Үи®°йғҪжҳҺзЎ®е‘ҠзҹҘеңЁе“ӘдёӘдҪҚзҪ®еҸҜд»ҘиҜ»еҸ–дәҶгҖӮ
д»ҘдёҠе°ұжҳҜLZ77еҺӢзј©з®—жі•еҺҹзҗҶзҡ„зҗҶи§ЈпјҢеҰӮжңүз–‘й—®иҜ·з•ҷиЁҖжҲ–иҖ…еҲ°жң¬з«ҷзӨҫеҢәдәӨжөҒи®Ёи®әпјҢж„ҹи°ўйҳ…иҜ»пјҢеёҢжңӣиғҪеё®еҠ©еҲ°еӨ§е®¶пјҢи°ўи°ўеӨ§е®¶еҜ№жң¬з«ҷзҡ„ж”ҜжҢҒпјҒ





