小编给大家分享一下Java基于二分搜索树、链表如何实现集合Set复杂度分析,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
在Java底层基于二叉搜索树实现集合和映射 和Java底层基于链表实现集合和映射中以二分搜索树和链表作为底层实现了集合Set,在本节就两种集合类的复杂度分析进行分析:
测试内容:Java底层基于二叉搜索树实现集合和映射和Java底层基于链表实现集合和映射中使用的书籍。
测试方法:测试两种集合类查找单词所用的时间
//创建一个测试方法 Set<String> set:他们可以是实现了该接口的LinkedListSet和BSTSet对象
private static double testSet(Set<String> set, String filename) {
//计算开始时间
long startTime = System.nanoTime();
System.out.println("Pride and Prejudice");
//新建一个ArrayList存放单词
ArrayList<String> words1 = new ArrayList<>();
//通过这个方法将书中所以单词存入word1中
FileOperation.readFile(filename, words1);
System.out.println("Total words : " + words1.size());
//增强for循环,定一个字符串word去遍历words
//底层的话会把ArrayList words1中的值一个一个的赋值给word
for (String word : words1)
set.add(word);//不添加重复元素
System.out.println("Total different words : " + set.getSize());
//计算结束时间
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;//纳秒为单位
}
public static void main(String[] args) {
//基于二分搜索的集合
BSTSet<String> bstSet = new BSTSet<>();
double time1 = testSet(bstSet, "pride-and-prejudice.txt");
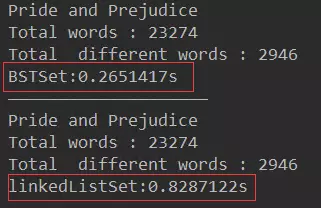
System.out.println("BSTSet:" + time1 + "s");
System.out.println("————————————————————");
//基于链表实现的集合
LinkedListSet<String> linkedListSet = new LinkedListSet<>();
double time2 = testSet(linkedListSet, "pride-and-prejudice.txt");
System.out.println("linkedListSet:" + time2 + "s");
}结果:BSTSet的速度比LinkedListed的速度快

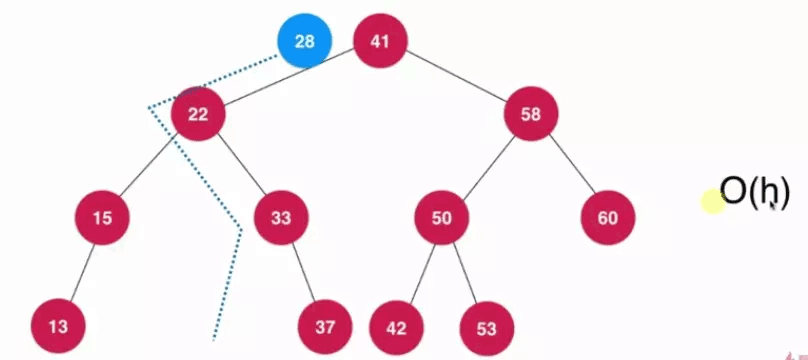
在基于二叉搜索树的情况下,增加、查询、删除的与二叉搜索树的深度有关,每次操作均为从根节点到某一一支子树的叶子节点之间进行操作,时间复杂度为0(h),h表示二叉搜索树的高度(层数)。
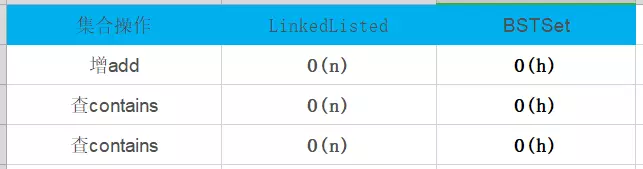
二叉搜索树复杂度如下:

下面对n与h关系进行推导:
2.1.1 采用满二叉树的情况进行分析(最优情况)
采用满二叉树(每个节点都有左右节点,除了叶子节点)来进行分析的原因为满二叉树是一种极端情况,如下图:
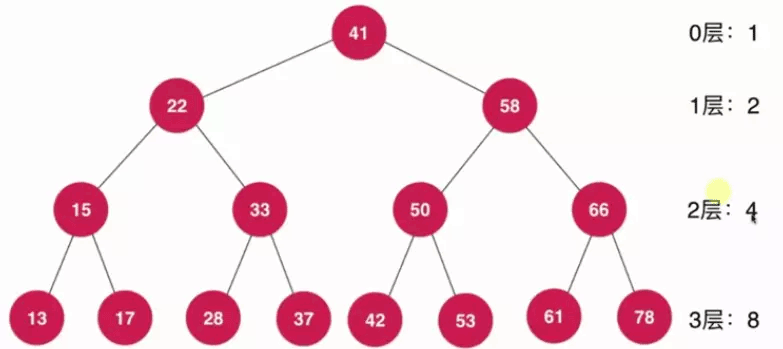
从上图中关于h层总共有多少个节点有如下推导:

假设节点个数为n个则有如下关系:

针对都是log级别的关系,底数是多少不影响它是log级别的则有:
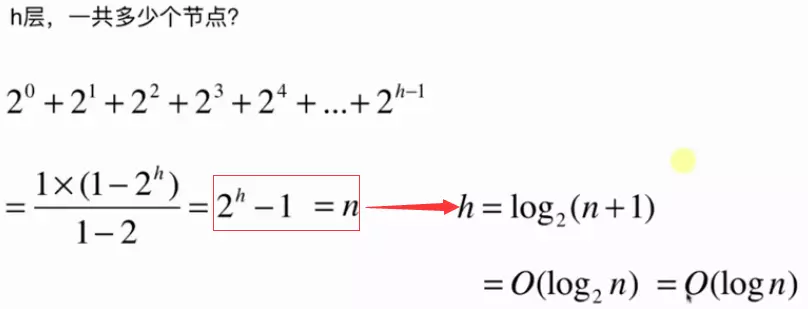
2.1.2 单个孩子情况----二叉搜索树最坏情况(节点数等于其高度)
比如:下面这种二叉搜索树
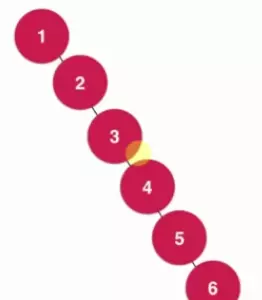
对于这种只有单个孩子的情况,此时二叉搜索树退化成了链表,此时的时间复杂度为O(n)。

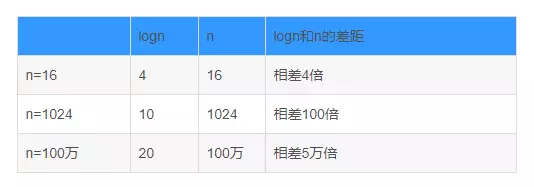
2.2.1 logn和n的差距
Java的基本数据类型分为:1、整数类型,用来表示整数的数据类型。2、浮点类型,用来表示小数的数据类型。3、字符类型,字符类型的关键字是“char”。4、布尔类型,是表示逻辑值的基本数据类型。
看完了这篇文章,相信你对“Java基于二分搜索树、链表如何实现集合Set复杂度分析”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





