这篇文章给大家分享的是有关iOS中如何实现自带超强中文分词器的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
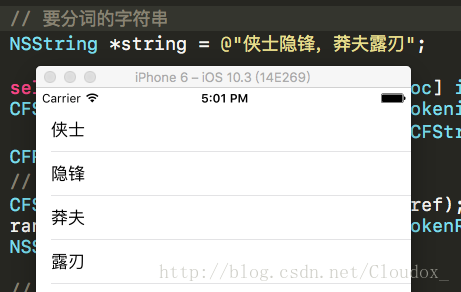
效果如下:
实现
其实苹果给出了完整的API,想要全面了解的可以直接看文档:CFStringTokenizer Reference
这里说说简单的一个实现:
// 要分词的字符串
NSString *string = @"侠士隐锋,莽夫露刃";
self.keywords = [[NSMutableArray alloc] init];
CFStringTokenizerRef ref = CFStringTokenizerCreate(NULL, (__bridge CFStringRef)string, CFRangeMake(0, string.length), kCFStringTokenizerUnitWord, NULL);// 创建分词器
CFRange range;// 当前分词的位置
// 获取第一个分词的范围
CFStringTokenizerAdvanceToNextToken(ref);
range = CFStringTokenizerGetCurrentTokenRange(ref);
// 循环遍历获取所有分词并记录到数组中
NSString *keyWord;
while (range.length>0) {
keyWord = [string substringWithRange:NSMakeRange(range.location, range.length)];
[self.keywords addObject:keyWord];
CFStringTokenizerAdvanceToNextToken(ref);
range = CFStringTokenizerGetCurrentTokenRange(ref);
}其实逻辑很简单:创建分词器–>一个个地一次获取分词后的每个词的起始位置和长度,从而取出词。
示例里我用列表显示每个分词,比较清楚,列表的实现就不说明了,可以直接看工程代码。
值得一提的是,其分词速度很快,甚至一些网络词汇比如“木有”,一些成语等等都能够识别出,能看出这是分词的什么吗:

感谢各位的阅读!关于“iOS中如何实现自带超强中文分词器”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



