本篇内容介绍了“Java中的多线程及分布式爬虫架构的原理”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
前面几章内容我们的爬虫程序都是单线程,在我们调试爬虫程序的时候,单线程爬虫没什么问题,但是当我们在线上环境使用单线程爬虫程序去采集网页时,单线程就暴露出了两个致命的问题:
采集效率特别慢,单线程之间都是串行的,下一个执行动作需要等上一个执行完才能执行
对服务器的CUP等利用率不高,想想我们的服务器都是 8核16G,32G 的只跑一个线程会不会太浪费啦
线上环境不可能像我们本地测试一样,不在乎采集效率,只要能正确提取结果就行。在这个时间就是金钱的年代,不可能给你时间去慢慢的采集,所以单线程爬虫程序是行不通的,我们需要将单线程改成多线程的模式,来提升采集效率和提高计算机利用率。
多线程的爬虫程序设计比单线程就要复杂很多,但是与其他业务在高并发下要保证数据安全又不同,多线程爬虫在数据安全上到要求不是那么的高,因为每个页面都可以被看作是一个独立体。要做好多线程爬虫就必须做好两点:第一点就是统一的待采集 URL 维护,第二点就是 URL 的去重, 下面我们简单的来聊一聊这两点。
维护待采集的 URL
多线程爬虫程序就不能像单线程那样,每个线程独自维护这自己的待采集 URL,如果这样的话,那么每个线程采集的网页将是一样的,你这就不是多线程采集啦,你这是将一个页面采集的多次。基于这个原因我们就需要将待采集的 URL 统一维护,每个线程从统一 URL 维护处领取采集 URL ,完成采集任务,如果在页面上发现新的 URL 链接则添加到 统一 URL 维护的容器中。下面是几种适合用作统一 URL 维护的容器:
URL 的去重
URL 的去重也是多线程采集的关键一步,因为如果不去重的话,那么我们将采集到大量重复的 URL,这样并没有提升我们的采集效率,比如一个分页的新闻列表,我们在采集第一页的时候可以得到 2、3、4、5 页的链接,在采集第二页的时候又会得到 1、3、4、5 页的链接,待采集的 URL 队列中将存在大量的列表页链接,这样就会重复采集甚至进入到一个死循环当中,所以就需要 URL 去重。URL 去重的方法就非常多啦,下面是几种常用的 URL 去重方式:
将 URL 保存到数据库进行去重,比如 redis、MongoDB
将 URL 放到哈希表中去重,例如 hashset
将 URL 经过 MD5 之后保存到哈希表中去重,相比于上面一种,能够节约空间
使用 布隆过滤器(Bloom Filter)去重,这种方式能够节约大量的空间,就是不那么准确。
关于多线程爬虫的两个核心知识点我们都知道啦,下面我画了一个简单的多线程爬虫架构图,如下图所示:
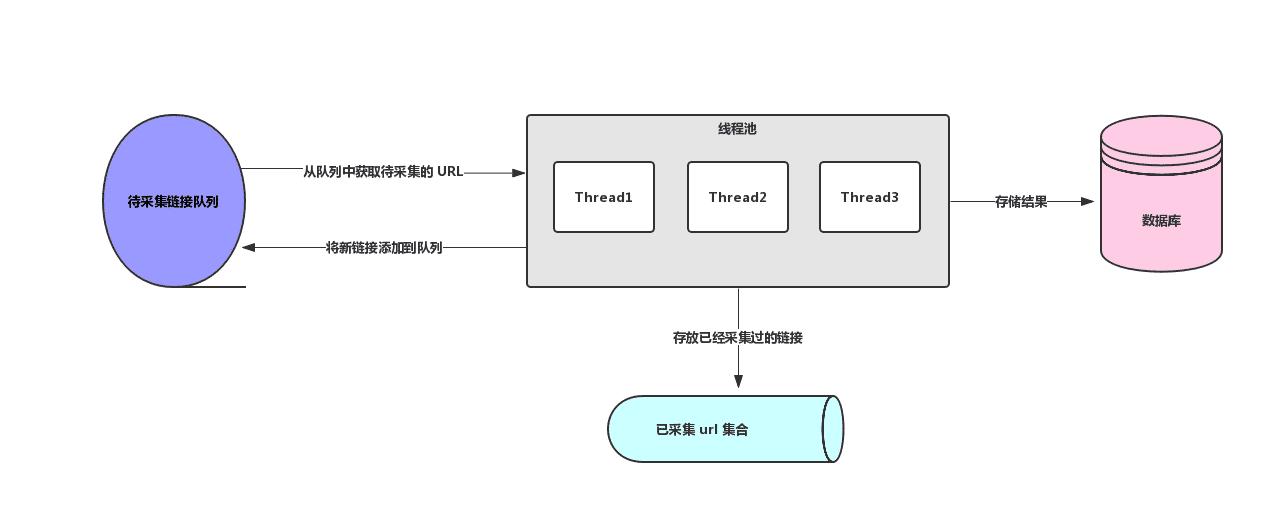
上面我们主要了解了多线程爬虫的架构设计,接下来我们不妨来试试 Java 多线程爬虫,我们以采集虎扑新闻为例来实战一下 Java 多线程爬虫,Java 多线程爬虫中设计到了 待采集 URL 的维护和 URL 去重,由于我们这里只是演示,所以我们就使用 JDK 内置的容器来完成,我们使用 LinkedBlockingQueue 作为待采集 URL 维护容器,HashSet 作为 URL 去重容器。下面是 Java 多线程爬虫核心代码,详细代码以上传 GitHub,地址在文末:
/**
* 多线程爬虫
*/
public class ThreadCrawler implements Runnable {
// 采集的文章数
private final AtomicLong pageCount = new AtomicLong(0);
// 列表页链接正则表达式
public static final String URL_LIST = "https://voice.hupu.com/nba";
protected Logger logger = LoggerFactory.getLogger(getClass());
// 待采集的队列
LinkedBlockingQueue<String> taskQueue;
// 采集过的链接列表
HashSet<String> visited;
// 线程池
CountableThreadPool threadPool;
/**
*
* @param url 起始页
* @param threadNum 线程数
* @throws InterruptedException
*/
public ThreadCrawler(String url, int threadNum) throws InterruptedException {
this.taskQueue = new LinkedBlockingQueue<>();
this.threadPool = new CountableThreadPool(threadNum);
this.visited = new HashSet<>();
// 将起始页添加到待采集队列中
this.taskQueue.put(url);
}
@Override
public void run() {
logger.info("Spider started!");
while (!Thread.currentThread().isInterrupted()) {
// 从队列中获取待采集 URL
final String request = taskQueue.poll();
// 如果获取 request 为空,并且当前的线程采已经没有线程在运行
if (request == null) {
if (threadPool.getThreadAlive() == 0) {
break;
}
} else {
// 执行采集任务
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
processRequest(request);
} catch (Exception e) {
logger.error("process request " + request + " error", e);
} finally {
// 采集页面 +1
pageCount.incrementAndGet();
}
}
});
}
}
threadPool.shutdown();
logger.info("Spider closed! {} pages downloaded.", pageCount.get());
}
/**
* 处理采集请求
* @param url
*/
protected void processRequest(String url) {
// 判断是否为列表页
if (url.matches(URL_LIST)) {
// 列表页解析出详情页链接添加到待采集URL队列中
processTaskQueue(url);
} else {
// 解析网页
processPage(url);
}
}
/**
* 处理链接采集
* 处理列表页,将 url 添加到队列中
*
* @param url
*/
protected void processTaskQueue(String url) {
try {
Document doc = Jsoup.connect(url).get();
// 详情页链接
Elements elements = doc.select(" div.news-list > ul > li > div.list-hd > h5 > a");
elements.stream().forEach((element -> {
String request = element.attr("href");
// 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
if (!visited.contains(request) && !taskQueue.contains(request)) {
try {
taskQueue.put(request);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}));
// 列表页链接
Elements list_urls = doc.select("div.voice-paging > a");
list_urls.stream().forEach((element -> {
String request = element.absUrl("href");
// 判断是否符合要提取的列表链接要求
if (request.matches(URL_LIST)) {
// 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
if (!visited.contains(request) && !taskQueue.contains(request)) {
try {
taskQueue.put(request);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}));
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 解析页面
*
* @param url
*/
protected void processPage(String url) {
try {
Document doc = Jsoup.connect(url).get();
String title = doc.select("body > div.hp-wrap > div.voice-main > div.artical-title > h2").first().ownText();
System.out.println(Thread.currentThread().getName() + " 在 " + new Date() + " 采集了虎扑新闻 " + title);
// 将采集完的 url 存入到已经采集的 set 中
visited.add(url);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
new ThreadCrawler("https://voice.hupu.com/nba", 5).run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}我们用 5 个线程去采集虎扑新闻列表页看看效果如果?运行该程序,得到如下结果:
多线程采集结果
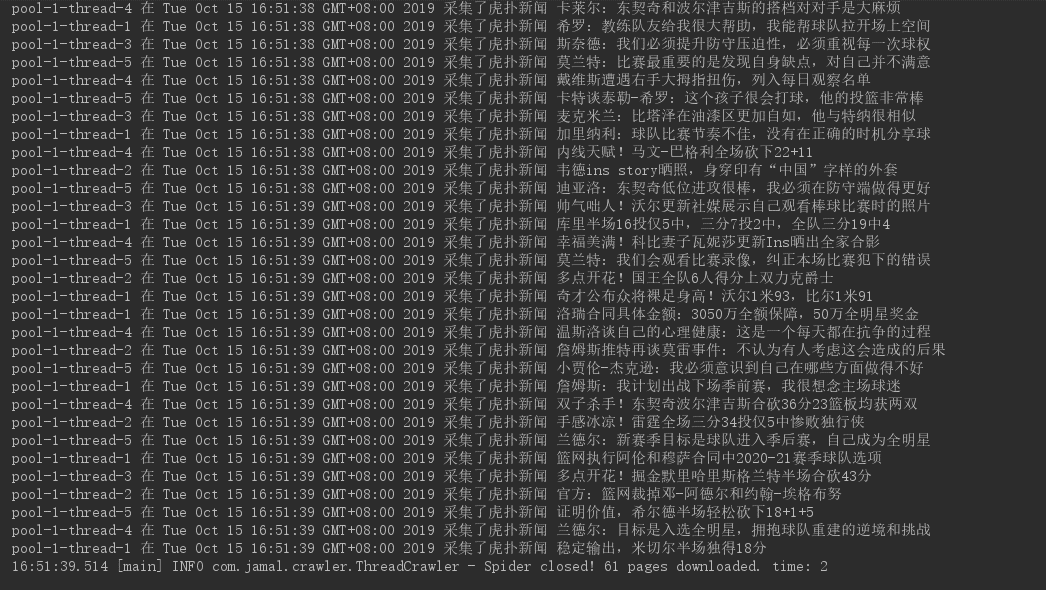
结果中可以看出,我们启动了 5 个线程采集了 61 页页面,一共耗时 2 秒钟,可以说效果还是不错的,我们来跟单线程对比一下,看看差距有多大?我们将线程数设置为 1 ,再次启动程序,得到如下结果:
单线程运行结果
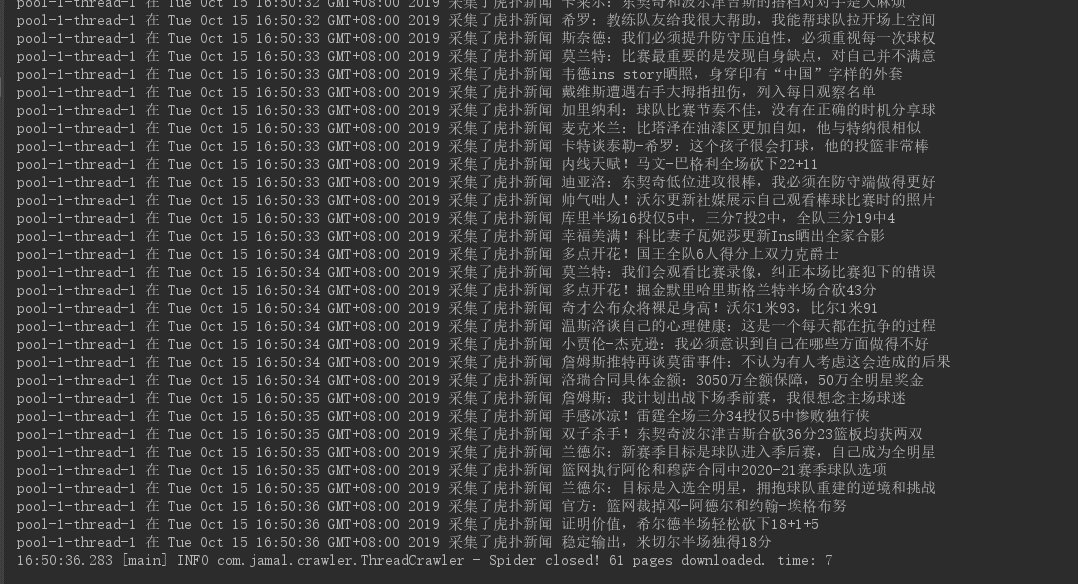
可以看出单线程采集虎扑 61 条新闻花费了 7 秒钟,耗时差不多是多线程的 4 倍,你想想这可只是 61 个页面,页面更多的话,差距会越来越大,所以多线程爬虫效率还是非常高的。
“Java中的多线程及分布式爬虫架构的原理”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





