小编给大家分享一下Java网络爬虫的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
需要提取的内容如下图所示:
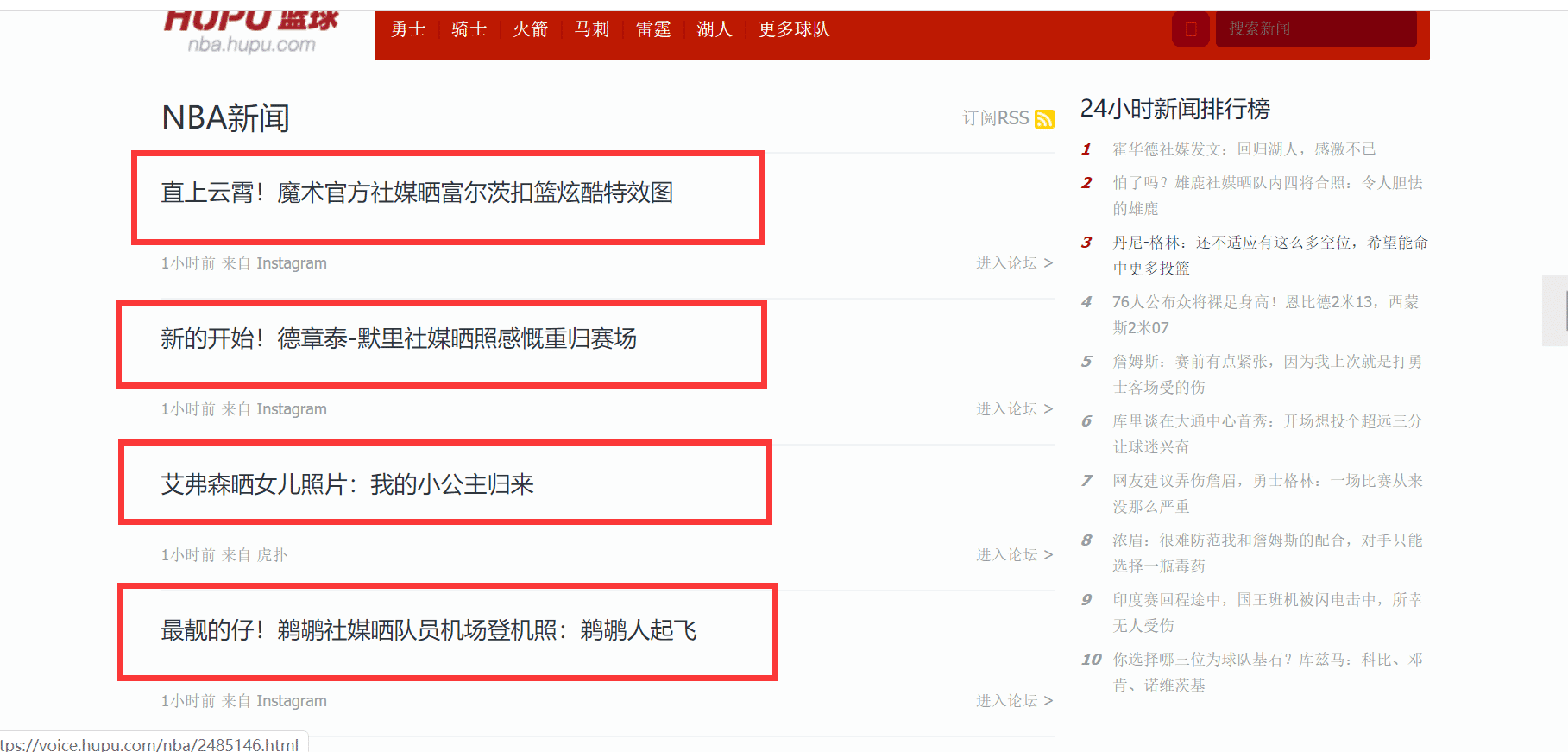
我们需要提取图中圈出来的文字及其对应的链接,在提取的过程中,我们会使用两种方式来提取,一种是 Jsoup 的方式,另一种是 httpclient + 正则表达式的方式,这也是 Java 网络爬虫常用的两种方式,你不了解这两种方式没关系,后面会有相应的使用手册。在正式编写提取程序之前,我先交代一下 Java 爬虫系列博文的环境,该系列博文所有的 demo 都是使用 SpringBoot 搭建的,不管你使用哪种环境,只需要正确的导入相应的包即可。
Jsoup 方式提取信息
我们先来使用 Jsoup 的方式提取新闻信息,如果你还不知道 Jsoup ,请参考 https://jsoup.org/
先建立一个 Springboot 项目,名字就随意啦,在 pom.xml 中引入 Jsoup 的依赖
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.12.1</version> </dependency>
好了,接下来我们一起分析页面吧,想必你还没浏览过吧,点击这里浏览虎扑新闻。在列表页中,我们利用 F12 审查元素查看页面结构,经过我们分析发现列表新闻在 <div class="news-list">标签下,每一条新闻都是一个li标签,分析结果如下图所示:
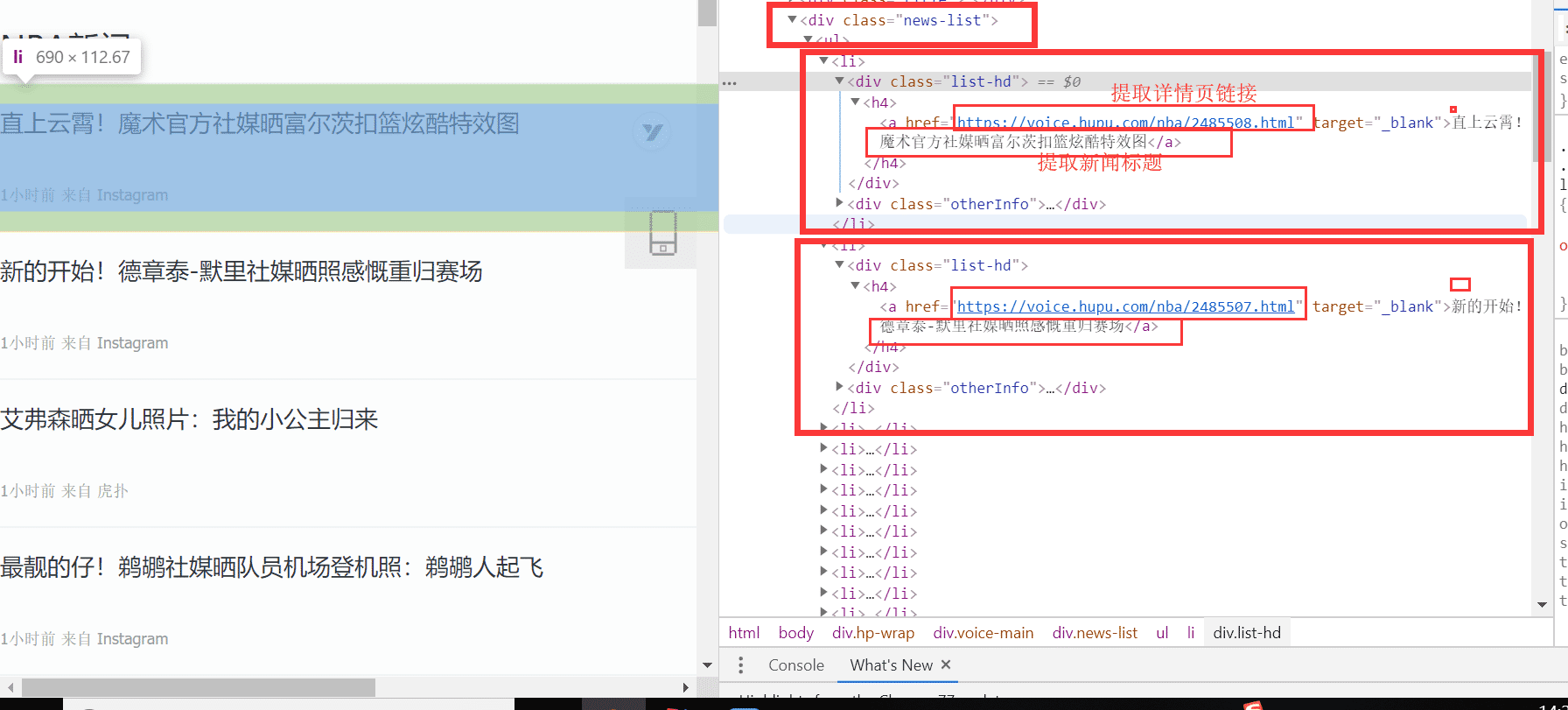
由于我们前面已经知道了 css 选择器,我们结合浏览器的 Copy 功能,编写出我们 a标签的 css 选择器代码:div.news-list > ul > li > div.list-hd > h5 > a ,一切都准备好了,我们一起来编写 Jsoup 方式提取信息的代码:
/**
* jsoup方式 获取虎扑新闻列表页
* @param url 虎扑新闻列表页url
*/
public void jsoupList(String url){
try {
Document document = Jsoup.connect(url).get();
// 使用 css选择器 提取列表新闻 a 标签
// <a href="https://voice.hupu.com/nba/2484553.html" rel="external nofollow" target="_blank">霍华德:夏休期内曾节食30天,这考验了我的身心</a>
Elements elements = document.select("div.news-list > ul > li > div.list-hd > h5 > a");
for (Element element:elements){
// System.out.println(element);
// 获取详情页链接
String d_url = element.attr("href");
// 获取标题
String title = element.ownText();
System.out.println("详情页链接:"+d_url+" ,详情页标题:"+title);
}
} catch (IOException e) {
e.printStackTrace();
}
}使用 Jsoup 方式提取还是非常简单的,就5、6行代码就完成了,关于更多 Jsoup 如何提取节点信息的方法可以参考 jsoup 的官网教程。我们编写 main 方法,来执行 jsoupList 方法,看看 jsoupList 方法是否正确。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
crawlerBase.jsoupList(url);
}执行 main 方法,得到如下结果:
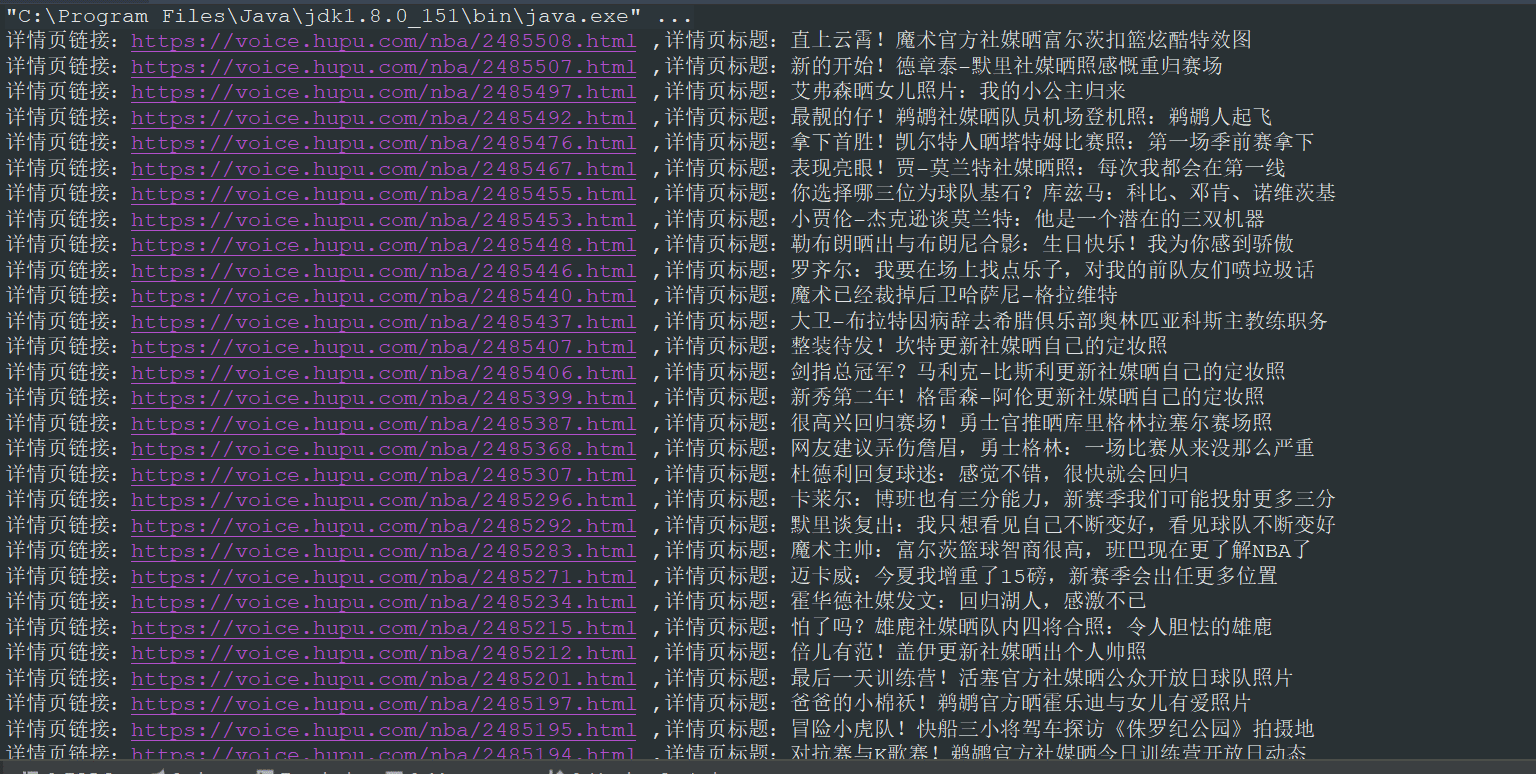
从结果中可以看出,我们已经正确的提取到了我们想要的信息,如果你想采集详情页的信息,只需要编写一个采集详情页的方法,在方法中提取详情页相应的节点信息,然后将列表页提取的链接传入提取详情页方法即可。
httpclient + 正则表达式
上面我们使用了 Jsoup 方式正确提取了虎扑列表新闻,接下来我们使用 httpclient + 正则表达式的方式来提取,看看使用这种方式又会涉及到哪些问题?httpclient + 正则表达式的方式涉及的知识点还是蛮多的,它涉及到了正则表达式、Java 正则表达式、httpclient。如果你还不知道这些知识,可以点击下方链接简单了解一下:
正则表达式:正则表达式
Java 正则表达式:Java 正则表达式
httpclient:httpclient
我们在 pom.xml 文件中,引入 httpclient 相关 Jar 包
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.10</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpcore</artifactId> <version>4.4.10</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpmime</artifactId> <version>4.5.10</version> </dependency>
关于虎扑列表新闻页面,我们在使用 Jsoup 方式的时候进行了简单的分析,这里我们就不在重复分析了。对于使用正则表达式方式提取,我们需要找到能够代表列表新闻的结构体,比如: <div class="list-hd"> <h5> <a href="https://voice.hupu.com/nba/2485508.html" rel="external nofollow" target="_blank">直上云霄!魔术官方社媒晒富尔茨扣篮炫酷特效图</a></h5></div>
这段结构体,每个列表新闻只有链接和标题不一样,其他的都一样,而且 <div class="list-hd">是列表新闻特有的。最好不要直接正则匹配 a标签,因为 a标签在其他地方也有,这样我们就还需要做其他的处理,增加我们的难度。现在我们了解了正则结构体的选择,我们一起来看看 httpclient + 正则表达式方式提取的代码:
/**
* httpclient + 正则表达式 获取虎扑新闻列表页
* @param url 虎扑新闻列表页url
*/
public void httpClientList(String url){
try {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity,"utf-8");
if (body!=null) {
/*
* 替换掉换行符、制表符、回车符,去掉这些符号,正则表示写起来更简单一些
* 只有空格符号和其他正常字体
*/
Pattern p = Pattern.compile("\t|\r|\n");
Matcher m = p.matcher(body);
body = m.replaceAll("");
/*
* 提取列表页的正则表达式
* 去除换行符之后的 li
* <div class="list-hd"> <h5> <a href="https://voice.hupu.com/nba/2485167.html" rel="external nofollow" target="_blank">与球迷亲切互动!凯尔特人官方晒球队开放训练日照片</a> </h5> </div>
*/
Pattern pattern = Pattern
.compile("<div class=\"list-hd\">\\s* <h5>\\s* <a href=\"(.*?)\"\\s* target=\"_blank\">(.*?)</a>\\s* </h5>\\s* </div>" );
Matcher matcher = pattern.matcher(body);
// 匹配出所有符合正则表达式的数据
while (matcher.find()){
// String info = matcher.group(0);
// System.out.println(info);
// 提取出链接和标题
System.out.println("详情页链接:"+matcher.group(1)+" ,详情页标题:"+matcher.group(2));
}
}else {
System.out.println("处理失败!!!获取正文内容为空");
}
} else {
System.out.println("处理失败!!!返回状态码:" + response.getStatusLine().getStatusCode());
}
}catch (Exception e){
e.printStackTrace();
}
}从代码的行数可以看出,比 Jsoup 方式要多不少,代码虽然多,但是整体来说比较简单,在上面方法中我做了一段特殊处理,我先替换了 httpclient 获取的字符串 body 中的换行符、制表符、回车符,因为这样处理,在编写正则表达式的时候能够减少一些额外的干扰。接下来我们修改 main 方法,运行 httpClientList 方法。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
// crawlerBase.jsoupList(url);
crawlerBase.httpClientList(url);
}运行结果如下图所示:
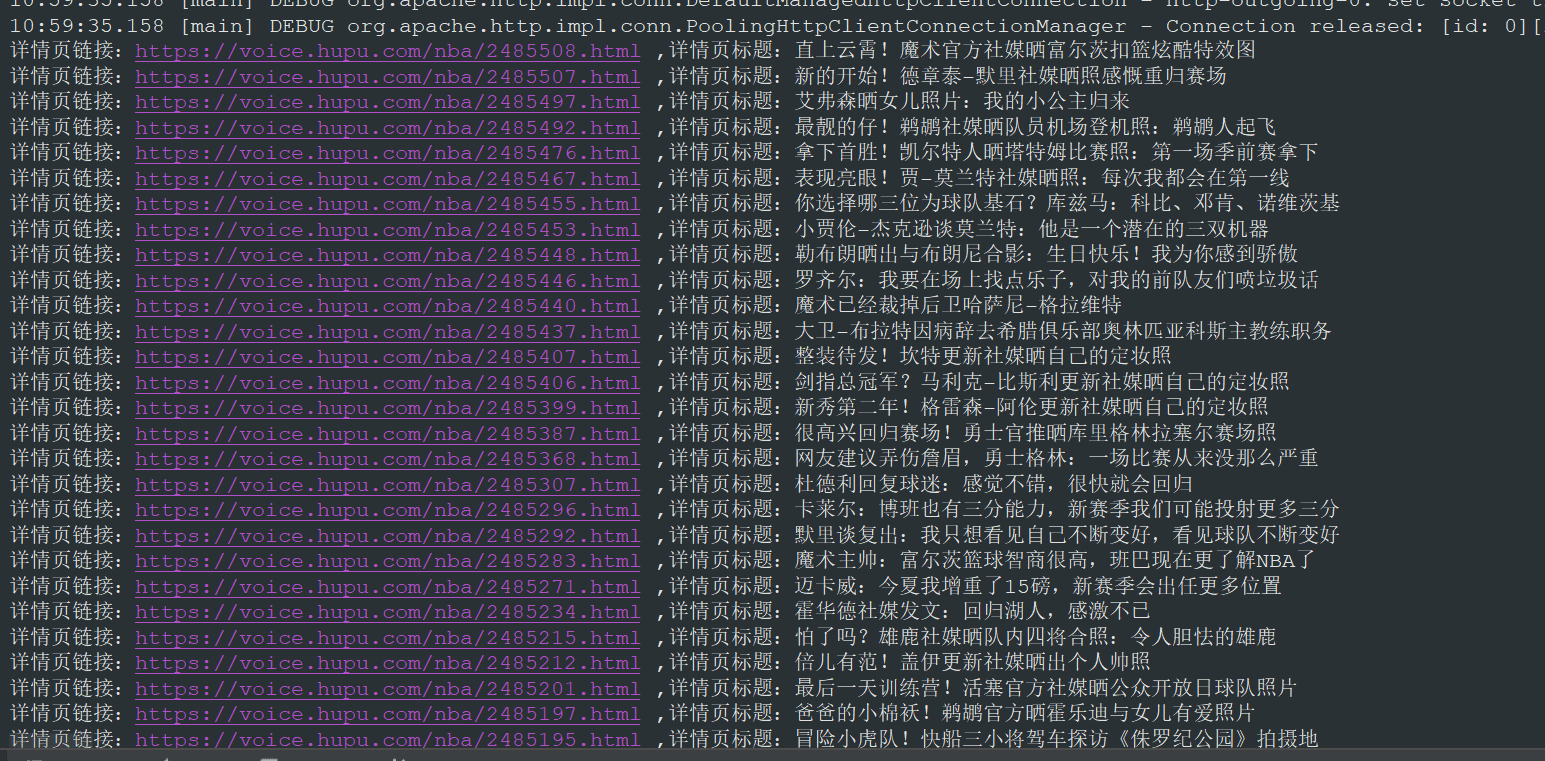
使用 httpclient + 正则表达式的方式同样正确的获取到了列表新闻的标题和详情页链接。这一篇主要是 Java 网络爬虫的入门,我们使用了 jsoup 和 httpclient + 正则的方式提取了虎扑列表新闻的新闻标题和详情页链接。当然这里还有很多没有完成,比如采集详情页信息存入数据库等。
以上是“Java网络爬虫的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





