HadoopеҰӮдҪ•е®үиЈ…
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢHadoopеҰӮдҪ•е®үиЈ…пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
дёҖгҖҒHadoopзҡ„е®үиЈ…
1. дёӢиҪҪең°еқҖпјҡhttps://archive.apache.org/dist/hadoop/common/жҲ‘дёӢиҪҪзҡ„жҳҜhadoop-2.7.3.tar.gzзүҲжң¬гҖӮ
2. еңЁ/usr/local/ еҲӣе»әж–Ү件еӨ№zookeeper
mkdir hadoop
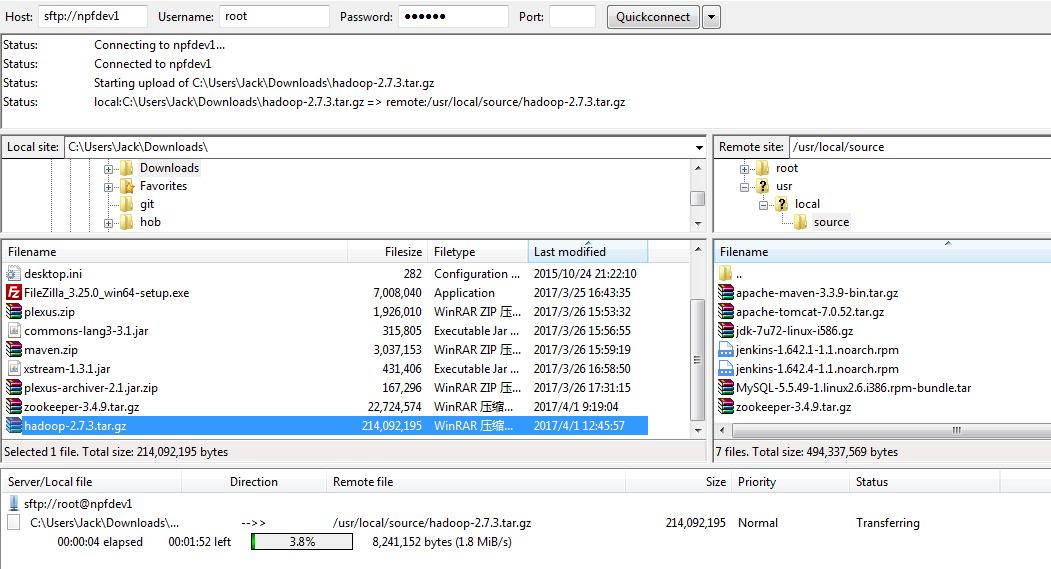
3.дёҠдј ж–Ү件еҲ°LinuxдёҠзҡ„/usr/local/sourceзӣ®еҪ•дёӢ
3.и§ЈеҺӢзј©
иҝҗиЎҢеҰӮдёӢе‘Ҫд»Өпјҡ
tar -zxvf hadoop-2.7.3.tar.gz-C /usr/local/hadoop

4. дҝ®ж”№й…ҚзҪ®ж–Ү件
иҝӣе…ҘеҲ°cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/ , дҝ®ж”№hadoop-env.sh
иҝҗиЎҢ vimhadoop-env.sh,дҝ®ж”№JAVA_HOME

5.е°ҶHadoopзҡ„жү§иЎҢе‘Ҫд»ӨеҠ е…ҘеҲ°жҲ‘们зҡ„зҺҜеўғеҸҳйҮҸйҮҢ
еңЁ/etc/profileж–Ү件дёӯеҠ е…Ҙпјҡ
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin
жү§иЎҢ/etc/profileж–Ү件пјҡ
source /etc/profile
6. е°Ҷnpfdev1жңәеҷЁдёҠзҡ„hadoopеӨҚеҲ¶еҲ°npfdev2е’Ңnpfdev3е’Ңnpfdev4жңәеҷЁдёҠгҖӮдҪҝз”ЁдёӢйқўзҡ„е‘Ҫд»Өпјҡ
йҰ–е…ҲеҲҶеҲ«еңЁnpfdev2е’Ңnpfdev3е’Ңnpfdev4жңәеҷЁдёҠпјҢе»әз«Ӣ/usr/local/hadoopзӣ®еҪ•пјҢ然еҗҺеңЁnpfdev1дёҠеҲҶеҲ«жү§иЎҢдёӢйқўе‘Ҫд»Өпјҡ
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev2:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev3:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev4:/usr/local/hadoop/
и®°дҪҸпјҡйңҖиҰҒеҗ„иҮӘдҝ®ж”№npfdev2е’Ңnpfdev3е’Ңnpfdev4зҡ„/etc/profileж–Ү件:
еңЁ/etc/profileж–Ү件дёӯеҠ е…Ҙпјҡ
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin
жү§иЎҢ/etc/profileж–Ү件пјҡ
source /etc/profile
然еҗҺеҲҶеҲ«еңЁnpfdev1е’Ңnpfdev2е’Ңnpfdev3е’Ңnpfdev4жңәеҷЁдёҠ,жү§иЎҢhadoopе‘Ҫд»ӨпјҢзңӢжҳҜеҗҰе®үиЈ…жҲҗеҠҹгҖӮ并且关й—ӯйҳІзҒ«еўҷгҖӮ
7. зЎ®е®ҡжүҖжңүжңәеҷЁд№Ӣй—ҙеҸҜд»Ҙзӣёдә’pingйҖҡпјҢдҪҝз”ЁдёӢйқўзҡ„е‘Ҫд»Өпјҡ
(1). ping npfdev1
(2). ping npfdev2
(3). ping npfdev3

(4). ping npfdev4
8. еҗҜеҠЁhadoopпјҡ
жҲ‘们иҝҷйҮҢе°Ҷnpfdev1дҪңдёәmaster,npfdev2е’Ңnpfdev3е’Ңnpfdev4еҲҶеҲ«дҪңдёәдёүеҸ°slaveгҖӮ
(1).дҝ®ж”№й…ҚзҪ®ж–Ү件core-site.xml
иҝӣе…Ҙ cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop
е…·дҪ“й…ҚзҪ®еҰӮдёӢпјҡ
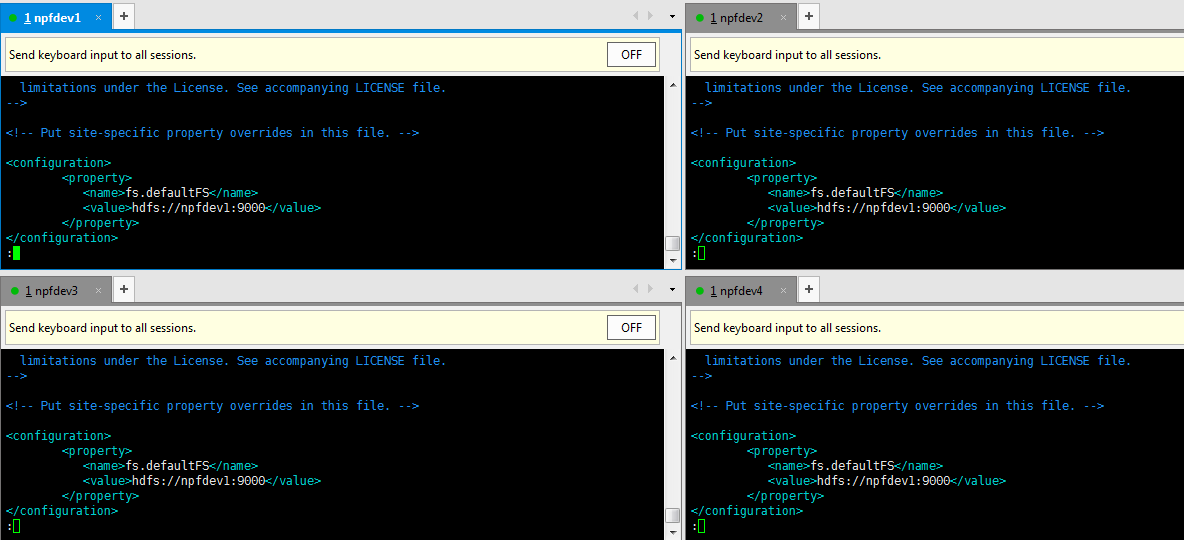
(2).еңЁmasterжңәеҷЁnpfdev1дёҠеҗҜеҠЁnamenode
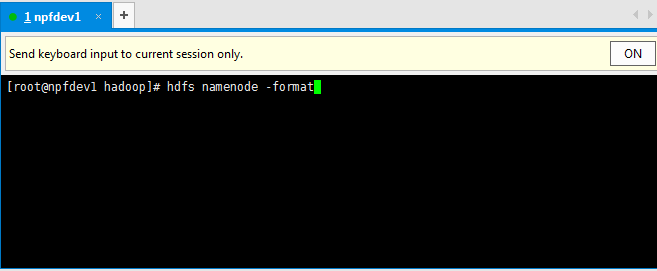
йҰ–е…ҲйңҖиҰҒж јејҸеҢ–namenodeпјҢ第дёҖж¬ЎдҪҝз”ЁйңҖиҰҒж јејҸеҢ–пјҢеҗҺжқҘе°ұдёҚйңҖиҰҒдәҶгҖӮ
hdfs namenode -format
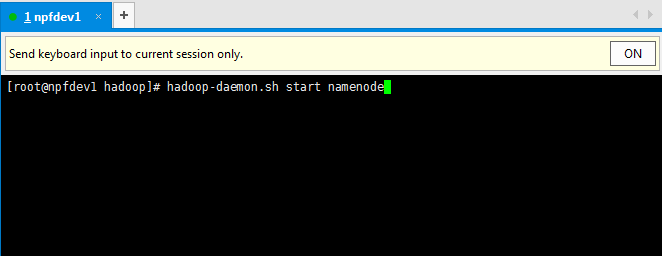
然еҗҺеҗҜеҠЁnamenodeпјҡ
hadoop-daemon.sh start namenode
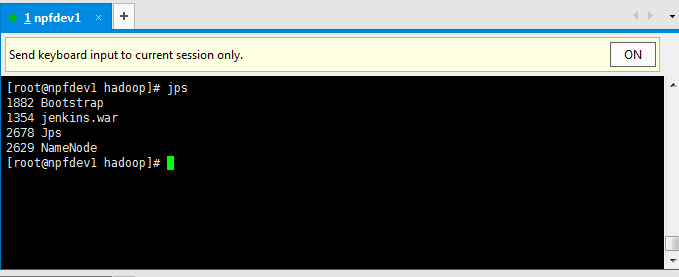
йҖҡиҝҮjpsе‘Ҫд»ӨжҹҘзңӢпјҢеҰӮжһңжңүnamenodeзҡ„javaиҝӣзЁӢпјҢе°ұиҜҙжҳҺжҲ‘们еҗҜеҠЁnamenodeжҲҗеҠҹгҖӮ
(3).еңЁslaveжңәеҷЁnpfdev2,npfdev3,npfdev4дёҠеҗҜеҠЁdatanode
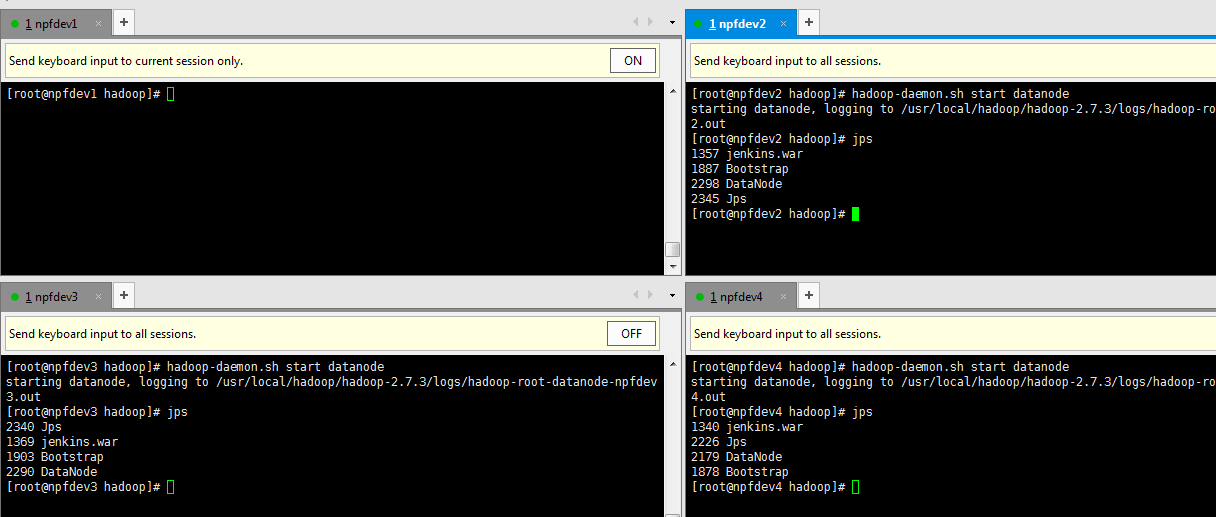
д»ҘдёҠжҳҜвҖңHadoopеҰӮдҪ•е®үиЈ…вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





