这篇文章将为大家详细讲解有关易语言如何制作语音聊天机器人,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
常量数据表
.版本 2 .常量 对话前, "<文本长度: 7>", , text":" .常量 对话后, "<文本长度: 2>", , "} .常量 token前, "<文本长度: 16>", , "access_token":" .常量 双撇号, "<文本长度: 1>", , " .常量 apikey, "<文本长度: 24>", , Tc9KWDDFPLm1QNVPgEx7kco6 .常量 Secretkey, "<文本长度: 32>", , DnqP3q2GwOqGuYI9sUhLT4l7uC2f1yVL .常量 识别返回前, "<文本长度: 10>", , result":[" .常量 识别返回后, "<文本长度: 3>", , "],
语音聊天机器人的代码
此功能需要加载精易模块5.6
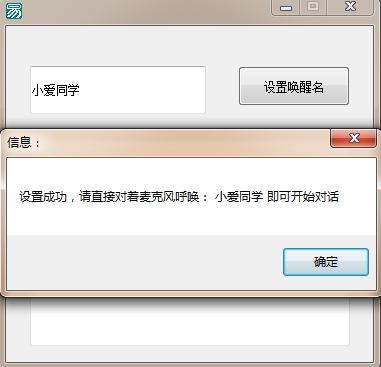
.版本 2 .支持库 eMMedia .支持库 ESpeechEngine .支持库 internet .支持库 spec .支持库 eAPI .程序集 窗口程序集_启动窗口 .程序集变量 API地址, 文本型 .程序集变量 APIkey, 文本型 .程序集变量 唤醒名, 文本型, , "0" .程序集变量 音量, 短整数型 .程序集变量 计时, 整数型 .程序集变量 最大频段, 整数型 .程序集变量 发送内容, 文本型 .子程序 _语音识别1_识别到语音 .参数 识别文本, 文本型 .如果真 (寻找文本 (识别文本, 唤醒名 [1], , 假) ≠ -1) ' 识别到唤醒名就开始录音。 录音音波1.打开 () ' 这个是检测麦克风音量的用的 最大频段 = 录音音波1.取上限 () - 1 播放音乐 (#开始声音, ) 设置唤醒按钮.标题 = “正在聆听” 录音1.录制 () ' 开始录音…… 判断是否说话时钟.时钟周期 = 10 ' 判断是否在说话的时钟。 .如果真结束 .子程序 _设置唤醒按钮_被单击 语音识别1.创建 (0, 1) ' 初始化语音识别引擎,初始化失败的需要下载微软的语音识别引擎Microsoft Speech SDK v5.1 加入成员 (唤醒名, 编辑框1.内容) 语音识别1.加入常用 (唤醒名) 信息框 (“设置成功,请直接对着麦克风呼唤: ” + 编辑框1.内容 + “ 即可开始对话”, 0, ) 设置唤醒按钮.禁止 = 真 .子程序 机器人对话, 文本型, , 调用图灵机器人API接口 .参数 发送的内容, 文本型 .局部变量 数据, 文本型 .局部变量 返回内容, 文本型 .局部变量 需要的内容长度, 整数型 数据 = 编码_gb2312到utf8 (发送的内容) ' ——————————先转换成utf8码 返回内容 = 到文本 (HTTP读文件 (“http://www.tuling123.com/openapi/api?key=bad4d07e4c1c439b935a922906176478&info=” + 数据 + “&loc=北京&userid=a1”)) ' ——————————发送给图灵 返回内容 = 编码_utf8到gb2312 (返回内容) ' —————————— 先把返回的数据转成简体中文的编码 调试输出 (返回内容) ' ——————————调试输出一下看看 需要的内容长度 = 取文本长度 (返回内容) - 寻找文本 (返回内容, #对话前, , 假) - 取文本长度 (#对话前) - 取文本长度 (#对话后) + 1 ' 全部的长度 - 前面文本所在位置 - 前面文本长度 - 后面文本长度 + 1,得出来的结果就是需要的文本长度 返回内容 = 取文本中间 (返回内容, 寻找文本 (返回内容, #对话前, , 假) + 取文本长度 (#对话前), 需要的内容长度) ' ——————————起始位置是前面文本所在位置 + 前面文本的长度 编辑框3.内容 = 返回内容 ' ——————————编辑框上显示出来 返回 (返回内容) .子程序 获取token, 文本型, , 获取百度验证信息 .局部变量 临时数组, 文本型, , "0" .局部变量 返回的文本, 文本型 .局部变量 token, 文本型 返回的文本 = 到文本 (HTTP读文件 (“https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=” + #apikey + “&client_secret=” + #Secretkey)) 临时数组 = 分割文本 (返回的文本, #token前, ) token = 取文本左边 (临时数组 [2], 寻找文本 (临时数组 [2], #双撇号, , 假) - 1) 返回 (token) .子程序 合成语音, , , 调用百度语音合成API接口 .参数 需要合成的文本, 文本型 .局部变量 句柄, 整数型 .局部变量 z, 文本型 .局部变量 返回的语音, 字节集 z = 需要合成的文本 z = 编码_gb2312到utf8 (z) ' 先转换成utf8编码 z = 编码_URL编码 (z) ' 再进行URL编码 媒体播放1.停止 () 媒体播放1.关闭 () ' 关闭正在播放的才能写出新的语音 返回的语音 = HTTP读文件 (“http://tsn.baidu.com/text2audio?tex=” + z + “&lan=zh&ctp=1&cuid=” + 取本机网卡物理地址 () + “&tok=” + 获取token () + “&pit=9”) 写到文件 (“C:\Users\Administrator\Desktop\1.mp3”, 返回的语音) 媒体播放1.打开 (“C:\Users\Administrator\Desktop\1.mp3”) 媒体播放1.播放 (-1, ) 调试输出 (“合成语音完成”) 设置唤醒按钮.标题 = “完成” .子程序 _判断播放状态时钟1_周期事件, , , 如果播放完了就关闭文件,这样才能写出新的文件 .判断开始 (媒体播放1.取状态 () = 2) 媒体播放1.关闭 () .默认 .判断结束 .子程序 _判断是否说话时钟_周期事件 录音音波1.取声波值 (音量, 2047) 音量 = 取绝对值 (音量) .判断开始 (音量 > 200) 计时 = 0 .判断 (计时 > 100) ' 时钟周期是10,如果连续100次(也就是1秒钟)音量都小于200就结束录音。这个作用就是1秒钟之内没说话就停止录音。 判断是否说话时钟.时钟周期 = 0 录音1.停止 () 播放音乐 (#结束声音, ) 设置唤醒按钮.标题 = “正在识别” 录音1.保存文件 (取运行目录 () + “\ly.wav”, 真) 合成语音 (机器人对话 (识别 ())) 计时 = 0 .默认 计时 = 计时 + 1 .判断结束 .子程序 识别, 文本型, , 调用百度语音识别API接口 .局部变量 MAC, 文本型 .局部变量 语言, 文本型, , , 中文=zh、粤语=ct、英文=en,不区分大小写,默认中文 .局部变量 返回内容, 文本型 MAC = 取本机网卡物理地址 () 语言 = “zh” 返回内容 = 编码_utf8到gb2312 (到文本 (网页_访问 (“http://vop.baidu.com//server_api?lan=” + 语言 + “&format=wav” + “&rate=8000” + “&channel=1” + “&cuid=” + MAC + “&token=” + 获取token (), 1, , , , “Content-Type:audio/wav;rate=8000;Content-length=999999”, , , 读入文件 (取运行目录 () + “\ly.wav”), ))) 返回内容 = 取文本中间 (返回内容, 寻找文本 (返回内容, #识别返回前, , 假) + 取文本长度 (#识别返回前), 寻找文本 (返回内容, #识别返回后, , 假) - 寻找文本 (返回内容, #识别返回前, , 假) - 取文本长度 (#识别返回前)) ' 取得需要的文本 调试输出 (“识别后的内容:” + 返回内容) 编辑框2.内容 = 返回内容 返回 (返回内容)
运行结果:
关于“易语言如何制作语音聊天机器人”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





