OK~ WSFC 2012 R2 年度盛宴开始~ 在本文中,老王将用一系列的场景,把动态仲裁,动态见证,票数调整,LowerQuorumPriorityNodeID,阻止仲裁等群集仲裁技术串起来,完成一个又一个复杂的场景,本篇文章可能并不太适合对于WSFC不了解的朋友,适合对于WSFC群集仲裁技术及2012动态仲裁技术有一定初步了解的朋友,如果您还不了解WSFC,建议您去先看下老王写过的博客,或者其它地方相关的资料,如果您对于WSFC仲裁,动态仲裁技术已经有了初步的了解,相信跟着老王这篇文章中的场景会帮助您更加深入的理解群集投票,动态仲裁等知识,话不多说,我们现在就开始,跟着老王上车吧,过山车开了~滴
开始之前先介绍环境,为了准备这次的博客,老王一共开了七台虚拟机,主要是为了重现一些真实的分区场景,之前在2008R2的时候,我们用了六台服务器,两边各两个节点,一台域控+ISCSI,一台路由服务器,但是只有一侧有域控,另外一侧没有域控,因此发生分区时,没有域控的一方是没办法上线联机抢夺群集的,虽然效果是一样的,最终两端出现分区,群集都无法使用,我们强制选择其中一方启动,在这次的环境里面老王特地用了七台服务器,两端都有域控,都可以形成群集的一个场景
环境介绍
北京站点
HV01
MGMET:80.0.0.2 GW:80.0.0.254 DNS:80.0.0.1 100.0.0.20
ISCSI:90.0.0.2
CLUS:70.0.0.2
HV02
MGMET:80.0.0.3 GW:80.0.0.254 DNS:80.0.0.1 100.0.0.20
ISCSI:90.0.0.3
CLUS:70.0.0.3
BJDC&ISCSI
Lan:80.0.0.1 GW:80.0.0.254
ISCSI:90.0.0.1
佛山站点
HV03
MGMET:100.0.0.4 GW:100.0.0.254 DNS:100.0.0.20 80.0.0.1
ISCSI:90.0.0.4
CLUS:70.0.0.4
HV04
MGMET:100.0.0.5 GW:100.0.0.254 DNS:100.0.0.20 80.0.0.1
ISCSI:90.0.0.5
CLUS:70.0.0.5
FSDC
Lan:100.0.0.20 GW:100.0.0.254
Router
03Route
Beijing:80.0.0.254
Fuosha:100.0.0.254
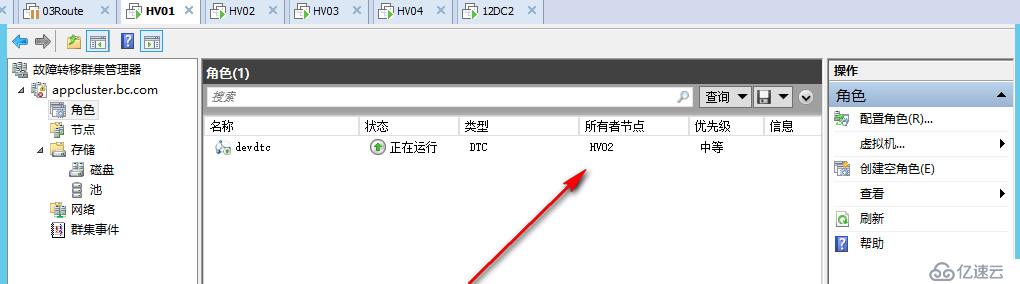
首先我们先来看一道开胃小菜,在这个场景中我们将模拟,一个四个节点的跨站点群集,在见证磁盘始终在线的情况下节点逐个宕机的场景,以下是老王已经组建起来的一个多站点群集,其中的群集名称和群集IP,可能在后面的图会变,因为实验过程中老王拆了又建了几次群集,不过其他架构都按照规划好的不会改变。

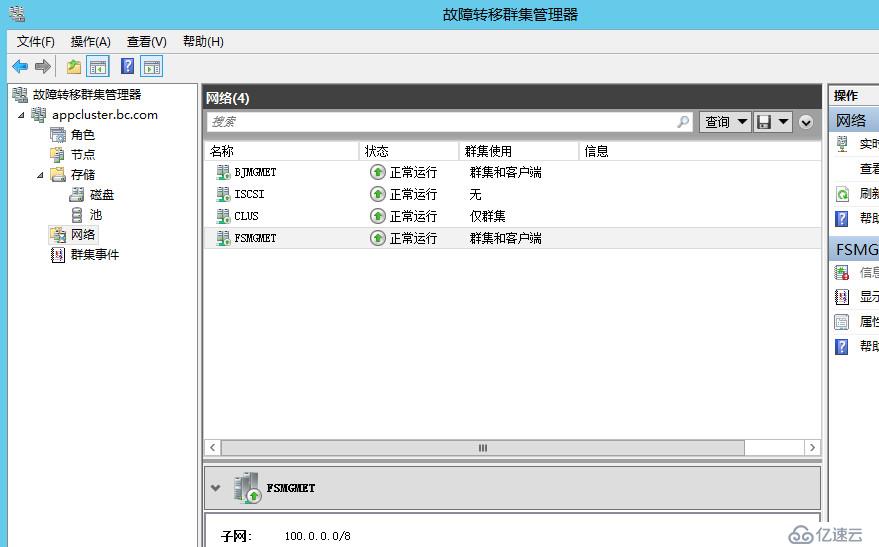
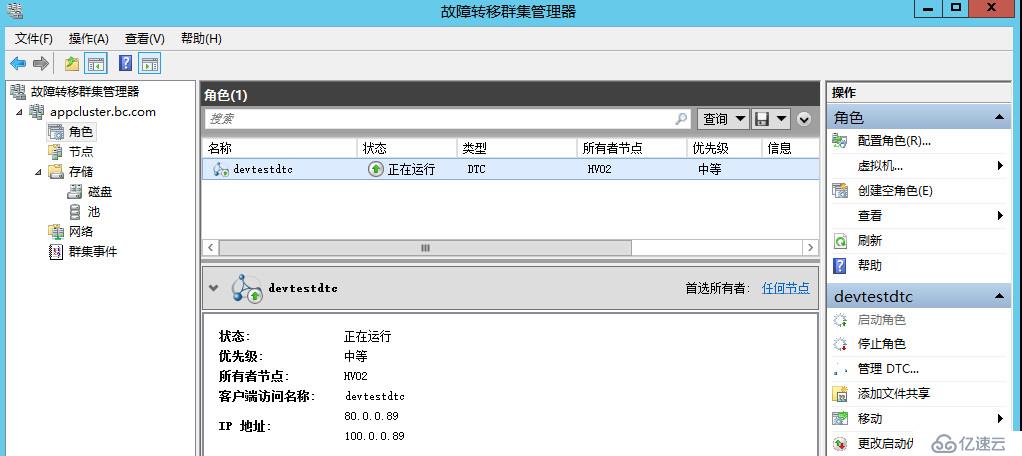
可以看到我们在群集中跑了一个DTC应用,当前DTC应用绑定了两个IP地址,它们之间是OR关系
在多站点群集的设计规划中有很多需要考虑的地方,例如存储复制,网络检测,加密处理,AD的同步,DNS的缓存等都会影响到多站点的故障转移时间,后续会单独写博客来详细讲,这里简单讲两个影响客户端直接访问的地方
默认情况下在多站点群集中,例如我们的DTC应用当前在北京站点运行,它的联机地址会是80.0.0.89,当它转移到佛山站点,联机地址会是100.0.0.89,但是这时候,客户端能不能访问DTC服务呢,不一定
设想一下,北京和佛山站点做了AD多站点,它们的DNS会相互同步,当DTC在北京站点时它是80.0.0.89,经过一段时间它同步到了佛山站点,佛山的DNS也知道了DTC是80.0.0.89这个地址,那么当北京站点宕机,转移到佛山站点了,虽然这时候DTC应用已经联机,但是当客户端访问DTC,会返回80.0.0.89这个地址,并不会返回100.0.0.89的可用地址,这也导致了停机时间的延迟
原因是由DNS的缓存机制导致,默认情况下群集应用联机后注册的主机记录都是会有1200秒的TTL,即是说,客户端如果请求了这个VCO的主机记录,1200秒以内,不会再重新请求了,会使用缓存中的地址
2008时代WSFC新增了用于多站点的HostRecordTTL属性,使我们可以设置VCO记录注册到DNS时的TTL,TTL生命周期现在可以进行缩短,微软建议缩短为300秒,即五分钟之后重新请求DNS新的地址
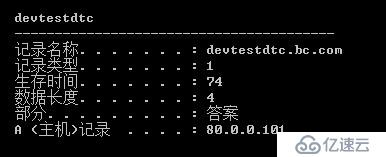
打开佛山站点的客户端,输入ipconfig /display可以看到被缓存的VCO记录和生存时间(TTL)
另外一个2008时代新增用于多站点的属性则是RegisterAllProvidersIP,正常情况下,我们的VCO即使你设计了多个地址,它们默认会是OR的关系,即始终只注册一个群集IP地址,当前在北京站点就是80网段的地址,当联机到佛山站点,则会有CNO替VCO去注册更新成100网段的地址,同一时间VCO默认只有一个站点的地址在线,通过RegisterAllProvidersIP属性我们可以让CNO去帮我们注册所有的VCO地址,但是这就要求群集应用支持地址重试
一个完美的场景应该是群集应用默认连接到80网段的地址,当80网段不可用,自动重试连接到100网段联机使用,因为所有地址都已经注册至DNS,所以可以减少由于DNS缓存导致的停机时间,在群集应用支持自动重试的话,可以使用这个属性 ,SQL Server 2012开始支持在连接字符串加入MultiSubnetFailover=True参数和RegisterAllProvidersIP配合使用,当连接其中一个地址不通,会自动连接另外一个
这里我们遵循微软的建议,配置DTC应用的HostRecordTTL为300
设置方法如下
#获取群集应用资源名称
Get-ClusterResource | Select Name, ResourceType
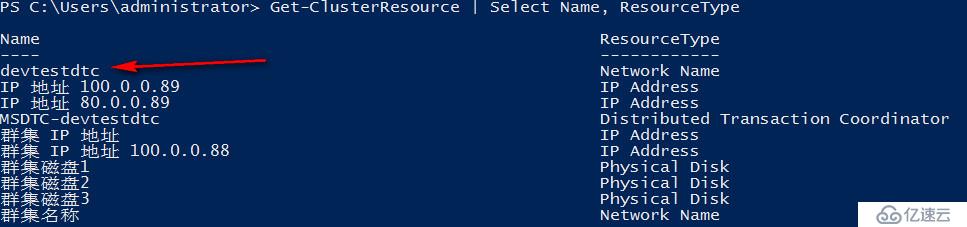
#获取群集应用资源属性
Get-ClusterResource "devtestdtc" | Get-ClusterParameter
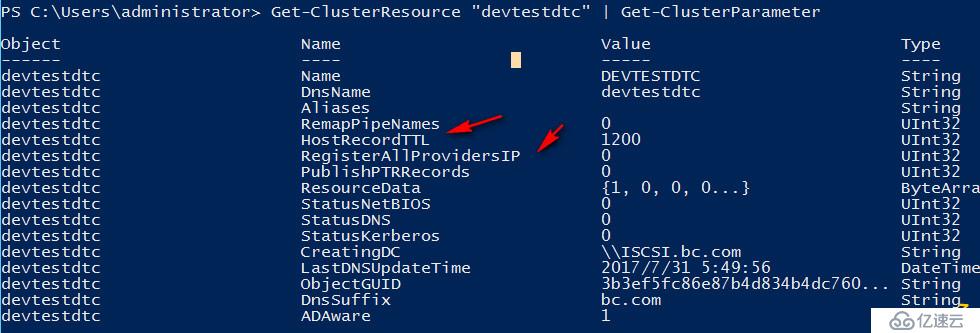
#修改HostRecordTTL属性,脱机再联机可以看到设置已经生效
Get-ClusterResource "devtestdtc" | Set-ClusterParameter HostRecordTTL 300

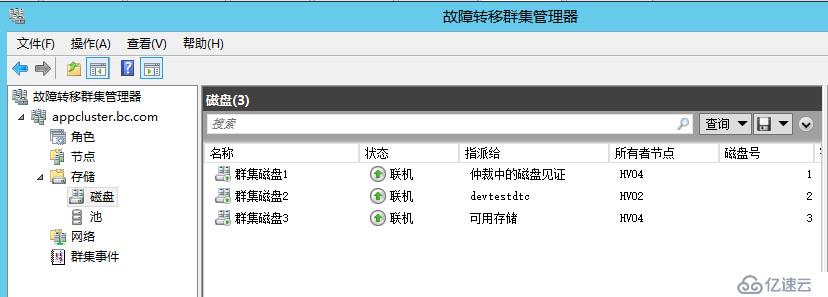
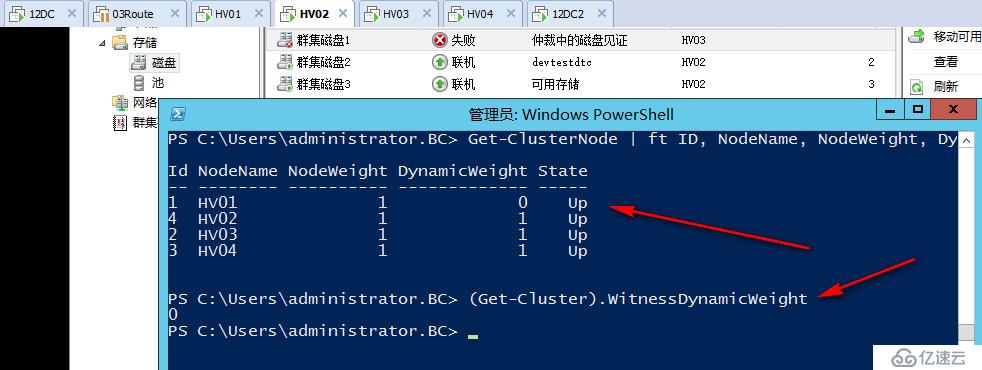
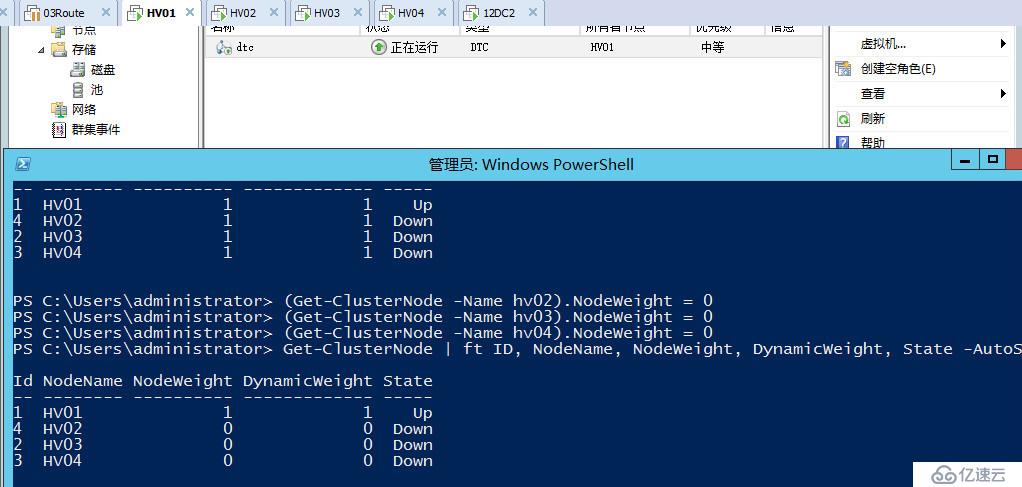
辅菜说完,下面来看我们的正菜,可以看到目前我们是四个节点的群集,见证磁盘可以正常参与投票
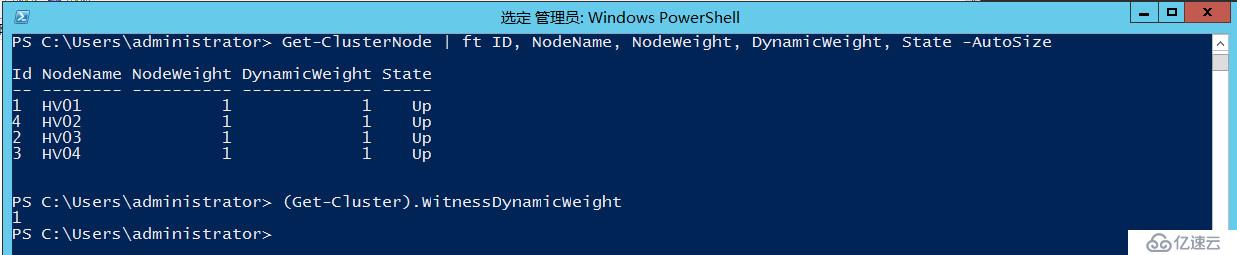
#查看节点投票数
Get-ClusterNode | ft ID, NodeName, NodeWeight, DynamicWeight, State -AutoSize
#查看见证投票数
(Get-Cluster).WitnessDynamicWeight
这两个命令后面我们会经常用到
当前群集DTC正常运行在HV01
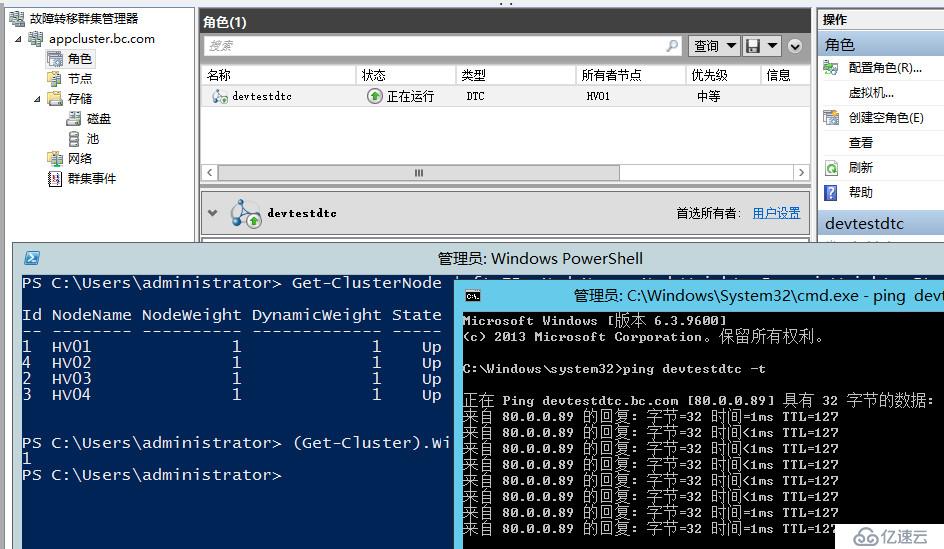
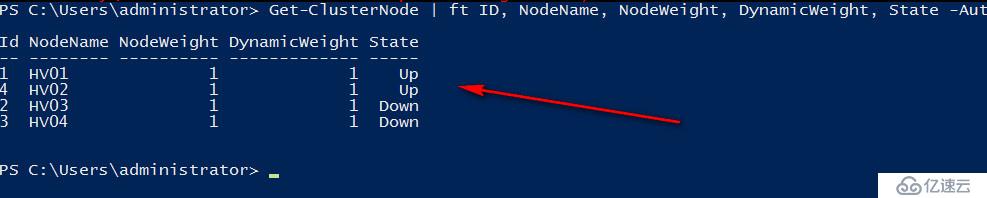
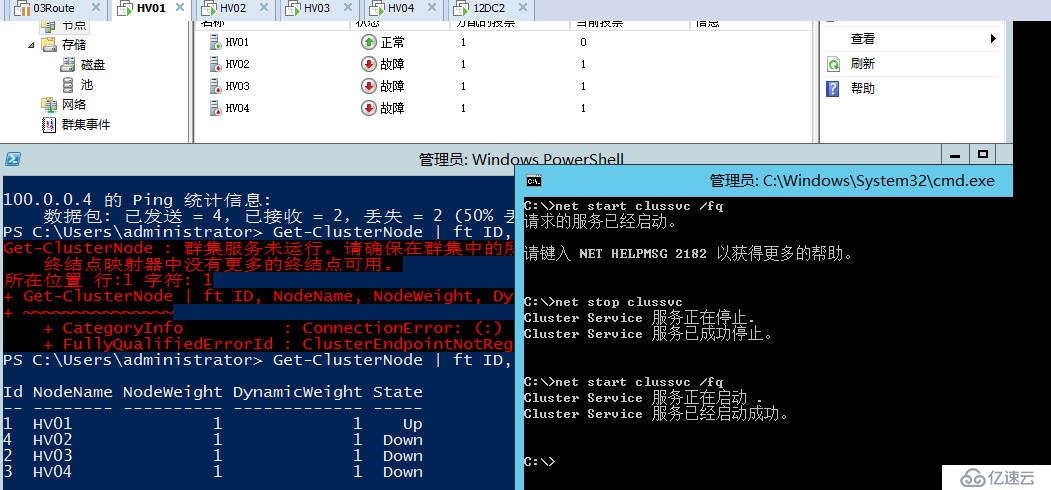
我们直接将HV01进行断电操作,可以看到群集应用自动转移至HV02,HV01已下线所以去掉了它的投票,同时由于现在是4票,所以自动去掉了见证磁盘的一票,始终保证投票数为奇数。

直接将HV02也断电,我们彻底失去了北京站点,可以看到现在又自动加上了见证磁盘的一票,现在群集还是三票,我直接强制DNS服务器更新,然后在客户端ipconfig /flushdns了,此时再尝试联devtestdtc则会返回100网段的地址,如果不清除DNS缓存,可以等300秒时间到了,再次请求自动更新至100网段
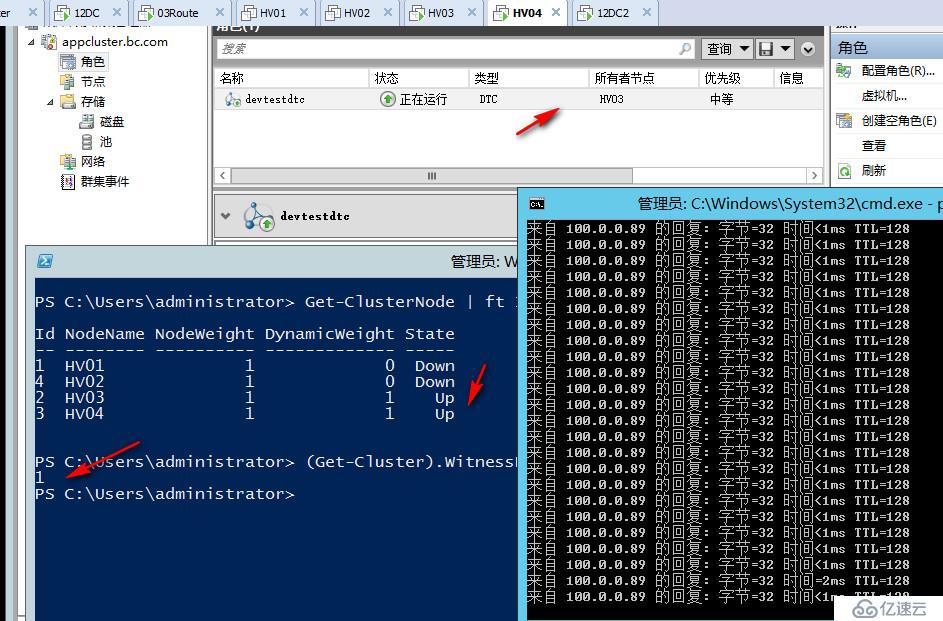
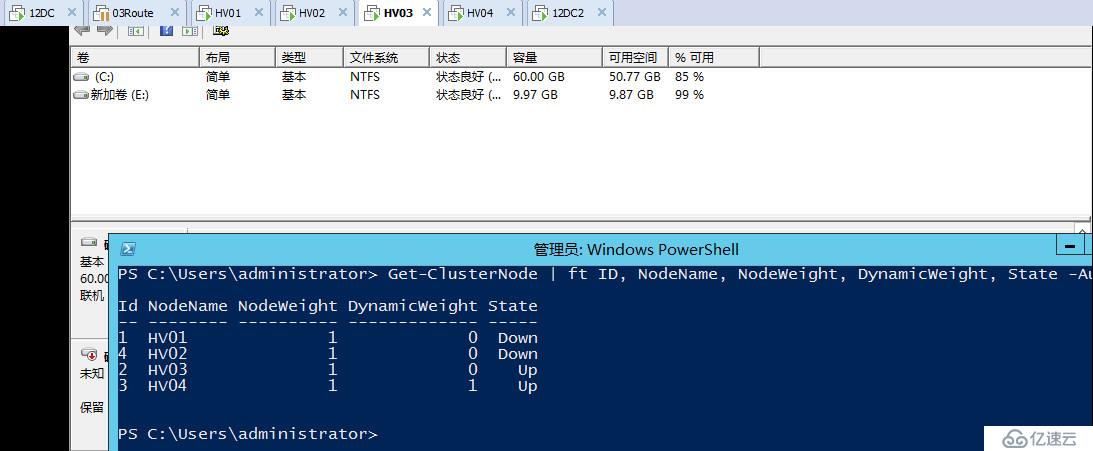
DTC当前在HV03上面运行,我们再把HV03也断电,现在群集只剩下HV04,可以看到现在群集会显示三票,但其实已经不重要了,因为我们只剩下一个节点,他可以和见证磁盘联系,因此可以存活至最后。
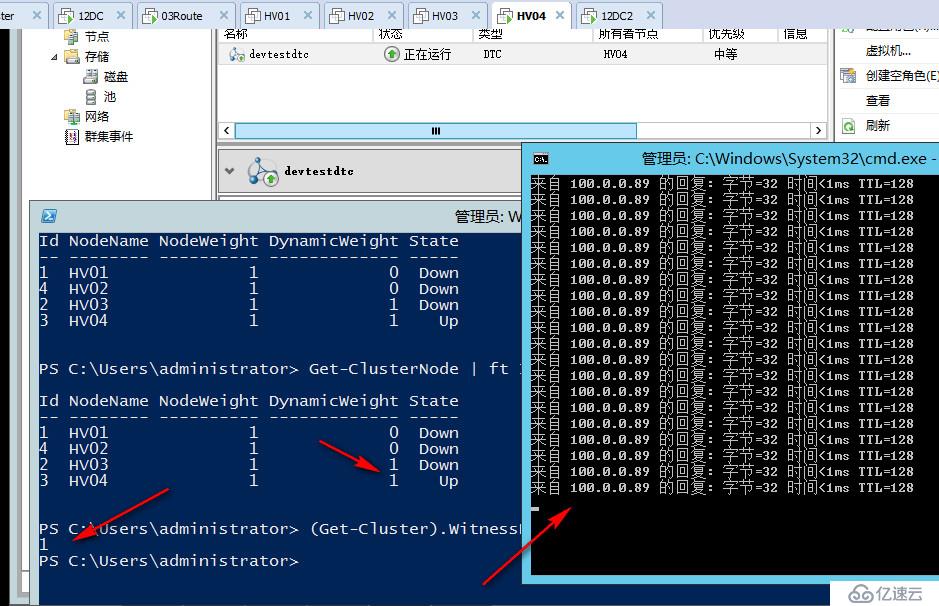
以上是我们的第一道小菜,怎么样,还算简单开胃把,可以看出在见证磁盘在情况下,群集节点逐步宕机,WSFC2012R2会始终动态的调整群集投票,确保群集投票始终是奇数,即始终一方可以存活,最后可以只剩下一个节点和见证存活。
接下来我们来模拟第二个场景,北京站点和佛山站点的管理网络失去联系,即80网络和100网络不通,我们直接关掉路由服务器,为了防止其中一方联系到见证磁盘获胜,我们也模拟见证磁盘失去联系
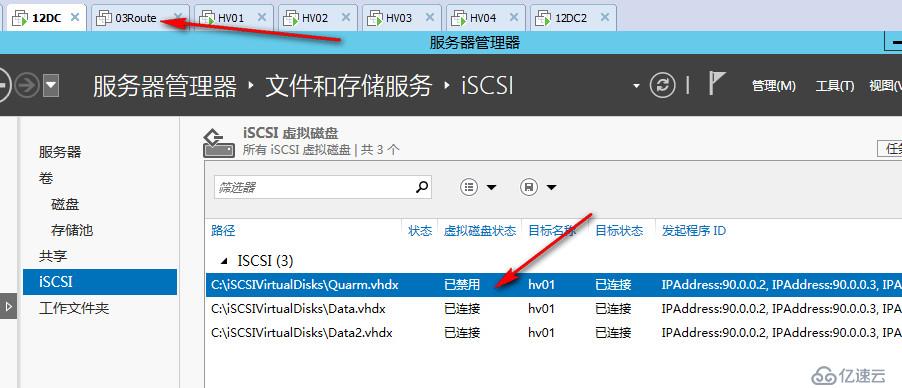
这时候我们可以看到,群集检测到见证磁盘失效,已经自动调整三个节点投票数为奇数
另外可以看到我们把管理网络断开了,群集依然可以正常工作,为什么呢,因为群集内置的网络拓扑生成器会实时自动生成调整全网检测的拓扑,管理网络既可以对外访问也可以做心跳检测,心跳网络只可以做心跳检测,因此只要不影响群集节点之间心跳检测,是不会有任何反应的。
群集并不会知道你的管理网络故障,因为在北京站点管理网络可以正常访问,在佛山站点管理网络也可以正常访问,群集就以为它是好的,心跳检测还有其它卡可以进行嘛
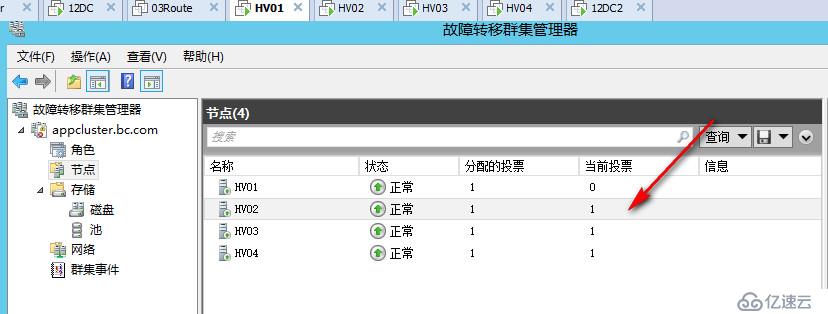
假设现在这家公司的员工都从佛山出差来北京办公,即所有的用户都要在北京80网段的客户端访问,但是如果这时候群集DTC忽然漂移佛山去了,虽然它在佛山也可以正常工作,但是北京站点的用户都访问不到那边,因为我们知道佛山站点100网段已经和外界失去联系
默认如果不做调整群集应用,DTC是应用是随机漂移的,不一定会漂到那个节点去,可能看那个节点内存多,它就过去哪里了,一旦漂到佛山站点的服务器就惨了
这时我们可以通过以下手段进行控制,首先设置DTC的习惯节点为HV01,HV02,这样如果当前DTC托管在北京,当它发生故障转移的时候,会优先考虑转移到HV01或HV02
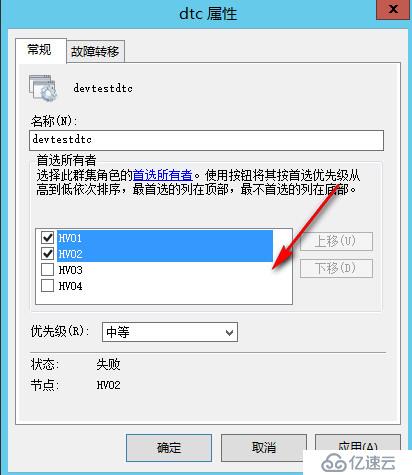
但是仅仅设置首选所有者还是不够的,因为设置首选所有者,只是在没有发生分区的情况下会有用,当发生了一个网络分区,HV01 HV02没办法与HV03 HV04联系,这时由于HV01没有投票数,而HV03 HV04一方有投票数,所以应用还是会转移到佛山站点运行
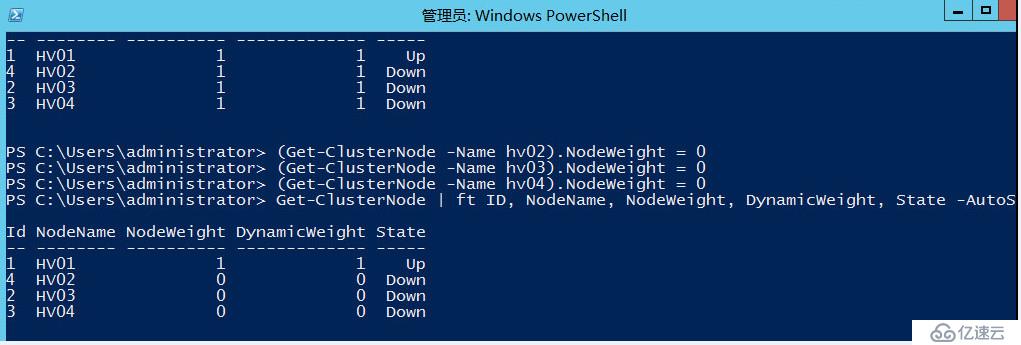
应对这种场景,我们可以彻底去掉HV03,HV04站点的投票数,这样做了之后,即便发生一个网络分区,北京站点剩下一票,佛山站点两票,但因为我们去掉了佛山站点两台服务器的投票数,所以佛山站点会尝试形成群集,但是始终是没办法成功的,因为他们没有合法的票数。
即是说我们通过手动去掉投票数,让佛山的两个节点永远也没办法形成群集,要不然就访问北京的节点,北京的节点一旦无法启动,群集应用就停止访问或强制启动。
#手动去掉群集投票数
(Get-ClusterNode -Name hv03).NodeWeight = 0
(Get-ClusterNode -Name hv04).NodeWeight = 0
在2008和2008R2中可以通过添加一个Hotfix来获得手动控制节点的投票的功能,2012及之后则WSFC自带

以上是手动调整群集投票数的场景之一,即我们知道一方的站点已经无法对外提供访问服务,需要让该站点始终停止对外服务,直到网络恢复再重新赋予投票数
手动调整投票数老王认为是很有用处的一项技术,除了这种已知站点无法对外提供的场景,在其它很多场景下也都有用武之地
例如在一个完全手动故障的场景,有北京,天津,河北三个站点,只有北京站点的节点有投票,手动取消了天津和河北的投票,因为当故障发生时,可能要举行一个灾难恢复会议,商讨一下,当前由那个站点继续承担群集更合适,例如商讨天津站点当前更合适承担群集,手动赋予天津站点节点票数,节点检测到当前有投票,于是天津站点启动形成群集,继续对外提供服务
或者还有一个场景,假设当前有北京站点,河北站点两个站点,两个节点各有两个节点,当前群集一共四个节点,我手动去掉了河北站点其中一个节点的投票,让它始终不参与群集投票,这时假设群集发生了故障,北京站点和河北站点的三个节点都已经无法启动提供服务,我们可以强制启动去掉投票的节点,重新赋予它票数,让它继续对外提供服务,或者北京站点宕机,强制仲裁后所有业务都跑到河北站点的一个节点运行,已经把机器的负载跑满,这时候可以把去掉投票的节点重新赋予投票,一起承担负载,这样作为一个灾备节点来使用。
接下来我们假设当前群集是动态仲裁,群集见证磁盘先失效,继而管理网络也失效,心跳网络也失效,出现一个分区时的场景
针对网络分区,我们到时除了把路由服务器关了,也把HV03 HV04的心跳网卡直接改了个网络
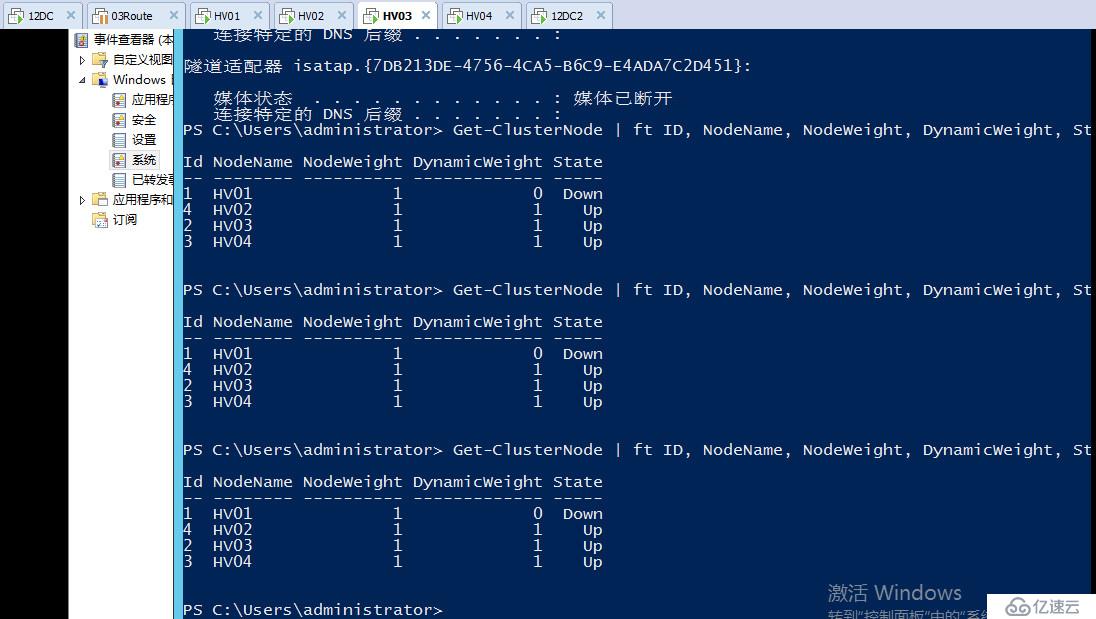
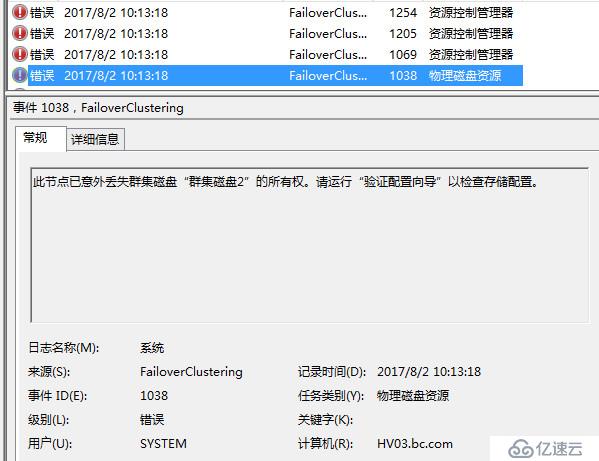
针对见证磁盘失效,我们还是依旧采用直接ISCSI上面禁用磁盘的方式,可以看到大概过了30秒左右,仲裁检测到了见证磁盘已经处于非联机状态,于是自动去掉了它的票数,同时也随机去掉了一个节点的票数,现在群集变成了三票

仲裁磁盘会按照故障转移策略,在各个节点尝试联机挂起
都尝试失败后会显示为失败状态,过一段时间会在尝试联机挂起,但始终不会成功
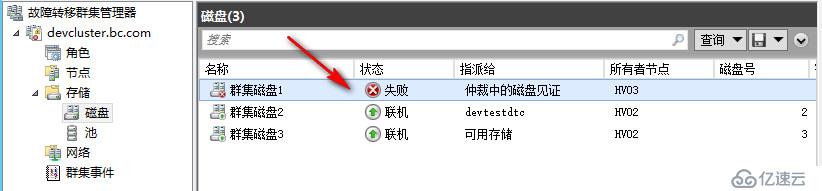
可以看到现在由于见证磁盘失败,仲裁已经动态的调整了投票数,又随机去掉了一个节点的投票数,现在群集还是奇数三个投票
如果这时一个网络分区发生,北京站点与佛山站点没办法心跳检测,没有网卡可以用于检测,这时候佛山的站点会获胜,继续对外提供服务,而北京站点则会关闭
因为北京站点被选中去掉了一个投票,只有一票,而佛山站点有两票,所以佛山站点可以形成群集,形成群集后佛山站点又自动去了一票,现在佛山站点也是奇数投票数
大家可以看到,这里的核心在于,群集选择去掉那个站点的投票,被去掉投票的站点,当发生投票时会被关闭,默认情况下群集会根据各个节点的状态变化,网络监测情况,不断的去调整票数,每次都会随机选择去掉投票站点的节点是谁,这有点像是每次都要随机抓一个倒霉蛋,反正都是抓,那么我们可不可以控制每次固定抓一个人呢,答案是可以的
通过2012R2里面新增的LowerQuorumPriorityNodeID属性,我们可以控制在偶数节点下,让动态仲裁始终去掉指定节点的投票,实现当发生50/50网络分区时始终是我们想要的站点获胜,或者在两个节点的情况下,最终动态仲裁要随机去掉一个节点的投票,我们也可以根据情况事前指定,始终去掉指定节点的投票。
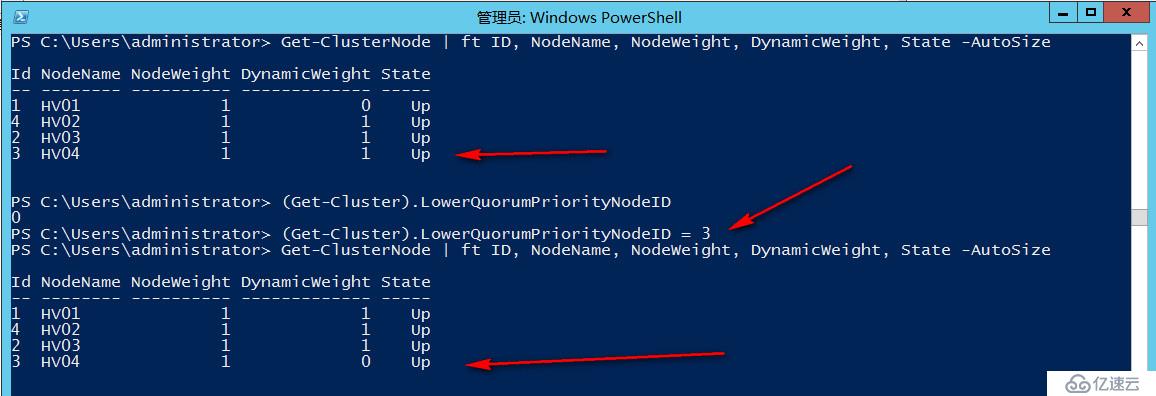
#查看当前LowerQuorum节点,默认是0,即每次发生变化时随机调整
(Get-Cluster).LowerQuorumPriorityNodeID

#获取节点ID,手动设置每次偶数投票数时丢弃HV04节点投票,每次都确保北京站点获胜
(Get-Cluster).LowerQuorumPriorityNodeID=3
当再次发生网络分区时可以看到,佛山站点关闭,北京站点存活下来,并自动调整为奇数投票

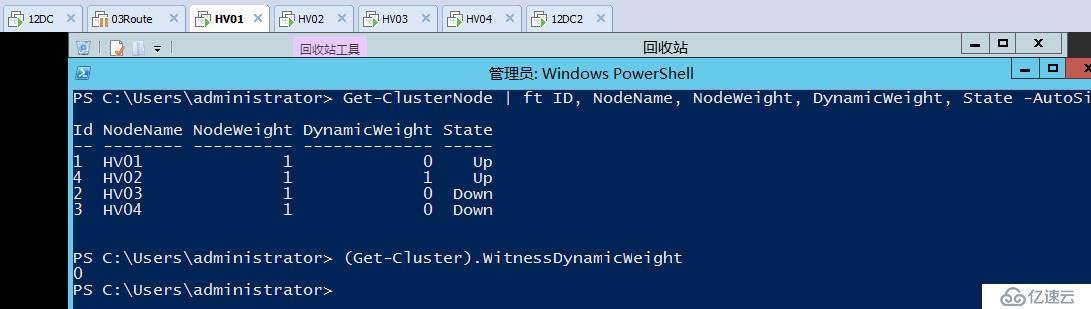
群集应用也始终正常运行着
以上为老王给朋友们上来的第二道菜和第三道菜
第二道菜我们在一个已知站点故障的情况下,手动取消了该站点的投票,阻止应用迁移到上面提供服务,这里我们是假设的一个没有分区的场景,因为两端还是可以通过心跳网卡互相做心跳检测的,我们在北京站点设置取消佛山站点的投票,佛山站点是可以知道的,如果是心跳网卡也发生了故障,即两边没办法进行进行心跳检测,这时候就要分情况来看,如果分区之前我们已经设置好了取消投票的站点,那么很好,群集会选择没被设置取消投票的站点启动,如果已经出现分区之后,那么只有强制启动需要的少数站点,启动之后再设置取消另外站点的投票,当另外站点上线时会以强制仲裁方为主。
第三道菜呢,默认情况下在见证磁盘失效的动态仲裁场景中,当发生偶数投票节点的情况下会动态随机为我们去掉一个节点的票数,我们可以通过LowerQuorumPriorityNodeID属性来手动下降一个站点,确保当中间网络分区发生时,始终是自己想要的站点获胜
因此大家可以看出,在动态仲裁存在的场景下,我们几乎很少会用到强制仲裁,因为我们有很多新的技术可以选择,例如LowerQuorumPriorityNodeID,事前手动调整投票数,强制仲裁在一些场景下也或许有用,尤其是2012R2之后,阻止仲裁技术发生了改变,多数节点一方检测到少数节点一方存在仲裁会自动执行阻止仲裁操作,即确保承认强制仲裁一方为群集,与其群集数据库同步至最新后,才会启动自身群集服务,在之前2008时代,如果遇到强制仲裁的场景下,大多数时间都需要手动去执行阻止仲裁,否则会出现群集数据库覆盖等情况,到了2012R2则会自动帮助我们做这件事
所以老王给大家的建议是,按照场景选择合适的技术,能通过手动调整投票解决或者通过LowerQuorumPriorityNodeID解决就尽量不用强制仲裁,2012R2之前使用强制仲裁需要考虑阻止仲裁问题,2012R2不需要考虑。
实际上在动态仲裁启动的情况下,绝大部分场景动态仲裁都能帮助我们保证群集的可用性,始终让群集保持奇数投票,即便动态仲裁默认选择的站点你不满意,也可以用LowerQuorumPriorityNodeID,票数调整,强制仲裁等技术切换到满意的站点,像是以前50/50的脑裂分区场景,在动态仲裁的情况下是很难见到了,因此如果想看到脑裂场景最好的办法就是关闭动态仲裁
在第四道菜中,我们将模拟一个脑裂场景,北京佛山两个站点,关闭动态仲裁的情况下,禁用见证磁盘,两端出现网络分区时心跳网络和管理网络都已关闭,没办法进行站点间心跳检测
#确认群集动态仲裁状态,默认为1,修改为0
(Get-Cluster).DynamicQuorum = 0

紧接着我们触发网络分区,修改HV03和HV04心跳网卡为其它网段,然后暂停路由服务器,让两端管理网络和心跳网络都不能互相做站点间的心跳检测,但是在各自站点内又都可以正常和AD通信

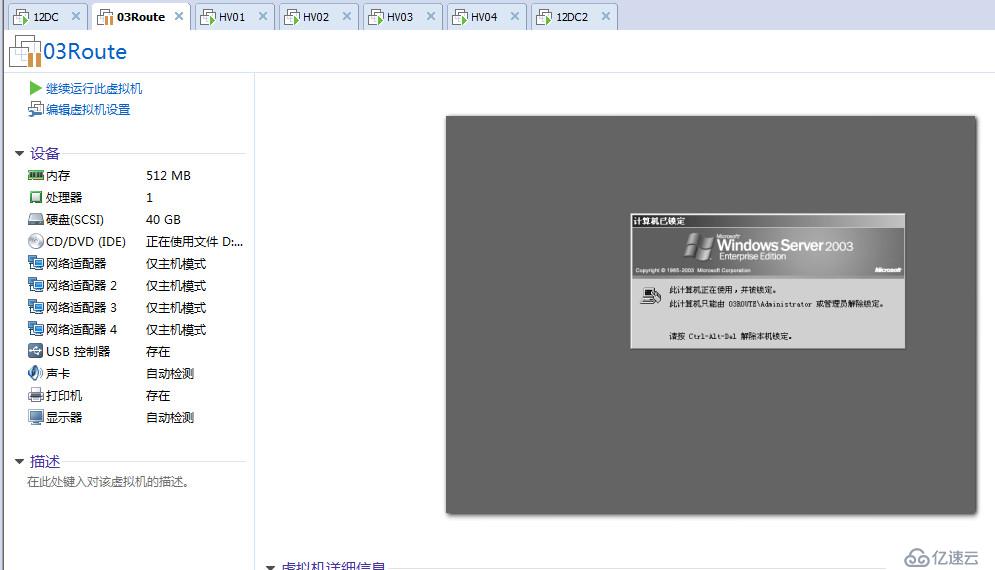
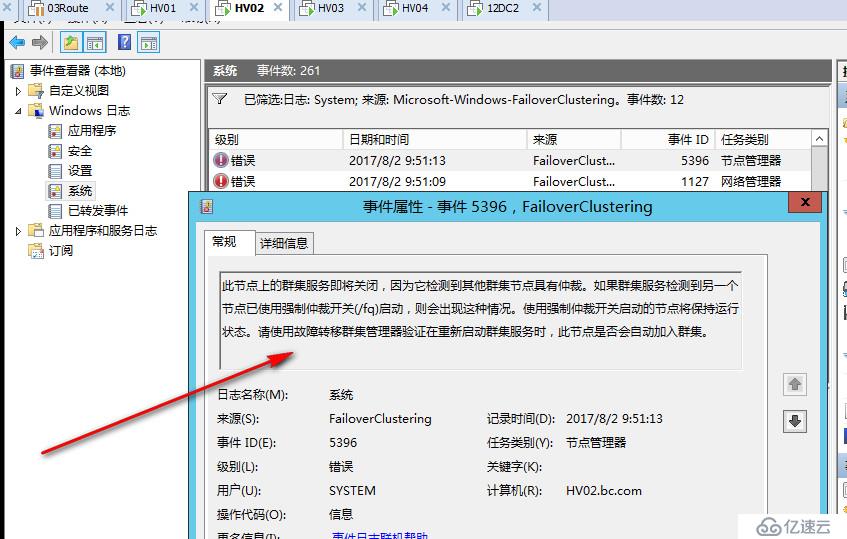
这时打开各个节点上面可以看到日志,提示群集网络已分区
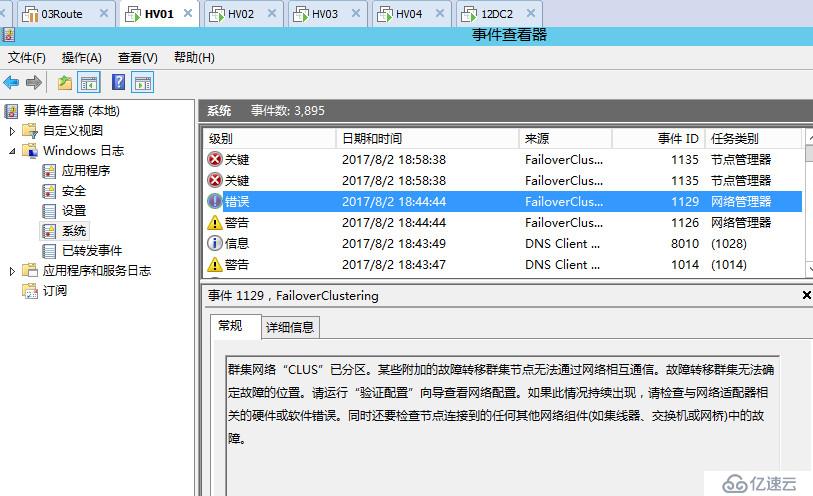
运行查看投票数节点命令,可以看到当前所有节点,都在各自站点尝试形成加入群集

但是这种状态仅维持不到20秒,再次运行命令就会看到群集服务已经停止
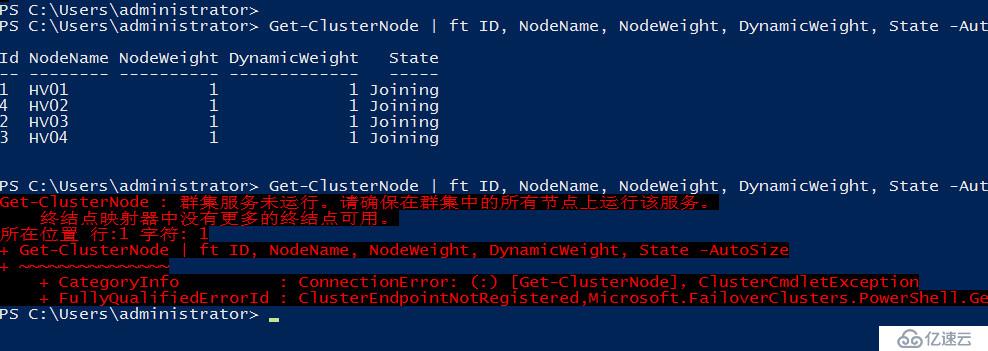
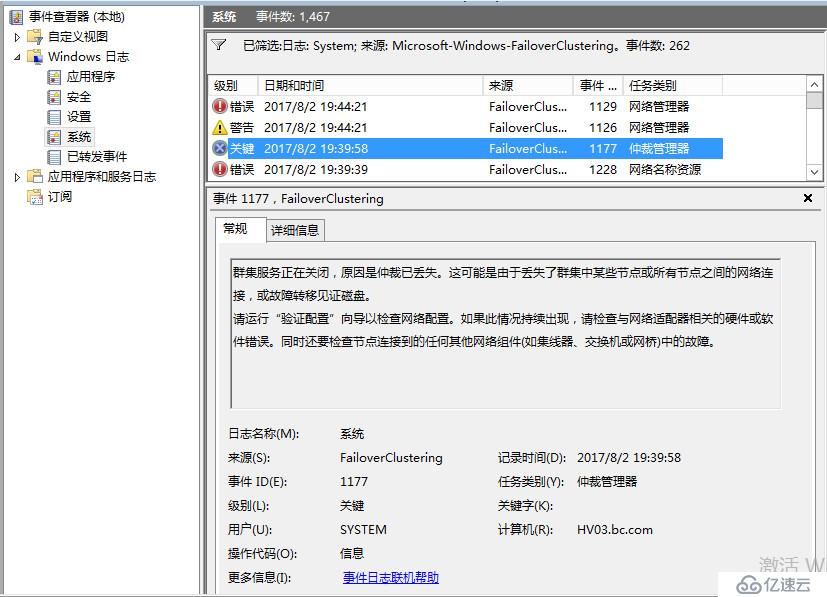
在每个节点的事件管理器都可以看到关于群集服务停止的系统日志
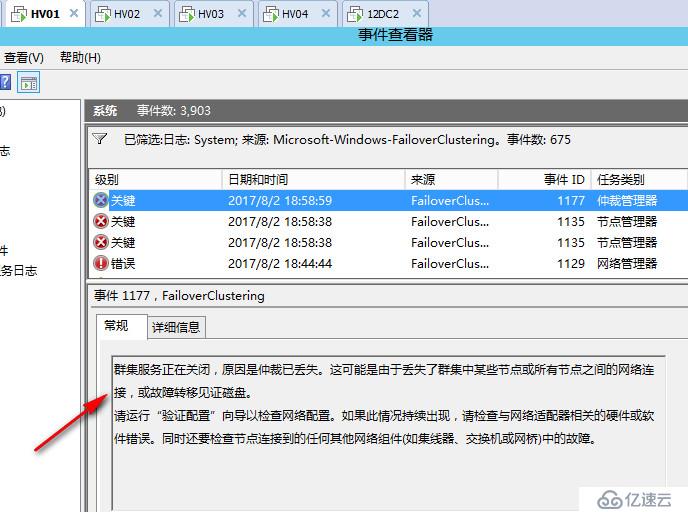
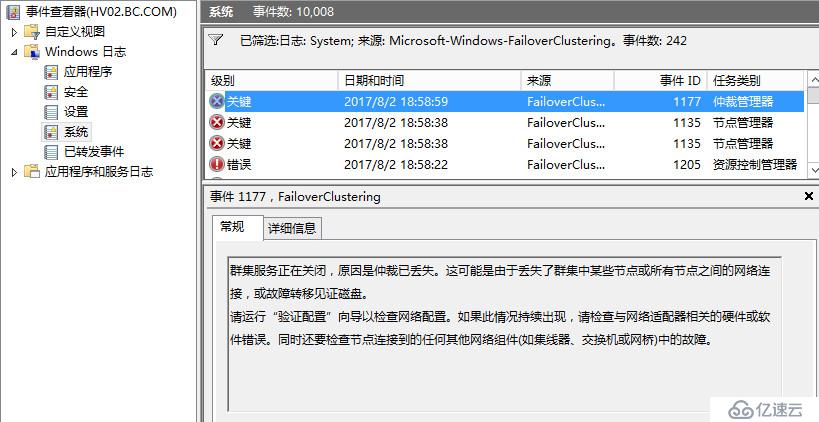

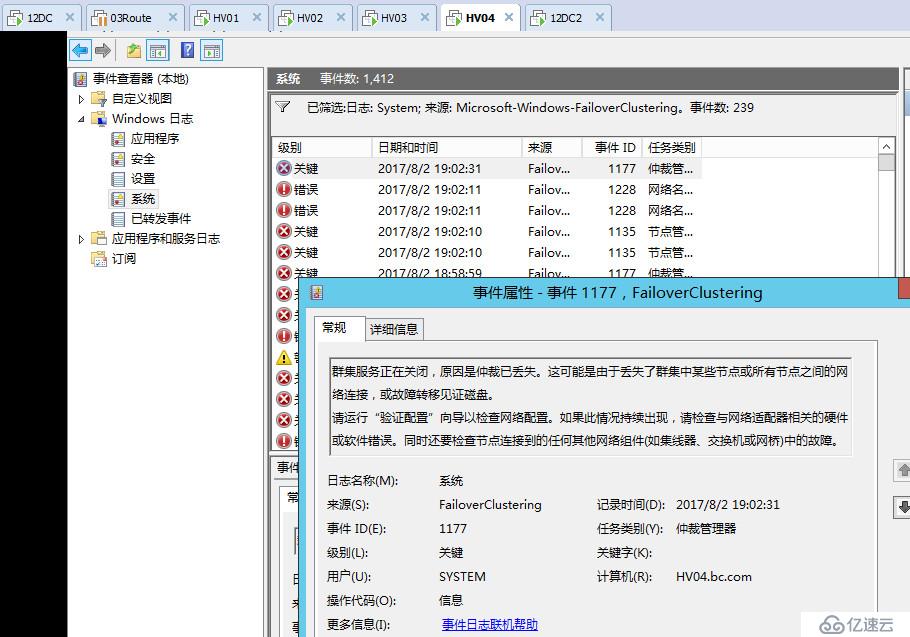
可见当出现脑裂分区时,群集会出现短暂的争夺阶段,紧接着群集仲裁会检测到当前发生分区,之后会关闭所有群集节点,老王并没有看到网上说的发生仲裁时各个分区各自生成群集,然后争夺写入群集磁盘的场景,或许时间太短了没有看到,或许是2012开始针对于脑裂分区做了优化,检测到脑裂会自动关闭,不过老王实际看到的效果就是这样,我感觉这样都关了也好,谁也别抢,让管理员手动选择
假设这时管理员判定当前权威站点应该是北京站点,手动在HV01上面执行强制启动命令
#强制启动HV01
net stop clussvc
net start clussvc /FQ
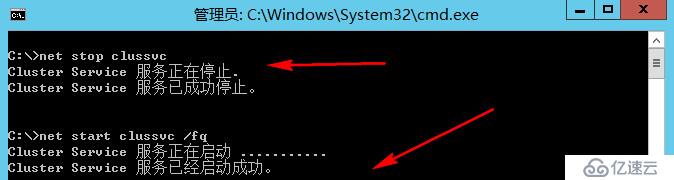
HV01上面首先运行查看节点投票数命令,首先会看到HV01的投票,紧接着HV02由于和HV01是一个分区内,检测到这一方发生强制仲裁,他会优先融入进来,状态会先是Joining,最终变成Up

实际上在这一步的时候,老王是希望看到一个东西的效果,什么呢,就是阻止仲裁的效果,老王在10/90这种比例下,强制仲裁了10的一方之后,当剩下的90网络联机之后,可以在日志看到阻止仲裁的日志,但是在50/50比例下,当各节点网络恢复正常后,老王没看到这个日志
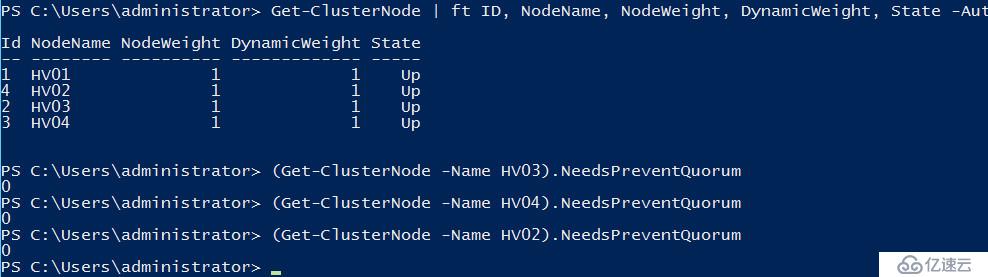
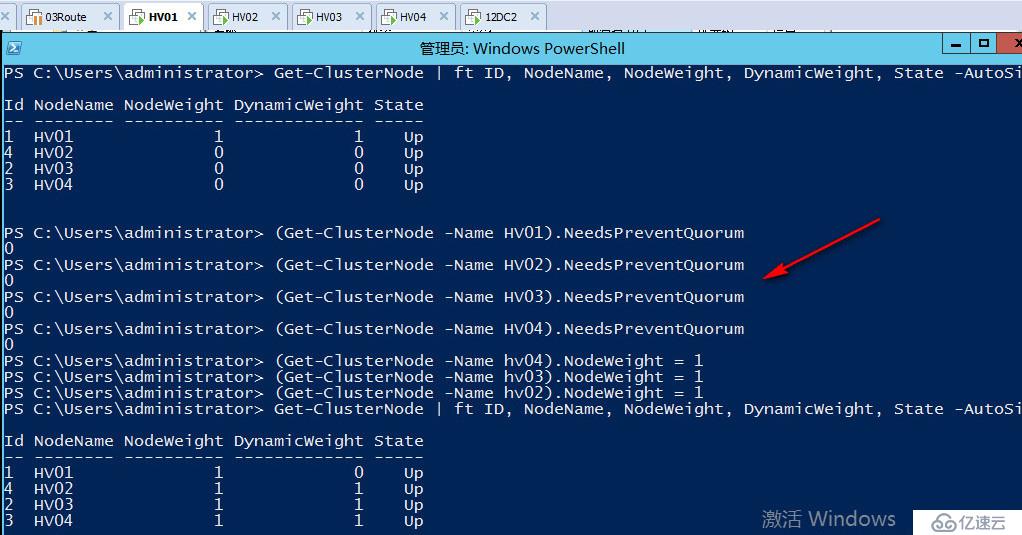
但是当老王尝试用命令查看节点阻止仲裁状态的时候却可以看到
#查看各阻止仲裁状态 1代表节点目前需要阻止仲裁,0代表节点当前不需要阻止仲裁
(Get-ClusterNode -Name HV02).NeedsPreventQuorum
(Get-ClusterNode -Name HV03).NeedsPreventQuorum
(Get-ClusterNode -Name HV04).NeedsPreventQuorum
可以看到节点2已经去掉了阻止仲裁的状态,3和4节点仍需要阻止仲裁

什么是阻止仲裁呢,在上面老王也提到过一点,阻止仲裁简单来讲,就是让其它节点遵守强制仲裁分区的技术,我们用强制仲裁之后,会把强制仲裁节点的paxos标记提至最高,即成为群集内最权威的存活节点,你们其它所有节点的群集数据库都要以我的为准,阻止仲裁就是为了配置强制仲裁的这个目标,当其它节点网络连通后可以和强制仲裁节点通信,节点会检测到当前环境内存在强制仲裁的节点,我应该以他为首,我不应该形成群集,即使我是多数节点的一方,然后群集服务会暂时停止,直到可以阻止仲裁节点的群集数据库完全和强制仲裁一方同步一致之后,才可以重新加入强制仲裁启动节点形成的群集分区
在2012R2之前,遇到阻止仲裁的场景,尤其是10/90场景,你强制启动了少数,是需要手动在其他站点执行阻止仲裁的,2012R2开始支持这种检测到强制仲裁,自动阻止仲裁。
可以看到当佛山节点恢复和北京站点通信后,经过一段时间,节点的阻止仲裁状态也变成了0,并且正常上线加入了强制仲裁方形成的群集分区
最后一道菜我们来尝试一个反转性的场景,假设当前北京站点有1个节点,佛山站点有3个节点,佛山站点发生了网络故障,虽然佛山内部三个节点可以通信,但是它们无法对外提供服务,我们需要强制反转至北京节点提供服务,本场景见证磁盘禁用,群集启用动态仲裁
#重新启用群集动态仲裁
(Get-Cluster).DynamicQuorum = 1

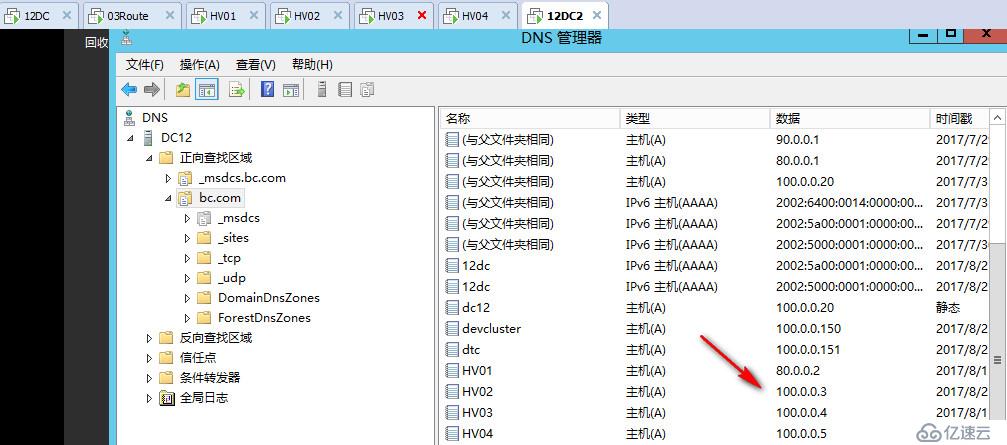
修改HV02为100.0.0.3,网关为100.0.0.254,DNS设置为100.0.0.20 80.0.0.1

#重新注册网卡DNS记录
ipconfig /registerdns

确保两个站点的DNS上面都记录了HV02的新地址
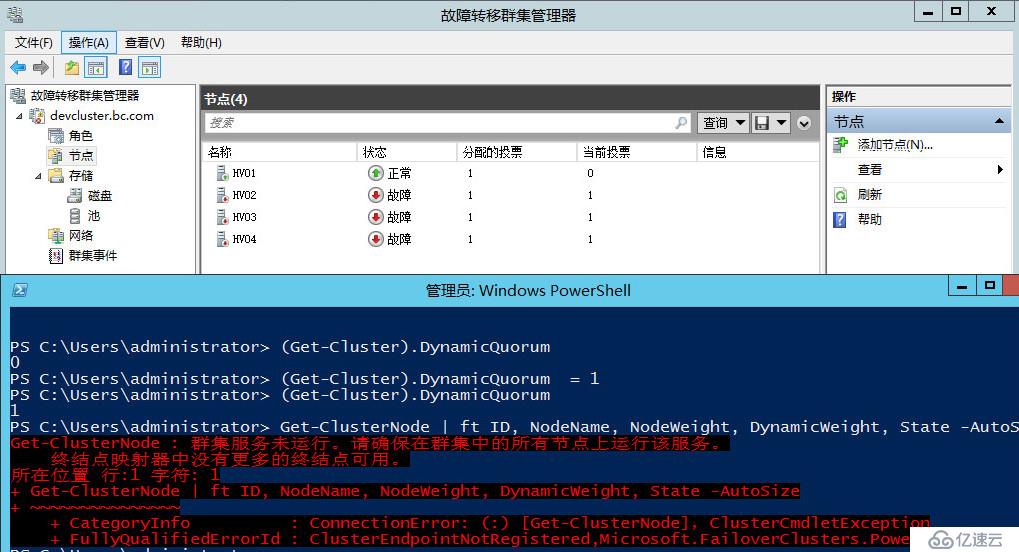
直接将HV02 HV03 HV04三个节点的群集网卡都改到同一个网络,然后暂停路由服务器
这时候在HV01上面运行查看群集节点投票数的命令可以看到群集服务已停止
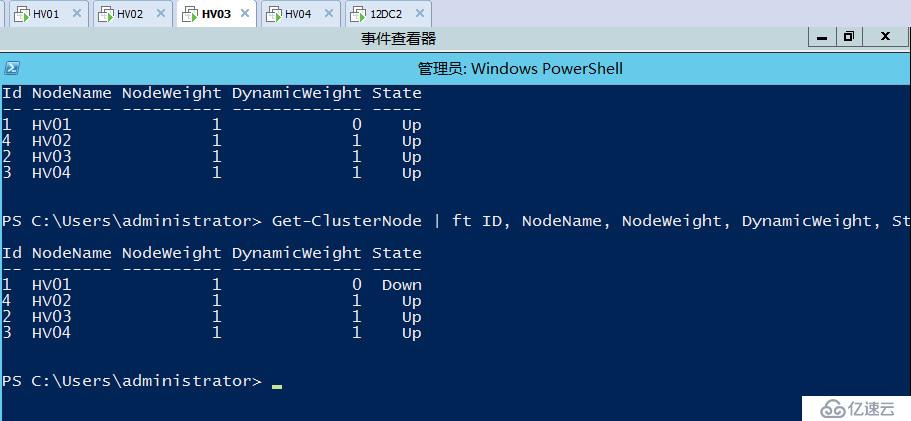
如果在HV03上面运行查看群集投票的命令则可以看到当前群集已经在佛山站点顺利形成,因为这边占据多的投票数,所以北京站点的群集目前会被关闭
#使用命令强制仲裁启动北京站点的群集
net stop clussvc
net start clussvc /FQ
启动完成后可以看到,在北京站点现在可以看到群集节点投票状态了,同时也提升了paxos标记,更新HV01的群集数据库为最新
由于HV02 HV03 HV04还没有和HV01联网,没办法知道北京站点那边发生了强制仲裁,所以还会尝试形成群集,在HV03上面查看群集投票状态,可以看到还是旧的记录
这时我们在北京站点上面需要做一件事,由于现在北京站点和佛山站点依然都可以访问存储,所以当应用在北京站点联机的时候,可能会出现失败的情况,因为佛山有三个节点也在和我抢群集磁盘,所以当务之急是取消掉佛山站点的投票数,防止和北京站点抢占资源
#手动取消佛山站点节点投票数
(Get-ClusterNode -Name hv02).NodeWeight = 0
(Get-ClusterNode -Name hv03).NodeWeight = 0
(Get-ClusterNode -Name hv04).NodeWeight = 0
需要注意的一点,这里如果需要执行去掉节点投票的操作,一定要在强制仲裁方进行,因为一旦在多数节点方执行,当再次网络通信的时候也会被强制仲裁方的记录盖掉,不会生效。
之后我们再次将群集应用联机,可以看到这时候实际上HV01已经从佛山站点抢夺过来了群集磁盘,佛山的三个站点再也没办法抢占群集资源,因为群集磁盘已经在权威一方重新上线,现在群集应用可以始终在北京站点运行
当佛山三个站点网络修复完成后,试图加入北京站点的群集分区时,可以在日志中看到阻止仲裁的日志,目前节点状态不会是UP,只有当佛山三个站点承认北京站点为权威一方,并且群集数据库已经和北京站点同步一致后,才可以正常加入群集。
经过一段时间后,可以看到佛山节点已经都完成阻止仲裁,正常加入群集,最后我们再重新为佛山节点赋予投票,让佛山节点可以正常参加故障转移,赋予投票后,群集仲裁会检测到当前恢复四个节点,又将根据动态仲裁机制自动选择节点去掉一票,实现始终奇数投票。
以上为老王通过实践得出的一点经验之谈,写这篇文章时老王的愿景是通过不断的实验把动态仲裁,动态见证,票数调整,LowerQuorumPriorityNodeID,阻止仲裁这些技术反复验证明白,然后通过场景的形式尽可能形象的讲出来,告诉朋友们具体都是什么样的功能,应该如何使用,希望能够用更多的人知道2012R2群集的这些技术,越来越多的人来真正的使用群集,研究群集,群集绝不只是一根心跳线,一个存储,把节点连起来就完了,里面很多东西都值得我们花心思去研究,用心去研究技术,自然会找到乐趣。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



