и®°5.28еӨ§дҝғеҺӢжөӢзҡ„жҖ§иғҪдјҳеҢ–вҖ”зәҝзЁӢжұ зӣёе…ій—®йўҳ
зӣ®еҪ•пјҡ
1.зҺҜеўғд»Ӣз»Қ
2.з—ҮзҠ¶
3.иҜҠж–ӯ
4.з»“и®ә
5.и§ЈеҶі
6.еҜ№жҜ”javaе®һзҺ°
еәҹиҜқе°ұдёҚеӨҡиҜҙдәҶпјҢжң¬ж–ҮеҲҶдә«дёӢеҚҡдё»еңЁ5.28еӨ§дҝғеҺӢжөӢжңҹй—ҙи§ЈеҶізҡ„дёҖдёӘжҖ§иғҪй—®йўҳпјҢи§үеҫ—иҝҷдёӘиҝҳжҳҜжҜ”иҫғжңүж„ҸжҖқзҡ„пјҢеҖјеҫ—жҖ»з»“жӢҝеҮәжқҘеҲҶдә«дёӢгҖӮ
еҚҡдё»жүҖжңҚеҠЎзҡ„йғЁй—ЁжҳҜдҪңдёәе…¬е…ұдёҡеҠЎе№іеҸ°пјҢе…¬е…ұдёҡеҠЎе№іеҸ°ж”ҜжҢҒдёҠеұӮжүҖжңүдёҡеҠЎзі»з»ҹпјҲ2CгҖҒUGCгҖҒзӣҙж’ӯзӯүпјүгҖӮе№іеҸ°дёӯж ёеҝғд№ӢдёҖзҡ„е°ұжҳҜи®ўеҚ•еҹҹзӣёе…іжңҚеҠЎпјҢдёӢеҚ•жңҚеҠЎгҖҒжҹҘеҚ•жңҚеҠЎгҖҒж”Ҝд»ҳеӣһи°ғжңҚеҠЎпјҢеҪ“然结算йЎөжҡӮж—¶иҝҳжҳҜжҲ‘们иҙҹиҙЈпјҢз»“з®—йЎөиҙҹиҙЈжүҝдёҠеҗҜдёӢиҝӣиЎҢдёӢеҚ•гҖҒз»“з®—гҖҒи·іж”Ҝд»ҳдёӯеҝғгҖӮжҜҸж¬ЎдёҡеҠЎж–№иҝӣиЎҢеӨ§дҝғжңҹй—ҙе№іеҸ°йғҪиҰҒиҝӣиЎҢдёҖ次常规еҺӢжөӢпјҢеҒҡеҲ°еҝғйҮҢжңүеә•гҖӮ
еңЁеҺӢжөӢзҡ„дёҠеҚҠеңәпјҢйҷҶз»ӯзҡ„и§ЈеҶідёҖдәӣдёҚжҳҜеӨӘеҘҮжҖӘзҡ„й—®йўҳпјҢе®ҡдҪҚеҲ°й—®йўҳж—¶й—ҙйғҪеңЁи®ЎеҲ’еҶ…гҖӮдёӢеҚ•жңҚеҠЎгҖҒжҹҘеҚ•жңҚеҠЎгҖҒз»“з®—йЎөйғҪйЎәеҲ©еҺӢжөӢйҖҡиҝҮгҖӮдҪҶжҳҜеҲ°дәҶж”Ҝд»ҳеӣһи°ғжңҚеҠЎеҺӢжөӢзҡ„ж—¶еҖҷпјҢжңүдёӘеҘҮжҖӘзҡ„й—®йўҳеҮәзҺ°дәҶгҖӮ
1.зҺҜеўғд»Ӣз»Қ
жҲ‘们жҜҸе№ҙеҹәжң¬дёӨж¬ЎеӨ§дҝғпјҢ5.28гҖҒеҸҢ12гҖӮдёӨж¬ЎеӨ§дҝғжңҹй—ҙзӣёйҡ”ж—¶й—ҙд№ҹе°ұеҸӘжңүеҚҠе№ҙе·ҰеҸіпјҢжүҖд»ҘжҜҸж¬ЎеӨ§дҝғеҺӢжөӢйғҪдјҡеҝғйҮҢжңүзӮ№дҪҺпјҢеҹәжң¬е°ұжҳҜж‘ёеә•жЈҖжҹҘдёӢгҖӮеӣ дёәд№ӢеүҚзҡ„еҺӢжөӢжҖ§иғҪеңЁиҝҷеҚҠе№ҙжңҹй—ҙдёҖиҲ¬дёҚдјҡеҮәзҺ°еӨӘеӨ§зҡ„жҖ§иғҪй—®йўҳгҖӮиҝҷеүҚжҸҗжҳҜеӣ дёәжҲ‘们жҜҸж¬ЎеҸ‘еёғйҮҚеӨ§зҡ„йЎ№зӣ®зҡ„ж—¶еҖҷйғҪдјҡиҝӣиЎҢжҖ§иғҪеҺӢжөӢпјҢжүҖд»ҘеҺӢжөӢж…ўж…ўеҸҳеҫ—常规еҢ–гҖҒиҮӘеҠЁеҢ–пјҢйҒ—жјҸзҡ„жҖ§иғҪй—®йўҳеә”иҜҘдёҚдјҡеӨӘеӨҡгҖӮжҖ§иғҪжҢҮж Үе…¶е®һеңЁе№іж—¶е°ұе…іжіЁдәҶпјҢиҖҢдёҚжҳҜеӨ§дҝғжүҚжқҘдёҙж—¶жҠұдҪӣи„ҡпјҢйӮЈж ·е…¶е®һдёәж—¶е·ІжҷҡпјҢеҸӘиғҪжӢҶдёңеўҷиЎҘиҘҝеўҷгҖӮ
еә”з”ЁжңҚеҠЎеҷЁй…ҚзҪ®пјҢзү©зҗҶжңәгҖҒ32core гҖҒ168gгҖҒеҚғе…ҶзҪ‘еҚЎгҖҒеҺӢжөӢзҪ‘з»ңеёҰе®ҪеҚғе…ҶгҖҒIIS 7.5гҖҒ.NET 4.0пјҢиҝҷеҸ°еҺӢжөӢжңҚеҠЎеҷЁиҝҳжҳҜеҫҲејәзҡ„гҖӮ
жҲ‘们жң¬ең°дјҡз”ЁJMeterиҝӣиЎҢй—®йўҳжҺ’жҹҘгҖӮз”ұдәҺиҝҷзҜҮж–Үз« дёҚжҳҜи®ІжҖҺд№ҲеҒҡжҖ§иғҪеҺӢжөӢзҡ„пјҢжүҖд»Ҙе…¶д»–и·ҹжң¬зҜҮж–Үз« е…ізі»зҡ„дёҚеӨ§зҡ„жғ…еҶөе°ұдёҚд»Ӣз»ҚдәҶгҖӮеҢ…жӢ¬еҺӢжөӢзҪ‘з»ңйҡ”зҰ»гҖҒеҺӢжөӢжңәеҷЁзҡ„й…ҚзҪ®е’ҢиҠӮзӮ№ж•°зӯүгҖӮ
жҲ‘们зҡ„иҰҒжұӮпјҢйЎ¶еұӮжңҚеҠЎеңЁ200并еҸ‘дёӢпјҢе№іеқҮе“Қеә”ж—¶й—ҙдёҚиғҪи¶…иҝҮ50жҜ«з§’пјҢTPSиҰҒеҲ°3000е·ҰеҸігҖӮдёҖзә§жңҚеҠЎпјҢд№ҹе°ұжҳҜжңҖеә•еұӮжңҚеҠЎзҡ„иҰҒжұӮжӣҙй«ҳпјҢе•Ҷе“Ғзі»з»ҹгҖҒдҝғй”Җзі»з»ҹгҖҒеҚЎеҲёзі»з»ҹе№іеқҮе“Қеә”ж—¶й—ҙеҹәжң¬дҝқжҢҒеңЁ20жҜ«з§’д»ҘеҶ…жүҚиғҪжҺҘеҸ—гҖӮеӣ дёәдёҖзә§жңҚеҠЎзҡ„е“Қеә”йҖҹеәҰзӣҙжҺҘеҶіе®ҡдәҶдёҠеұӮжңҚеҠЎзҡ„е“Қеә”йҖҹеәҰпјҢиҝҷйҮҢиҝҳиҰҒеҺ»жҺүдёҖдәӣе…¶д»–зҡ„и°ғз”ЁејҖй”ҖгҖӮ
2.з—ҮзҠ¶
иҝҷдёӘжҖ§иғҪй—®йўҳзҡ„з—ҮзҠ¶иҝҳжҳҜжҜ”иҫғеҘҮжҖӘзҡ„пјҢжғ…еҶөжҳҜиҝҷж ·зҡ„пјҡ200并еҸ‘гҖҒ2000loopпјҢ40wзҡ„и°ғз”ЁйҮҸгҖӮдёҖејҖе§ӢеүҚеҮ з§’йҖҹеәҰжҳҜжҜ”иҫғеҝ«зҡ„пјҢеҹәжң¬дёҠTPSеҲ°дәҶ2500е·ҰеҸігҖӮжңҚеҠЎеҷЁзҡ„CPUд№ҹеҲ°дәҶ60е·ҰеҸіпјҢиҝҳжҳҜжҜ”иҫғжӯЈеёёзҡ„пјҢдҪҶжҳҜеҮ з§’иҝҮеҗҺеӨ„зҗҶйҖҹеәҰйҷЎйҷҚпјҢTPSж…ўж…ўеңЁеҫҖдёӢжҺүгҖӮд»ҺжңҚеҠЎеҷЁзҡ„зӣ‘жҺ§дёӯеҸ‘зҺ°пјҢжңҚеҠЎеҷЁзҡ„CPUжҳҜ0%ж¶ҲиҖ—гҖӮиҝҷеҫҲеҗ“дәәпјҢжҖҺд№ҲзӘҒ然дёҚеӨ„зҗҶдәҶгҖӮTPSжҺүеҲ°100еӨҡдәҶпјҢжҳҫ然дјҡдёҖзӣҙжҺүдёӢеҺ»гҖӮзӯүдәҶеӨ§жҰӮдёҚеҲ°4еҲҶй’ҹпјҢдёҖдёӢеӯҗCPUеҸҲдёҠжқҘдәҶгҖӮTPSеҸҜд»ҘеҲ°2000е·ҰеҸігҖӮ
жҲ‘们仔з»ҶеҲҶжһҗжҹҘзңӢпјҢйҰ–е…ҲJMeterзҡ„еҗһеҗҗйҮҸзҡ„й—®йўҳпјҢеҗһеҗҗйҮҸжҳҜжҢүз…§дҪ зҡ„иҜ·жұӮе№іеқҮе“Қеә”ж—¶й—ҙи®Ўз®—зҡ„пјҢжүҖд»ҘиҝҷйҮҢзңӢиө·жқҘTPSжҳҜж…ўж…ўеңЁеҮҸж…ўе…¶е®һе·Із»Ҹеҹәжң¬еҒңжӯўдәҶгҖӮеҰӮжһңдҪ зҡ„е№іеқҮе“Қеә”ж—¶й—ҙдёә20жҜ«з§’пјҢйӮЈд№ҲеңЁеҚ•дҪҚж—¶й—ҙеҶ…дҪ зҡ„еҗһеҗҗйҮҸжҳҜеҹәжң¬еҸҜд»Ҙи®Ўз®—еҮәжқҘзҡ„гҖӮ
з—ҮзҠ¶дё»иҰҒе°ұжҳҜиҝҷж ·зҡ„пјҢжҲ‘们жҺҘдёӢжқҘеҜ№е®ғиҝӣиЎҢиҜҠж–ӯгҖӮ
3.иҜҠж–ӯ
ејҖе§ӢйҖҡиҝҮиө°жҹҘд»Јз ҒпјҢзңӢиғҪдёҚиғҪеҸ‘зҺ°зӮ№д»Җд№ҲгҖӮ
иҝҷжҳҜж”Ҝд»ҳеӣһи°ғжңҚеҠЎпјҢд»Јз Ғзҡ„еүҚеҗҺжІЎжңүеӨӘеӨҡзҡ„дёҡеҠЎеӨ„зҗҶпјҢйүҙжқғжЈҖжҹҘгҖҒи®ўеҚ•ж”Ҝд»ҳзҠ¶жҖҒдҝ®ж”№гҖҒи§ҰеҸ‘ж”Ҝд»ҳе®ҢжҲҗдәӢ件гҖҒи°ғз”Ёй…ҚйҖҒгҖҒе‘Ёиҫ№дёҡеҠЎйҖҡзҹҘпјҲиҝҷйҮҢжңүдёҖйғЁеҲҶйңҖиҰҒе…је®№иҖҒд»Јз ҒгҖҒиҖҒжҺҘеҸЈпјүгҖӮжҲ‘们йҰ–е…Ҳдё»иҰҒжҳҜжҹҘзңӢеҜ№еӨ–дҫқиө–зҡ„йғЁеҲҶпјҢеҸ‘зҺ°жңүredisиҜ»еҶҷзҡ„д»Јз ҒпјҢе°ұе°Ҷredisзҡ„йғЁеҲҶд»Јз ҒжіЁйҮҠжҺүеңЁиҝӣиЎҢеҺӢжөӢиҜ•иҜ•зңӢгҖӮз»“жһңдёҖдёӢеӯҗе°ұжӯЈеёёдәҶпјҢиҝҷе°ұжҜ”иҫғеҘҮжҖӘдәҶпјҢredisжҳҜжҲ‘们其他еҺӢжөӢжңҚеҠЎе…ұз”Ёзҡ„пјҢд№ӢеүҚеҺӢжөӢжҖҺд№ҲжІЎжңүй—®йўҳгҖӮжІЎз®ЎйӮЈд№ҲеӨҡдәҶпјҢеҸҜиғҪжҳҜд»Јз Ғзҡ„жү§иЎҢеәҸеҲ—дёҚеҗҢпјҢеңЁе№¶еҸ‘йўҶеҹҹйҮҢйқўпјҢиҝҷд№ҹиҜҙеҫ—йҖҡгҖӮ
жҲ‘们еҶҚйҖҡиҝҮжү“еҚ°redisжү§иЎҢзҡ„ж—¶й—ҙпјҢзңӢеӨ„зҗҶйңҖиҰҒеӨҡд№…гҖӮз»“жһңжҳҫзӨәпјҢеӨ„зҗҶйҖҹеәҰдёҚеқҮеҢҖпјҢеүҚйқўзҡ„еҫҲеҝ«пјҢеҗҺйқўзҡ„ж—¶й—ҙйғҪеңЁ5-6з§’пјҢиҷҪ然дёҚеқҮеҢҖдҪҶжҳҜеҫҲжңү规еҫӢгҖӮ
жүҖд»ҘжҲ‘们йғҪи®ӨдёәжҳҜredisзҡ„зӣёе…ій—®йўҳпјҢе°ұејҖе§ӢдёҖеӨҙжүҺиҝӣеҺ»жЈҖжҹҘredisзҡ„й—®йўҳдәҶгҖӮејҖе§ӢеҜ№redisиҝӣиЎҢжЈҖжҹҘпјҢйҰ–е…ҲжҳҜејҖеҗҜWireshark TCPиҝһжҺҘзӣ‘жҺ§пјҢжЈҖжҹҘй“ҫи·ҜгҖҒredisжңҚеҠЎеҷЁзҡ„SlowlogжҹҘзңӢеӨ„зҗҶж—¶й—ҙгҖӮredisе®ўжҲ·з«Ҝеә“зҡ„жәҗд»Јз ҒжҹҘзңӢпјҲredisе®ўжҲ·з«ҜжҺ’йҷӨеҺҹз”ҹзҡ„StackExhange.Redisзҡ„жңүдёӨеұӮе°ҒиЈ…пјҢдёҖе…ұдёүеұӮпјүпјҢйҮҚзӮ№е…іжіЁжңүй”Ғзҡ„ең°ж–№е’Ңthread waitзҡ„ең°ж–№гҖӮеҗҢж—¶жҺ’жҹҘзҪ‘з»ңй—®йўҳпјҢеҶҚиҝӣиЎҢеҺӢжөӢзҡ„ж—¶еҖҷping redisжңҚеҠЎеҷЁзңӢжҳҜеҗҰжңү延иҝҹгҖӮпјҲжӯӨж—¶жҳҜжҷҡдёҠ21зӮ№е·ҰеҸіпјҢиҝҷдёӘж—¶еҖҷзҡ„еӨ§и„‘жғ…еҶөеӨ§е®¶йғҪжҮӮзҡ„гҖӮпјү
е°ұжҳҜиҝҷж ·ең°жҜҜејҸзҡ„жҗңжҹҘпјҢд»ҘдёәжҳҜиӮҜе®ҡиғҪе®ҡдҪҚеҲ°й—®йўҳгҖӮдҪҶжҳҜжҲ‘们еҚҙеҝҪи§ҶдәҶд»Јз Ғзҡ„еұӮж¬Ўз»“жһ„пјҢдёҖдёӢеӯҗдё“еҲ°дәҶеӨӘз»ҶиҠӮзҡ„ең°ж–№пјҢеҝҪи§ҶдәҶж•ҙдҪ“зҡ„жһ¶жһ„пјҲжҢҮејҖеҸ‘жһ¶жһ„пјҢеӣ дёәд»Јз ҒдёҚжҳҜжҲ‘们еҶҷзҡ„пјҢеҜ№д»Јз Ғе‘Ёиҫ№жғ…еҶөдёҚжҳҜеӨӘдәҶи§ЈпјүгҖӮ
е…ҲзңӢredisжңҚеҠЎеҷЁзҡ„е»әз«Ӣжғ…еҶөпјҢtcpжҠ“еҢ…жҹҘзңӢпјҢиҝһжҺҘе»әз«ӢжӯЈеёёпјҢжІЎжңүдёўеҢ…пјҢйҖҹеәҰд№ҹеҫҲеҝ«гҖӮredisзҡ„еӨ„зҗҶйҖҹеәҰд№ҹжІЎй—®йўҳпјҢslowlogжҹҘзңӢеҹәжң¬get keyд№ҹе°ұ1жҜ«з§’дёҚеҲ°гҖӮпјҲиҝҷйҮҢйңҖиҰҒжіЁж„ҸпјҢredisзҡ„еӨ„зҗҶж—¶й—ҙиҝҳеҢ…жӢ¬йҳҹеҲ—йҮҢзӯүеҫ…зҡ„ж—¶й—ҙгҖӮslowlogеҸӘиғҪзңӢеҲ°redisеӨ„зҗҶзҡ„ж—¶й—ҙпјҢзңӢдёҚеҲ°blockingзҡ„ж—¶й—ҙпјҢиҝҷйҮҢйқўиҝҳеҢ…жӢ¬redisзҡ„commandеңЁе®ўжҲ·з«ҜйҳҹеҲ—зҡ„ж—¶й—ҙгҖӮпјү
жүҖд»Ҙжү“еҚ°еҮәжқҘзҡ„redisеӨ„зҗҶж—¶й—ҙеҫҲж…ўпјҢдёҚзәҜзІ№жҳҜredisжңҚеҠЎеҷЁзҡ„еӨ„зҗҶж—¶й—ҙпјҢдёӯй—ҙжңүеҮ дёӘзҺҜиҠӮйңҖиҰҒжҺ’жҹҘзҡ„гҖӮ
з»ҸиҝҮдёҖз•ӘжҠҳи…ҫпјҢжҺ’жҹҘпјҢй—®йўҳжІЎе®ҡдҪҚеҲ°пјҢе·ІжҳҜж·ұеӨңпјҢзІҫеҠӣдёҘйҮҚдёҚи¶ідәҶпјҢд№ҹиҰҒеҲ°ең°й“ҒжңҖеҗҺдёҖзҸӯиҪҰеҸ‘иҪҰж—¶й—ҙдәҶпјҢеҶҚдёҚиө°иө¶дёҚдёҠдәҶпјҢдёӢзҸӯеӣһ家пјҢдёҠеҲ°жңҖеҗҺдёҖзҸӯең°й“ҒжІЎиҖҪиҜҜдёүеҲҶй’ҹ~~гҖӮ
йҮҚж•ҙжҖқи·ҜпјҢ第дәҢеӨ©з»§з»ӯжҺ’жҹҘгҖӮ
жҲ‘们е®ҡдҪҚеҲ°redisе®ўжҲ·з«Ҝзҡ„иҝһжҺҘжҳҜеҸҜд»Ҙе…Ҳйў„зғӯзҡ„пјҢеңЁglobal application_beginеҗҜеҠЁзҡ„ж—¶еҖҷе…Ҳйў„зғӯеҘҪпјҢ然еҗҺжҖ§иғҪдёҖдёӢеӯҗд№ҹжӯЈеёёдәҶгҖӮ
иҢғеӣҙиҝӣдёҖжӯҘзј©е°ҸпјҢй—®йўҳеҮәеңЁиҝһжҺҘдёҠпјҢиҝҷйҮҢжҲ‘们еҸҲеҸҚжҖқдәҶпјҲдёҖеӨңи§үзқЎиҝҮдәҶпјҢи„‘еӯҗжё…йҶ’дәҶпјүпјҢйӮЈдёәд»Җд№ҲжҲ‘们д№ӢеүҚзҡ„еҺӢжөӢжІЎеҮәзҺ°иҝҮиҝҷдёӘй—®йўҳгҖӮеҜ№жҠҖжңҜзӢӮзғӯзҲұеҘҪзҡ„жҲ‘们пјҢе“ӘиғҪе–„зҪўз”ҳдј‘гҖӮжӯӨж—¶й—®йўҳз®—жҳҜи§ЈеҶідәҶпјҢдҪҶжҳҜиғҢеҗҺжүҖж¶үеҸҠеҲ°зҡ„зӣёе…ізәҝзҙўз©ҝдёҚиө·жқҘпјҢжҖ»жҳҜдёҚеӨӘиҲ’жңҚгҖӮпјҲдёӯеңәдј‘жҒҜзүҮеҲ»пјҢе·ІжҳҜ第дәҢеӨ©зҡ„дёӢеҚҲеҝ«еӮҚжҷҡдәҶ~~гҖӮпјүжҠҖжңҜдәәе‘ҳиҰҒжңүиҝҷз§ҚеҫҒжңҚж¬ІпјҢеҝ…йЎ»жҗһжё…жҘҡгҖӮ
жҲ‘们ејҖе§ӢиҝҳеҺҹзҺ°еңәпјҢ然еҗҺејҖе§ӢеҮәеӨ§жӢӣпјҢејҖе§ӢdumpиҝӣзЁӢж–Ү件пјҢеҲҶдёҚеҗҢзҡ„ж—¶й—ҙж®өпјҢжҠ“еҸ–дәҶеҮ д»Ҫdumpж–Ү件downеҲ°жң¬ең°иҝӣиЎҢеҲҶжһҗгҖӮ
йҰ–е…ҲжҹҘзңӢдәҶзәҝзЁӢжғ…еҶөпјҢ!runawayпјҢеҸ‘зҺ°еӨ§еӨҡж•°зәҝзЁӢжү§иЎҢж—¶й—ҙйғҪжңүзӮ№й•ҝгҖӮжҺҘзқҖеҲҮжҚўеҲ°жҹҗдёӘзәҝзЁӢдёӯ~xxsпјҢжҹҘзңӢзәҝзЁӢи°ғз”Ёе Ҷж ҲгҖӮеҸ‘зҺ°еңЁзӯүдёҖжҠҠmonitorй”ҒгҖӮеҗҢж—¶еҲҮжҚўеҲ°е…¶д»–еҮ дёӘзәҝзЁӢдёӯжҹҘзңӢдёӢжҳҜдёҚжҳҜйғҪеңЁзӯүеҫ…иҝҷжҠҠй”ҒгҖӮз»“жһңзЎ®е®һйғҪеңЁзӯүиҝҷжҠҠй”ҒгҖӮ
з»“и®әпјҢеҸ‘зҺ°дёҖеҚҠзҡ„зәҝзЁӢйғҪеңЁзӯүеҫ…moniterзӣ‘и§ҶеҷЁй”ҒпјҢйҡҸзқҖж—¶й—ҙеўһеҠ пјҢжҳҜдёҚжҳҜйғҪеңЁзӯүеҫ…иҝҷжҠҠй”ҒгҖӮиҝҷжҜ”иҫғеҘҮжҖӘгҖӮ
иҝҷжҠҠй”ҒжҳҜredisеә“зҡ„第дёүеұӮе°ҒиЈ…зҡ„ж—¶еҖҷз”ЁжқҘlockиҺ·еҸ–redis connectioinж—¶еҖҷз”Ёзҡ„гҖӮжҲ‘们зӣҙжҺҘжіЁйҮҠжҺүиҝҷжҠҠй”ҒпјҢ继з»ӯеҺӢжөӢ继з»ӯdumpпјҢ然еҗҺеҸҲеҸ‘зҺ°дёҖжҠҠmonitorпјҢиҝҷжҠҠй”ҒжҳҜStackExchange.Redisдёӯзҡ„пјҢд»Јз ҒдёҖж—¶еҚҠдјҡж— жі•ж¶ҲеҢ–пјҢеҸӘжҹҘдәҶдё»дҪ“д»Јз Ғе’Ңе‘Ёиҫ№д»Јз Ғжғ…еҶөпјҢжІЎжңүж—¶й—ҙжҹҘзңӢе…ЁеұҖжғ…еҶөгҖӮпјҲеӣ дёәж—¶й—ҙзҙ§иҝ«пјүгҖӮжҡӮдё”е®Ңе…ЁдҝЎд»»з¬¬дёүж–№еә“пјҢ然еҗҺжҹҘзңӢredis connection string зҡ„еҗ„дёӘеҸӮж•°пјҢжҳҜдёҚжҳҜеҸҜд»Ҙи°ғж•ҙи¶…ж—¶ж—¶й—ҙгҖҒиҝһжҺҘжұ еӨ§е°ҸзӯүгҖӮдҪҶжҳҜиҝҳжҳҜжңӘиғҪи§ЈеҶігҖӮ
еӣһиҝҮеӨҙ继з»ӯжҹҘзңӢdumpпјҢжҹҘзңӢдәҶдёӢCLRиҝһжҺҘжұ пјҢпјҒThreadPoolпјҢдёҖдёӢеӯҗзңӢеҲ°й—®йўҳдәҶгҖӮ
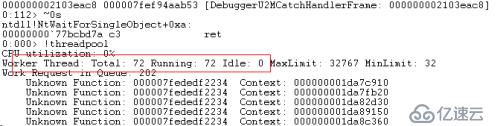
继з»ӯжҹҘзңӢе…¶д»–еҮ дёӘdumpж–Ү件пјҢIdleйғҪжҳҜ0пјҢд№ҹе°ұжҳҜиҜҙCLRзәҝзЁӢжұ жІЎжңүзәҝзЁӢжқҘеӨ„зҗҶиҜ·жұӮдәҶпјҢиҮіе°‘CLRзәҝзЁӢжұ зҡ„еҲӣе»әйҖҹзҺҮе’Ң并еҸ‘йҖҹзҺҮдёҚеҢ№й…ҚдәҶгҖӮ
CLRзәҝзЁӢжұ зҡ„еҲӣе»әйҖҹзҺҮдёҖиҲ¬жҳҜ1з§’2дёӘзәҝзЁӢпјҢзәҝзЁӢжұ зҡ„еҲӣе»әйҖҹзҺҮжҳҜеҗҰеӯҳеңЁж»‘еҠЁж—¶й—ҙдёҚеӨӘжё…жҘҡгҖӮзәҝзЁӢжұ зҡ„еӨ§е°ҸеҸҜд»ҘйҖҡиҝҮ C:\Windows\Microsoft.NET\Framework64\v4.0.30319\Config\machine.config й…ҚзҪ®жқҘи®ҫзҪ®пјҢй»ҳи®ӨжҳҜиҮӘеҠЁй…ҚзҪ®зҡ„гҖӮжңҖе°Ҹзҡ„зәҝзЁӢж•°дёҖиҲ¬жҳҜеҪ“еүҚжңәеҷЁзҡ„CPU ж ёж•°гҖӮеҪ“然дҪ д№ҹеҸҜд»ҘйҖҡиҝҮThreadPoolзӣёе…іж–№жі•жқҘи®ҫзҪ®пјҢThreadPool.SetMaxThreads(), ThreadPool.SetMinThreads()гҖӮ
然еҗҺжҲ‘们继з»ӯжҺ’жҹҘд»Јз ҒпјҢеҸ‘зҺ°д»Јз Ғдёӯжңүз”ЁActionзҡ„委жүҳзҡ„ең°ж–№пјҢиҖҢиҝҷдёӘActionжҳҜеӨ„зҗҶејӮжӯҘд»Јз Ғзҡ„пјҢдёҠйқўиҜҙзҡ„redisзҡ„иҜ»еҶҷйғҪеңЁиҝҷдёӘActionйҮҢйқўзҡ„гҖӮдёҖдёӢжҲ‘们жҳҺзҷҪдәҶпјҢжүҖжңүзҡ„зәҝзҙўйғҪиҝһиө·жқҘдәҶгҖӮ
4.з»“и®ә
.NET CLRзәҝзЁӢжұ жҳҜе…ұдә«зәҝзЁӢжұ пјҢд№ҹе°ұжҳҜиҜҙASP.NETгҖҒ委жүҳгҖҒTaskиғҢеҗҺйғҪжҳҜдёҖдёӘзәҝзЁӢжұ еңЁеӨ„зҗҶгҖӮзәҝзЁӢжұ еҲҶдёәдёӨз§ҚпјҢRequestзәҝзЁӢжұ гҖҒIOCPзәҝзЁӢжұ пјҲе®ҢжҲҗз«ҜеҸЈзәҝзЁӢжұ пјүгҖӮ
жҲ‘们зҺ°еңЁзҗҶдёӢзәҝзҙўпјҡ
1.д»ҺжңҖејҖе§Ӣзҡ„JMeterеҺӢжөӢеҗһеҗҗйҮҸж…ўж…ўеҸҳдҪҺжҳҜдёӘеҒҮиұЎпјҢиҖҢжӯӨж—¶еӨ„зҗҶе·Із»Ҹе…ЁйқўеҒңжӯўпјҢжңҚеҠЎеҷЁзҡ„CPUеӨ„зҗҶдёә0%гҖӮиӮүзңјзңӢиө·жқҘеҸҳж…ўжҳҜеӣ дёәиҜ·жұӮ延иҝҹж—¶й—ҙеўһеҠ дәҶгҖӮ
2.redisзҡ„TCPй“ҫи·ҜжІЎй—®йўҳпјҢWiresharkжҹҘзңӢжІЎжңүд»»дҪ•ејӮеёёгҖҒSlowlogжІЎжңүй—®йўҳгҖҒredisзҡ„key comnandж…ўжҳҜеӣ дёәblockingдҪҸдәҶгҖӮ
3.е…¶д»–жңҚеҠЎеҺӢжөӢд№ӢжүҖжңүжІЎй—®йўҳжҳҜеӣ дёәжҲ‘们жҳҜеҗҢжӯҘи°ғз”ЁredisпјҢеҪ“йҰ–ж¬ЎTCPиҝһжҺҘе»әз«Ӣд№ӢеҗҺйҖҹеәҰдјҡдёҠжқҘгҖӮ
4.ActionзңӢиө·жқҘйҖҹеәҰжҳҜдёҠеҺ»дәҶпјҢдҪҶжҳҜжүҖжңүзҡ„ActionйғҪжҳҜCLRзәҝзЁӢжұ дёӯзҡ„зәҝзЁӢпјҢзңӢиө·жқҘеҝ«жҳҜеӣ дёәиҝҳжІЎжңүеҲ°CLRзәҝзЁӢжұ зҡ„瓶йўҲгҖӮ
Action asyncAction = () =>
{
//иҜ»еҶҷredis
//еҸ‘йҖҒйӮ®д»¶
//...
};
asyncAction();5.JMeterеҺӢжөӢзҡ„ж—¶еҖҷжІЎжңү延иҝҹпјҢеңЁеҺӢжөӢзҡ„ж—¶еҖҷзЁӢеәҸжІЎжңүйў„зғӯпјҢеҜјиҮҙжүҖжңүзҡ„дёңиҘҝйңҖиҰҒеҲқе§ӢеҢ–пјҢIISгҖҒ.NETзӯүгҖӮиҝҷдәӣйғҪдјҡ让第дёҖж¬ЎзңӢиө·жқҘеҫҲеҝ«пјҢ然еҗҺж…ўж…ўдёӢйҷҚзҡ„й”ҷи§үгҖӮ
жҖ»з»“пјҡйҰ–ж¬Ўе»әз«ӢTCPиҝһжҺҘжҳҜйңҖиҰҒж—¶й—ҙзҡ„пјҢжӯӨ时并еҸ‘иҝҮеӨ§пјҢжүҖжңүзҡ„зәҝзЁӢеңЁwaitпјҢwaitд№ӢеҗҺCPUдјҡе°ҶиҝҷдәӣзәҝзЁӢдәӨжҚўеҮәеҺ»пјҢжӯӨж—¶жҳҜжҳҺжҳҫзҡ„жүҖзәҝзЁӢдёҠдёӢж–ҮеҲҮжҚўиҝҮзЁӢпјҢжҳҜдёҖйғЁеҲҶејҖй”ҖгҖӮеҪ“CLRзәҝзЁӢжұ зҡ„зәҝзЁӢе…ЁйғЁиҖ—е…үеҗһеҗҗйҮҸејҖе§ӢйҷЎйҷҚгҖӮжҜҸж¬Ўи°ғз”Ёе…¶е®һжҳҜејҖеҗҜеҠӣдәҶдёӨдёӘзәҝзЁӢпјҢдёҖдёӘеӨ„зҗҶиҜ·жұӮзҡ„RequestпјҢиҝҳжңүдёҖдёӘжҳҜAction委жүҳзәҝзЁӢгҖӮеҪ“дҪ д»ҘдёәзәҝзЁӢиҝҳеӨҹзҡ„ж—¶еҖҷпјҢе…¶е®һзәҝзЁӢжұ е·Із»Ҹж»ЎдәҶгҖӮ
5.и§ЈеҶі
й’ҲеҜ№иҝҷдёӘй—®йўҳжҲ‘们иҝӣиЎҢдәҶйҳҹеҲ—еҢ–еӨ„зҗҶгҖӮзӣёеҪ“дәҺеңЁCLRзәҝзЁӢжұ еҹәзЎҖдёҠжҠҪиұЎдёҖдёӘе·ҘдҪңйҳҹеҲ—еҮәжқҘпјҢ然еҗҺйҳҹеҲ—зҡ„ж¶Ҳиҙ№зәҝзЁӢжҺ§еҲ¶еңЁдёҖе®ҡж•°йҮҸд№ӢеҶ…пјҢеҲқе§ӢеҢ–зҡ„ж—¶еҖҷй»ҳи®ӨдёҖдёӘзәҝзЁӢпјҢдјҡжҸҗдҫӣжҺҘеҸЈеҲӣе»әйЎ¶еӨҡ6дёӘзәҝзЁӢгҖӮиҝҷж ·еҪ“йҳҹеҲ—зҡ„еӨ„зҗҶйҖҹеәҰи·ҹдёҚдёҠзҡ„ж—¶еҖҷеҸҜд»Ҙи°ғз”ЁгҖӮеӨ§иҮҙд»Јз ҒеҰӮдёӢпјҲе·ІиҝӣиЎҢйҖӮеҪ“зҡ„дҝ®ж”№пјҢйқһжәҗз ҒжЁЎж ·пјҢд»…дҫӣеҸӮиҖғпјүпјҡ
Service йғЁеҲҶпјҡ
private static readonly ConcurrentQueue<NoticeParamEntity> AsyncNotifyPayQueue = new ConcurrentQueue<NoticeParamEntity>();
private static int _workThread;
static ChangeOrderService()
{
StartWorkThread();
}
public static int GetPayNoticQueueCount()
{
return AsyncNotifyPayQueue.Count;
}
public static int StartWorkThread()
{
if (_workThread > 5) return _workThread;
ThreadPool.QueueUserWorkItem(WaitCallbackImpl);
_workThread += 1;
return _workThread;;
}
public static void WaitCallbackImpl(object state)
{
while (true)
{
try
{
PayNoticeParamEntity payParam;
AsyncNotifyPayQueue.TryDequeue(out payParam);
if (payParam == null)
{
Thread.Sleep(5000);
continue;
}
//иҺ·еҸ–и®ўеҚ•иҜҰжғ…
//з»“иҪ¬еҲҶж‘Ҡ
//еҸ‘зҹӯдҝЎ
//еҸ‘йҖҒж¶ҲжҒҜ
//й…ҚйҖҒ
}
catch (Exception exception)
{
//log
}
}
}еҺҹжқҘи°ғз”Ёзҡ„ең°ж–№зӣҙжҺҘж”№жҲҗе…ҘйҳҹеҲ—пјҡ
private void AsyncNotifyPayCompleted(NoticeParamEntity payNoticeParam)
{
AsyncNotifyPayQueue.Enqueue(payNoticeParam);
}Controller д»Јз Ғпјҡ
public class WorkQueueController : ApiController
{
[Route("worker/server_work_queue")]
[HttpGet]
public HttpResponseMessage GetServerWorkQueue()
{
var payNoticCount = ChangeOrderService.GetPayNoticQueueCount();
var result = new HttpResponseMessage()
{
Content = new StringContent(payNoticCount.ToString(), Encoding.UTF8, "application/json")
};
return result;
}
[Route("worker/start-work-thread")]
[HttpGet]
public HttpResponseMessage StartWorkThread()
{
var count = ChangeOrderService.StartWorkThread();
var result = new HttpResponseMessage()
{
Content = new StringContent(count.ToString(), Encoding.UTF8, "application/json")
};
return result;
}
}дёҠиҝ°д»Јз ҒжҳҜжңӘз»ҸиҝҮжҠҪиұЎе°ҒиЈ…зҡ„пјҢд»…дҫӣеҸӮиҖғгҖӮжҖқи·ҜжҳҜдёҚеҸҳзҡ„пјҢе°ҶзәҝзЁӢеҲ©з”ЁзҺҮжңҖеӨ§еҢ–пјҢ延иҝҹд»»еҠЎж— йңҖеҚ з”ЁиҝҮеӨҡзәҝзЁӢпјҢе°ҶCPUеҜҶйӣҶеһӢе’ҢIOеҜҶйӣҶеһӢеҲҶејҖгҖӮи®©йҖҹеәҰдёҚеҢ№й…Қзҡ„еҠЁдҪңеҲҶејҖгҖӮ
дјҳеҢ–еҗҺзҡ„TPSеҸҜд»ҘеҲ°7000пјҢжҜ”еҺҹжқҘеҝ«иҝ‘дёүеҖҚгҖӮ
6.еҜ№жҜ”JAVAе®һзҺ°
иҝҷдёӘй—®йўҳе…¶е®һеҰӮжһңеңЁJAVAйҮҢд№ҹи®ёдёҚеӨӘе®№жҳ“еҮәзҺ°пјҢJAVAзҡ„зәҝзЁӢжұ еҠҹиғҪжҳҜжҜ”иҫғејәеӨ§зҡ„пјҢ并еҸ‘еә“жҜ”иҫғдё°еҜҢгҖӮеңЁJAVAйҮҢдёӨиЎҢд»Јз Ғе°ұеҸҜд»Ҙжҗһе®ҡдәҶгҖӮ
ExecutorService fiexdExecutorService = Executors.newFixedThreadPool(Thread_count);
зӣҙжҺҘжһ„йҖ дёҖдёӘжҢҮе®ҡж•°йҮҸзҡ„зәҝзЁӢжұ пјҢеҪ“然жҲ‘们д№ҹеҸҜд»Ҙи®ҫзҪ®зәҝзЁӢжұ зҡ„йҳҹеҲ—зұ»еһӢгҖҒеӨ§е°ҸгҖҒеҢ…жӢ¬йҳҹеҲ—ж»ЎдәҶд№ӢеҗҺгҖҒзәҝзЁӢжұ ж»ЎдәҶд№ӢеҗҺзҡ„жӢ’з»қзӯ–з•ҘгҖӮиҝҷдәӣз”Ёиө·жқҘиҝҳжҳҜжҜ”иҫғж–№дҫҝзҡ„гҖӮ





