дҪҝз”Ёhbaseзҡ„дјҳзӮ№жңүе“Әдәӣ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚдҪҝз”Ёhbaseзҡ„дјҳзӮ№жңүе“ӘдәӣпјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ
hbaseжҳҜиҝҗиЎҢеңЁHadoopдёҠзҡ„NoSQLж•°жҚ®еә“пјҢе®ғжҳҜдёҖдёӘеҲҶеёғејҸзҡ„е’ҢеҸҜжү©еұ•зҡ„еӨ§ж•°жҚ®д»“еә“пјҢд№ҹе°ұжҳҜиҜҙHBaseиғҪеӨҹеҲ©з”ЁHDFSзҡ„еҲҶеёғејҸеӨ„зҗҶжЁЎејҸпјҢ并д»ҺHadoopзҡ„MapReduceзЁӢеәҸжЁЎеһӢдёӯиҺ·зӣҠгҖӮиҝҷж„Ҹе‘ізқҖеңЁдёҖз»„е•Ҷдёҡ硬件дёҠеӯҳеӮЁи®ёеӨҡе…·жңүж•°еҚҒдәҝиЎҢе’ҢдёҠзҷҫдёҮеҲ—зҡ„еӨ§иЎЁгҖӮйҷӨеҺ»Hadoopзҡ„дјҳеҠҝпјҢHBaseжң¬иә«е°ұжҳҜеҚҒеҲҶејәеӨ§зҡ„ж•°жҚ®еә“пјҢе®ғиғҪеӨҹиһҚеҗҲkey/valueеӯҳеӮЁжЁЎејҸеёҰжқҘе®һж—¶жҹҘиҜўзҡ„иғҪеҠӣпјҢд»ҘеҸҠйҖҡиҝҮMapReduceиҝӣиЎҢзҰ»зәҝеӨ„зҗҶжҲ–иҖ…жү№еӨ„зҗҶзҡ„иғҪеҠӣгҖӮжҖ»зҡ„жқҘиҜҙпјҢHbaseиғҪеӨҹи®©дҪ еңЁеӨ§йҮҸзҡ„ж•°жҚ®дёӯжҹҘиҜўи®°еҪ•пјҢд№ҹеҸҜд»Ҙд»ҺдёӯиҺ·еҫ—з»јеҗҲеҲҶжһҗжҠҘе‘ҠгҖӮ
и°·жӯҢжӣҫз»ҸйқўеҜ№иҝҮдёҖдёӘжҢ‘жҲҳзҡ„й—®йўҳпјҡеҰӮдҪ•иғҪеңЁж•ҙдёӘдә’иҒ”зҪ‘дёҠжҸҗдҫӣе®һж—¶зҡ„жҗңзҙўз»“жһңпјҹзӯ”жЎҲжҳҜе®ғжң¬иҙЁдёҠйңҖиҰҒе°Ҷдә’иҒ”зҪ‘зј“еӯҳпјҢ并йҮҚж–°е®ҡд№үеңЁиҝҷж ·еәһеӨ§зҡ„зј“еӯҳдёҠеҝ«йҖҹжҹҘжүҫзҡ„ж–°ж–№жі•гҖӮдёәдәҶиҫҫеҲ°иҝҷдёӘзӣ®зҡ„пјҢе®ҡд№үеҰӮдёӢжҠҖжңҜпјҡ
В·и°·жӯҢж–Ү件系з»ҹGFSпјҡеҸҜжү©еұ•еҲҶеёғејҸж–Ү件系з»ҹпјҢз”ЁдәҺеӨ§еһӢзҡ„гҖҒеҲҶеёғејҸзҡ„гҖҒж•°жҚ®еҜҶйӣҶеһӢзҡ„еә”з”ЁзЁӢеәҸгҖӮ
В·BigTableпјҡеҲҶеёғејҸеӯҳеӮЁзі»з»ҹпјҢз”ЁдәҺз®ЎзҗҶиў«и®ҫи®ЎжҲҗ规模еҫҲеӨ§зҡ„з»“жһ„еҢ–ж•°жҚ®пјҡжқҘиҮӘж•°д»ҘеҚғи®Ўе•Ҷз”ЁжңҚеҠЎеҷЁзҡ„PBзә§еҲ«зҡ„ж•°жҚ®гҖӮ
В·MapReduceпјҡдёҖдёӘзЁӢеәҸжЁЎеһӢпјҢз”ЁдәҺеӨ„зҗҶе’Ңз”ҹжҲҗеӨ§ж•°жҚ®йӣҶзҡ„зӣёе…іе®һзҺ°гҖӮ
еңЁи°·жӯҢеҸ‘еёғиҝҷдәӣжҠҖжңҜзҡ„ж–ҮжЎЈд№ӢеҗҺ,дёҚд№…д»ҘеҗҺжҲ‘们е°ұзңӢеҲ°дәҶе®ғ们зҡ„ејҖжәҗе®һзҺ°зүҲжң¬пјҢе°ұеңЁ2007е№ҙпјҢMikeCafarellaеҸ‘еёғдәҶBigTableејҖжәҗе®һзҺ°зҡ„д»Јз ҒпјҢд»–з§°е…¶дёәHBaseпјҢиҮӘжӯӨпјҢHBaseжҲҗдёәApacheзҡ„йЎ¶зә§йЎ№зӣ®пјҢ并иҝҗиЎҢеңЁFacebookпјҢTwitterпјҢAdobeвҖҰвҖҰд»…дёҫеҮ дёӘдҫӢеӯҗгҖӮ
HBaseдёҚжҳҜдёҖдёӘе…ізі»еһӢж•°жҚ®еә“пјҢе®ғйңҖиҰҒдёҚеҗҢзҡ„ж–№жі•е®ҡд№үдҪ зҡ„ж•°жҚ®жЁЎеһӢпјҢHBaseе®һйҷ…дёҠе®ҡд№үдәҶдёҖдёӘеӣӣз»ҙж•°жҚ®жЁЎеһӢпјҢдёӢйқўе°ұжҳҜжҜҸдёҖз»ҙеәҰзҡ„е®ҡд№үпјҡ
В·иЎҢй”®пјҡжҜҸиЎҢйғҪжңүе”ҜдёҖзҡ„иЎҢй”®пјҢиЎҢй”®жІЎжңүж•°жҚ®зұ»еһӢпјҢе®ғеҶ…йғЁиў«и®ӨдёәжҳҜдёҖдёӘеӯ—иҠӮж•°з»„гҖӮ
В·еҲ—з°Үпјҡж•°жҚ®еңЁиЎҢдёӯиў«з»„з»ҮжҲҗеҲ—з°ҮпјҢжҜҸиЎҢжңүзӣёеҗҢзҡ„еҲ—з°ҮпјҢдҪҶжҳҜеңЁиЎҢд№Ӣй—ҙпјҢзӣёеҗҢзҡ„еҲ—з°ҮдёҚйңҖиҰҒжңүзӣёеҗҢзҡ„еҲ—дҝ®йҘ°з¬ҰгҖӮеңЁеј•ж“ҺдёӯпјҢHBaseе°ҶеҲ—з°ҮеӯҳеӮЁеңЁе®ғиҮӘе·ұзҡ„ж•°жҚ®ж–Ү件дёӯпјҢжүҖд»ҘпјҢе®ғ们йңҖиҰҒдәӢе…Ҳиў«е®ҡд№үпјҢжӯӨеӨ–пјҢж”№еҸҳеҲ—з°Ү并дёҚе®№жҳ“гҖӮ
В·еҲ—дҝ®йҘ°з¬ҰпјҡеҲ—з°Үе®ҡд№үзңҹе®һзҡ„еҲ—пјҢиў«з§°д№ӢдёәеҲ—дҝ®йҘ°з¬ҰпјҢдҪ еҸҜд»Ҙи®ӨдёәеҲ—дҝ®йҘ°з¬Ұе°ұжҳҜеҲ—жң¬иә«гҖӮ
В·зүҲжң¬пјҡжҜҸеҲ—йғҪеҸҜд»ҘжңүдёҖдёӘеҸҜй…ҚзҪ®зҡ„зүҲжң¬ж•°йҮҸпјҢдҪ еҸҜд»ҘйҖҡиҝҮеҲ—дҝ®йҘ°з¬Ұзҡ„еҲ¶е®ҡзүҲжң¬иҺ·еҸ–ж•°жҚ®гҖӮ
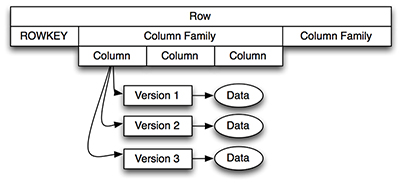
Figure1.HBaseFour-Dimensional Data Model
еҰӮеӣҫ1дёӯжүҖзӨәпјҢйҖҡиҝҮиЎҢй”®иҺ·еҸ–дёҖдёӘжҢҮе®ҡзҡ„иЎҢпјҢе®ғз”ұдёҖдёӘжҲ–еӨҡдёӘеҲ—з°Үжһ„жҲҗпјҢжҜҸдёӘеҲ—з°ҮжңүдёҖдёӘжҲ–еӨҡдёӘеҲ—дҝ®йҘ°з¬ҰпјҲеӣҫ1дёӯз§°дёәеҲ—пјүпјҢжҜҸеҲ—еҸҲеҸҜд»ҘжңүдёҖдёӘжҲ–еӨҡдёӘзүҲжң¬гҖӮдёәдәҶиҺ·еҸ–жҢҮе®ҡж•°жҚ®пјҢдҪ йңҖиҰҒзҹҘйҒ“е®ғзҡ„иЎҢй”®гҖҒеҲ—з°ҮгҖҒеҲ—дҝ®йҘ°з¬Ұд»ҘеҸҠзүҲжң¬гҖӮеҪ“и®ҫи®ЎHBaseж•°жҚ®жЁЎеһӢж—¶пјҢеҜ№иҖғиҷ‘ж•°жҚ®жҳҜеҰӮдҪ•иў«иҺ·еҸ–жҳҜеҚҒеҲҶжңүеё®еҠ©зҡ„гҖӮдҪ еҸҜд»ҘйҖҡиҝҮд»ҘдёӢдёӨз§Қж–№ејҸиҺ·еҫ—HBaseж•°жҚ®пјҡ
В·йҖҡиҝҮ他们зҡ„иЎҢй”®пјҢжҲ–иҖ…дёҖзі»еҲ—иЎҢй”®зҡ„иЎЁжү«жҸҸгҖӮ
В·дҪҝз”Ёmap-reduceиҝӣиЎҢжү№ж“ҚдҪң
иҝҷз§ҚеҸҢйҮҚиҺ·еҸ–ж•°жҚ®зҡ„ж–№жі•дҪҝеҫ—HBaseеҸҳеҫ—еҚҒеҲҶејәеӨ§пјҢе…ёеһӢең°пјҢеңЁHadoopдёӯеӯҳеӮЁж•°жҚ®ж„Ҹе‘ізқҖе®ғеҜ№зҰ»зәҝжҲ–жү№еӨ„зҗҶж–№ејҸеҲҶжһҗжҳҜжңүзӣҠзҡ„пјҲе°Өе…¶жҳҜжү№еӨ„зҗҶеҲҶжһҗпјүпјҢдҪҶжҳҜпјҢеҜ№е®һж—¶иҺ·еҸ–жҳҜдёҚеҝ…иҰҒзҡ„гҖӮHBaseйҖҡиҝҮkey/valueеӯҳеӮЁжқҘж”ҜжҢҒе®һж—¶еҲҶжһҗпјҢд»ҘеҸҠйҖҡиҝҮmap-reduceж”ҜжҢҒжү№еӨ„зҗҶеҲҶжһҗгҖӮи®©жҲ‘们йҰ–е…ҲжқҘзңӢе®һж—¶ж•°жҚ®иҺ·еҸ–пјҢдҪңдёәkey/valueеӯҳеӮЁпјҢkeyжҳҜиЎҢй”®пјҢvalueжҳҜеҲ—з°Үзҡ„йӣҶеҗҲпјҢеҰӮеӣҫ2жүҖзӨәгҖӮ
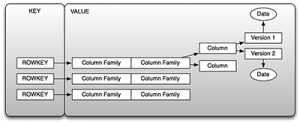
Figure2.HBaseas a Key/Value Store
еҰӮдҪ еңЁеӣҫ2дёӯзңӢеҲ°зҡ„пјҢkeyжҳҜжҲ‘们жүҖжҸҗеҲ°иҝҮзҡ„иЎҢй”®пјҢvalueжҳҜеҲ—з°Үзҡ„йӣҶеҗҲгҖӮдҪ еҸҜд»ҘйҖҡиҝҮkeyжЈҖзҙўеҲ°valueпјҢжҲ–иҖ…жҚўеҸҘиҜқиҜҙпјҢдҪ еҸҜд»ҘйҖҡиҝҮиЎҢй”®вҖңеҫ—еҲ°вҖқиЎҢпјҢжҲ–иҖ…дҪ иғҪйҖҡиҝҮз»ҷе®ҡиө·е§Ӣе’Ңз»ҲжӯўиЎҢй”®жЈҖзҙўдёҖзі»еҲ—иЎҢпјҢиҝҷе°ұжҳҜеүҚйқўжҸҗеҲ°зҡ„иЎЁжү«жҸҸгҖӮдҪ дёҚиғҪе®һж—¶зҡ„жҹҘиҜўдёҖдёӘеҲ—зҡ„еҖјпјҢиҝҷе°ұеј•еҮәдәҶдёҖдёӘйҮҚиҰҒзҡ„иҜқйўҳпјҡиЎҢй”®зҡ„и®ҫи®ЎгҖӮ
жңүдёӨдёӘеҺҹеӣ д»ӨиЎҢй”®зҡ„и®ҫи®ЎеҚҒеҲҶйҮҚиҰҒпјҡ
В·иЎЁжү«жҸҸжҳҜеҜ№иЎҢй”®зҡ„ж“ҚдҪңпјҢжүҖд»ҘпјҢиЎҢй”®зҡ„и®ҫи®ЎжҺ§еҲ¶зқҖдҪ иғҪеӨҹйҖҡиҝҮHBaseжү§иЎҢзҡ„е®һж—¶/зӣҙжҺҘиҺ·еҸ–йҮҸгҖӮ
В·еҪ“еңЁз”ҹдә§зҺҜеўғдёӯиҝҗиЎҢHBaseж—¶пјҢе®ғеңЁHDFSдёҠйғЁиҝҗиЎҢпјҢж•°жҚ®еҹәдәҺиЎҢй”®йҖҡиҝҮHDFSпјҢеҰӮжһңдҪ жүҖжңүзҡ„иЎҢй”®йғҪжҳҜд»Ҙuser-ејҖеӨҙпјҢйӮЈд№ҲеҫҲжңүеҸҜиғҪдҪ еӨ§йғЁеҲҶж•°жҚ®йғҪиў«еҲҶй…ҚдёҖдёӘиҠӮзӮ№дёҠпјҲиҝқиғҢдәҶеҲҶеёғејҸж•°жҚ®зҡ„еҲқиЎ·пјүпјҢеӣ жӯӨпјҢдҪ зҡ„иЎҢй”®еә”иҜҘжҳҜжңүи¶іеӨҹзҡ„е·®ејӮжҖ§д»ҘдҫҝеҲҶеёғејҸең°йҖҡиҝҮж•ҙдёӘйғЁзҪІгҖӮ
дҪ е®ҡд№үиЎҢй”®зҡ„ж–№ејҸеҸ–еҶідәҺдҪ жғіжҖҺж ·еӯҳеҸ–йӮЈдәӣиЎҢгҖӮеҰӮжһңдҪ жғід»Ҙз”ЁжҲ·дёәеҹәзЎҖеӯҳеӮЁж•°жҚ®пјҢйӮЈд№ҲдёҖдёӘзӯ–з•ҘжҳҜеҲ©з”Ёеӯ—иҠӮйҳҹеҲ—еңЁHBaseдёӯеӯҳеӮЁиЎҢй”®пјҢжүҖд»ҘжҲ‘们еҸҜд»ҘеҲӣе»әдёҖдёӘз”ЁжҲ·IDзҡ„е“ҲеёҢпјҲдҫӢеҰӮMD5жҲ–SHA-1пјүпјҢ然еҗҺеңЁе“ҲеёҢеҗҺйқўйҷ„дёҠж—¶й—ҙпјҲlongзұ»еһӢпјүгҖӮдҪҝз”Ёе“ҲеёҢжңүдёӨдёӘйҮҚзӮ№пјҡпјҲ1пјүжҳҜе®ғиғҪеӨҹе°ҶvalueеҲҶж•ЈејҖпјҢж•°жҚ®иғҪеӨҹеҲҶеёғејҸең°йҖҡиҝҮз°ҮпјҢпјҲ2пјүжҳҜе®ғзЎ®дҝқkeyзҡ„й•ҝеәҰжҳҜдёҖиҮҙзҡ„пјҢд»ҘжӣҙеҠ е®№жҳ“еңЁиЎЁжү«жҸҸдёӯдҪҝз”ЁгҖӮ
и®ІдәҶи¶іеӨҹеӨҡзҡ„зҗҶи®әпјҢдёӢйқўйғЁеҲҶеҗ‘дҪ еұ•зӨәеҰӮдҪ•жҗӯе»әHBaseзҺҜеўғпјҢ并еҰӮдҪ•йҖҡиҝҮе‘Ҫд»ӨиЎҢдҪҝз”ЁгҖӮ
дҪ еҸҜд»Ҙд»ҺApacheзҪ‘з«ҷдёӢиҪҪHBaseпјҢеңЁеҶҷжң¬ж–Үж—¶пјҢжңҖж–°зҡ„зүҲжң¬жҳҜ0.98.5пјҢHBaseеӣўйҳҹжҺЁиҚҗдҪ еңЁUNIX/LinuxзҺҜеўғдёӢе®үиЈ…HBaseпјҢеҰӮжһңдҪ жғіеңЁWindowsдёӢиҝҗиЎҢпјҢдҪ йңҖиҰҒе…Ҳе®үиЈ…CygwinпјҢ并еңЁиҝҷдёҠиҝҗиЎҢHBaseгҖӮеҪ“дҪ дёӢиҪҪе®Ңиҝҷдәӣж–Ү件пјҢи§ЈеҺӢеҲ°зЎ¬зӣҳдёҠгҖӮжӯӨеӨ–пјҢдҪ иҝҳйңҖиҰҒе®үиЈ…JavaзҺҜеўғпјҢеҰӮжһңдҪ иҝҳжІЎжңүпјҢд»ҺOracleзҪ‘з«ҷдёӢиҪҪJavaзҺҜеўғгҖӮеңЁзҺҜеўғй…ҚзҪ®дёӯж·»еҠ еҗҚдёәHBASE_HOMEзҡ„еҸҳйҮҸпјҢеҖјдёәдҪ и§ЈеҺӢHBaseж–Ү件зҡ„ж №зӣ®еҪ•пјҢйҡҸеҗҺпјҢжү§иЎҢbinж–Ү件еӨ№дёӢзҡ„start-hbase.shи„ҡжң¬пјҢе®ғдјҡеңЁдёӢйқўзӣ®еҪ•иҫ“еҮәж—Ҙеҝ—ж–Ү件пјҡ
$HBASE_HOME/logs/
дҪ еҸҜд»ҘеңЁжөҸи§ҲеҷЁдёӯиҫ“е…ҘдёӢйқўURLжөӢиҜ•жҳҜеҗҰе®үиЈ…жӯЈзЎ®пјҡ
http://localhost:60010
еҰӮжһңе®үиЈ…жӯЈзЎ®пјҢдҪ еә”иҜҘзңӢеҲ°дёӢйқўз•ҢйқўгҖӮ
Figure3.HBaseManagement Screen
и®©жҲ‘们ејҖе§Ӣз”Ёе‘Ҫд»ӨиЎҢж“ҚдҪңHBaseпјҢеңЁHBasebinзӣ®еҪ•дёӢжү§иЎҢдёӢйқўе‘Ҫд»Өпјҡ
./hbase shell
дҪ еә”иҜҘзңӢеҲ°еҰӮдёӢзұ»дјјзҡ„иҫ“еҮәпјҡ
HBase Shell; enter'help' for list of supported commands.
Type "exit" toleave the HBase Shell
Version0.98.5-hadoop2, rUnknown, MonAug4 23:58:06 PDT2014
hbase(main):001:0>
еҲӣе»әдёҖдёӘеҗҚдёәPageViewsзҡ„иЎЁпјҢ并具жңүеҗҚдёәinfoзҡ„еҲ—з°Үпјҡ
hbase(main):002:0> create'PageViews', 'info'
0 row(s) in 5.3160seconds
=> Hbase::Table- PageViews
жҜҸеј иЎЁиҮіе°‘иҰҒжңүдёҖдёӘеҲ—з°ҮпјҢеӣ жӯӨжҲ‘们еҲӣе»әдәҶinfoпјҢзҺ°еңЁпјҢзңӢзңӢжҲ‘们зҡ„иЎЁпјҢжү§иЎҢдёӢйқўlistе‘Ҫд»Өпјҡ
hbase(main):002:0>list
TABLE
PageViews
1 row(s) in 0.0350seconds
=>["PageViews"]
еҰӮдҪ жүҖи§ҒпјҢlistе‘Ҫд»Өиҝ”еӣһдёҖдёӘеҗҚдёәPageViewsзҡ„иЎЁпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮdescribeе‘Ҫд»Өеҫ—еҲ°иЎЁзҡ„жӣҙеӨҡдҝЎжҒҜпјҡ
hbase(main):003:0> describe'PageViews'
DESCRIPTIONENABLED
'PageViews',{NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER=> 'ROW',
REPLICATION_SCOPE=> '0', VERSIONS => '1', COMPRESSION => 'NONEtrue
',MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS=> 'false',
BLOCKSIZE=> '65536', IN_MEMORY => 'false', BLOCKCACHE =>'true'}
1 row(s) in 0.0480secondsDescribeе‘Ҫд»Өиҝ”еӣһиЎЁзҡ„иҜҰз»ҶдҝЎжҒҜпјҢеҢ…жӢ¬еҲ—з°Үзҡ„еҲ—иЎЁпјҢиҝҷйҮҢжҲ‘们еҲӣе»әзҡ„д»…жңүдёҖдёӘпјҡinfoпјҢзҺ°еңЁдёәиЎЁж·»еҠ д»ҘдёӢж•°жҚ®пјҢдёӢйқўе‘Ҫд»ӨжҳҜеңЁinfoдёӯж·»еҠ ж–°зҡ„иЎҢпјҡ
hbase(main):004:0> put'PageViews', 'rowkey1', 'info:page', '/mypage'
0 row(s) in 0.0850seconds
Putе‘Ҫд»ӨжҸ’е…ҘдёҖжқЎиЎҢй”®дёәrowkey1зҡ„ж–°зәӘеҪ•пјҢжҢҮе®ҡеңЁinfoдёӢзҡ„pageеҲ—пјҢжҸ’е…ҘеҖјдёә/mypageзҡ„и®°еҪ•пјҢжҲ‘们йҡҸеҗҺеҸҜд»ҘйҖҡиҝҮgetе‘Ҫд»ӨйҖҡиҝҮиЎҢй”®rowkey1жҹҘиҜўеҲ°иҝҷжқЎи®°еҪ•пјҡ
hbase(main):005:0> get'PageViews', 'rowkey1'
COLUMNCELL
info:pagetimestamp=1410374788088, value=/mypage
1 row(s) in 0.0250seconds
дҪ еҸҜд»ҘзңӢеҲ°еҲ—infoпјҡpageпјҢжҲ–иҖ…жӣҙеӨҡе…·дҪ“зҡ„еҲ—пјҢе…¶еҖјдёә/mypageпјҢ并еёҰжңүж—¶й—ҙжҲіиЎЁжҳҺиҜҘжқЎи®°еҪ•жҳҜд»Җд№Ҳж—¶еҖҷжҸ’е…Ҙзҡ„гҖӮи®©жҲ‘们еңЁеҒҡиЎЁжү«жҸҸд№ӢеүҚеҶҚж·»еҠ дёҖиЎҢпјҡ
hbase(main):006:0> put'PageViews', 'rowkey2', 'info:page', '/myotherpage'
0 row(s) in 0.0050seconds
зҺ°еңЁжҲ‘们жңүдёӨиЎҢи®°еҪ•дәҶпјҢи®©жҲ‘们жҹҘиҜўеҮәPageViewsиЎЁзҡ„жүҖжңүи®°еҪ•пјҡ
hbase(main):007:0> scan'PageViews'
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
2 row(s) in 0.0350seconds
еҰӮеүҚйқўжүҖжҸҗеҲ°зҡ„пјҢжҲ‘们дёҚиғҪжҹҘиҜўжң¬иә«пјҢдҪҶжҳҜжҲ‘们еҸҜд»ҘеҜ№иЎЁиҝӣиЎҢscanж“ҚдҪңпјҢеҰӮжһңдҪ жү§иЎҢscantableе‘Ҫд»ӨпјҢе®ғдјҡиҝ”еӣһиЎЁдёӯжүҖжңүиЎҢпјҢиҝҷеҫҲжңүеҸҜиғҪдёҚжҳҜдҪ жғіиҰҒеҒҡзҡ„гҖӮдҪ еҸҜд»Ҙз»ҷеҮәиЎҢзҡ„иҢғеӣҙжқҘйҷҗеҲ¶иҝ”еӣһзҡ„з»“жһңпјҢи®©жҲ‘们жҸ’е…ҘдёҖеёҰжңүsејҖеӨҙиЎҢй”®зҡ„ж–°и®°еҪ•пјҡ
hbase(main):012:0> put'PageViews', 'srowkey2', 'info:page', '/myotherpage'
зҺ°еңЁпјҢеҰӮжһңжҲ‘еўһеҠ зӮ№йҷҗеҲ¶пјҢжғіжҹҘиҜўиЎҢй”®еңЁrе’Ңsд№Ӣй—ҙзҡ„и®°еҪ•пјҢеҸҜд»ҘдҪҝз”ЁеҰӮдёӢз»“жһ„пјҡ
hbase(main):014:0> scan'PageViews', { STARTROW => 'r', ENDROW => 's' }
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
2 row(s) in 0.0080secondsиҝҷдёӘscanиҝ”еӣһдәҶд»…жңүsејҖеӨҙзҡ„и®°еҪ•пјҢиҝҷдёӘзұ»жҜ”жҳҜеҹәдәҺе…ЁиЎҢй”®дёҠзҡ„пјҢжүҖд»Ҙrowkey1жҜ”rеӨ§пјҢжүҖжңүе®ғиў«иҝ”еӣһдәҶгҖӮеҸҰеӨ–пјҢscanзҡ„з»“жһңеҢ…еҗ«дәҶжүҖжҢҮиҢғеӣҙзҡ„STARTROWпјҢдҪҶдёҚеҢ…еҗ«ENDROWпјҢжіЁж„ҸпјҢENDROWдёҚжҳҜеҝ…йЎ»жҢҮе®ҡзҡ„пјҢеҰӮжһңжҲ‘们жү§иЎҢзӣёеҗҢжҹҘиҜўеҸӘз»ҷеҮәдәҶSTARTROWпјҢйӮЈд№ҲжҲ‘们дјҡеҫ—еҲ°иЎҢй”®жҜ”rеӨ§зҡ„жүҖжңүи®°еҪ•гҖӮ
hbase(main):013:0> scan'PageViews', { STARTROW => 'r' }
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
srowkey2column=info:page,timestamp=1410375975965, value=/myotherpage
3 row(s) in 0.0120secondsHBaseжҳҜдёҖз§ҚNoSQLпјҢйҖҡеёёиў«з§°дёәHadoop DatabaseпјҢе®ғжҳҜејҖжәҗ并еҹәдәҺGoogle BigTableзҷҪзҡ®д№ҰпјҢHBaseиҝҗиЎҢеңЁHDFSд№ӢдёҠпјҢеӣ жӯӨдҪҝе®ғе…·жңүй«ҳеәҰеҸҜжү©еұ•жҖ§пјҢ并ж”ҜжҢҒHadoopmap-reduceзЁӢеәҸи®ҫи®ЎжЁЎеһӢгҖӮHBaseжңүдёӨз§Қи®ҝй—®ж–№ејҸпјҡйҖҡиҝҮиЎҢй”®иҝӣиЎҢйҡҸжңәи®ҝй—®пјӣйҖҡиҝҮmap-reduceи„ұжңәжҲ–жү№и®ҝй—®гҖӮ
е…ідәҺдҪҝз”Ёhbaseзҡ„дјҳзӮ№жңүе“Әдәӣе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





