原文:http://proxysql.com/blog/scaling-with-proxysql-query-cache
作者:Rene
在写关于ProxySQL 查询缓存之前,让我们先看一下MySQL 查询缓存。
MySQL 查询缓存是一个非常有趣的特性,引用官档:
将SELECT语句的文本与发送到客户端的结果存储在一起。之后如果接收到一个相同的语句,服务层从查询缓存中返回结果,而不是再次解析和执行该语句
它是一个缓存,旨在提升性能。然而,他不是‘灵丹妙药’,并时不时的能看到严重的性能下降或随机冻结 (random freezes)。为什么?
Peter Zaitsev 写了一系列的文章来介绍 MySQL 查询缓存是什么(MySQL Query Cache is) 和 一系列关于给它第二次机会的观点(second chance).
但事实是,由于锁定和失效算法MySQL查询缓存很难进行扩展。这里不会重复为什么不能扩展的技术细节,提到的这些文章很好的描述了原因。
如果你想优化你的MySQL Query Cache, 我强烈推荐 Domas Mituzas 的 query cache tuner(注: 网络没有问题,就是 0)
ProxySQL 查询缓存与 MySQL 查询缓存完全不同。
它是一个 存储在内存中的 键/值 ,使用:
key 是用户名,库名和查询文本的结合
value 是后端返回的结果集(mysqld,或者另一个proxysql)
使ProxySQL中条目失效的唯一方法需要通过以毫秒为单位的生存时间(time-to-live)。一些人认为通过生存时间失效是有限制的,但对于多数的应用不会有这种情况。如果应用需要绝对正确的数据,透明缓存可能不是正确的解决方案。
任何可以接受 从slave 读取稍微过时数据的应用都可以从QC(query cache)受益。
这个概念已经不是新的了,驱动程序本身就有查询缓存的实现:例如mysqlnd。
我描述MySQL Query Cache 和 ProxySQL Query Cache 的原因是他们的性质不同,因此意味着比较它们两个不是微不足道的,它们无法进行同类比较。
已知Mysql Query Cache 不能进行很好的扩展。我找到的关于 Mysql Query Cache 不能很好扩展的基准测试 是 Szymon Komendera(亚马逊极光(Amazon Aurora)数据库工程师) 发表的博客(需要×××)。在博客中,带有4GB 查询缓存的Aurora 能提升MySQL性能达3.1倍(此处为Aurora QC 与 Mysql QC的对比) 。
我将按照同样的方法进行基准测试,观察用MySQL Query Cache能否得到相似的结果并且观察Proxy Query Cache能提升多少性能。
初始化设置
2个带有sysbench 0.5的客户端。
使用两个客户端的原因:在目前硬件的条件下,一个客户端不能生成足够的流量,使Proxy Query Cache 到达极限。
sysbench命令:
./sysbench --num-threads=512 --max-time=900 --max-requests=0 --test=./tests/db/oltp.lua --mysql-user=sbtest --mysql-password=sbtest --mysql-host=10.1.1.22 --oltp-table-size=10000000 --mysql-port=${PORT} --mysql-ps-mode=disable --oltp-read-only=on --oltp-point-selects=25 --oltp-skip-trx=on --oltp-sum-ranges=0 --oltp-simple-ranges=0 --oltp-distinct-ranges=0 --oltp-order-ranges=0 --oltp-dist-type=uniform run
1个mysql数据库(Percona Server 5.6.25) 和 proxysql(1.4.0)
在整个测试过程中,所有的数据已经缓存在InnoDB buffer pool (在内存中,没有涉及IO),测试前重置Query Cache。
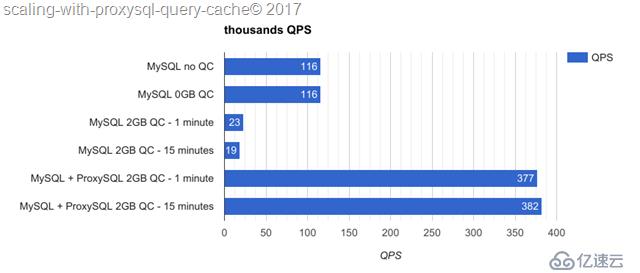
上图的结果表明,mysql QC确实无法扩展,并且使用它能导致性能下降84%。另一方面,ProxySQL QC 提升性能3.3倍
另一个有趣的结果是,根据测试时长不同得到的不同结果。
使用Mysql QC,基准测试时间越长,吞吐量越低(明显降低)。
使用ProxySQL QC,吞吐量没有下降,但1%的提升考虑是波动导致的。
上述结果需要注意的是:这个环境下可以生成一千万条不同的SELECT 语句,因此Query Cache中有一千万条目,因为表的大小有一千万。
较小的 --oltp-table-size 将导致 MySQL no QC 和 ProxySQL QC 有更高的结果。事实上,出于好奇,使用 --oltp-table-size=1000000 一个单实例ProxySQL 可以返回超过一百万的QPS。
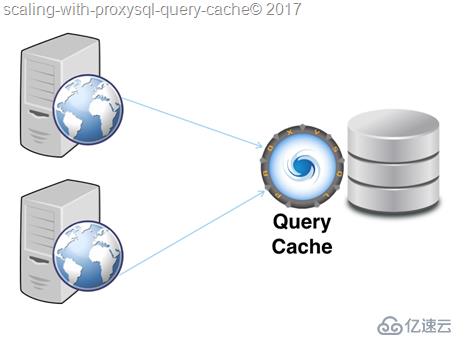
目前为止,我将ProxySQL 与 MySQL 运行在一起。Why? 这样做是为了模拟当前查询缓存在数据本身之前的期望。
虽然我相信对于大多数的工作负载,缓存层不应该靠近数据存储的位置(后端),应该靠近数据消耗的地方(前端)。例如,mysqlnd。
如果我们使用前面的测试环境,将ProxySQL 从数据库服务器移动到应用服务器,会发生什么呢?
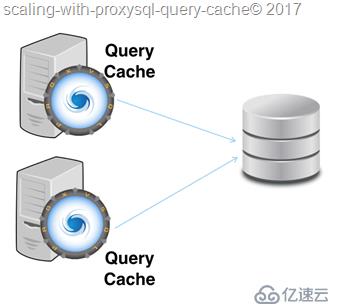
我们现在有两个ProxySQL实例。
不足为奇,它扩展的更好。数据库服务器目前只需执行查询缓存中没有的sql。
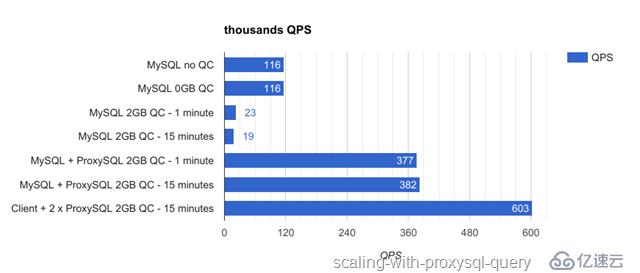
ProxySQL使用在数据库服务器,QC提升3.3倍性能。
ProxySQL使用在客户端,QC提升5.2倍性能!
我们能否得到更好的结果?可能会的。因为QC可以移动并分散(不再需要在数据库服务器中),我们也能创建更复杂的配置,分离缓存层本身。例如,能够创建两个分片,每个分片处理和缓存一半的查询,或者也可以创建多层的缓存系统。
尽管MySQL 查询缓存 旨在提升性能,但它有严重的可扩展性问题并容易成为严重的瓶颈。
ProxySQL Query Cache 能大幅提升一些特定工作负载的性能:读密集型,能够被缓存很多的结果。ProxySQL 仍允许分散缓存层,并且可以将缓存层从数据库服务器移动到离应用层更近的地方。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务