今天整理之前的运维资料,发现了自己整理的一次刀片服务器(运行的vmware虚拟化)事故处理流程,所以记录下,备忘。
一、事件处理过程
14:10 接到机房运维工程师通知,Opmanager监控系统上出现了多台服务器宕机现象,并且均为虚拟机。
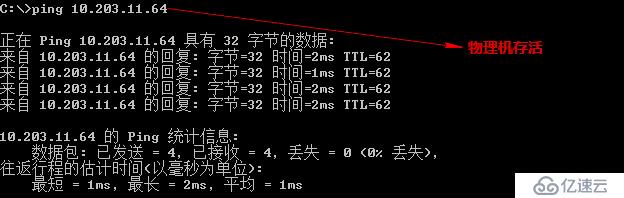
14:12 通知机房运维工程师检查HP刀片服务器是否有告警,远程登录vcenter进行检查。远程查看发现ESX04(10.203.11.64)出现告警,告警信息如下图所示:
 14:15 通知工程师ESX04出现告警,然后确认该刀片服务器是否存活,并进入机房确认设备上是否有硬件上的告警。
14:15 通知工程师ESX04出现告警,然后确认该刀片服务器是否存活,并进入机房确认设备上是否有硬件上的告警。
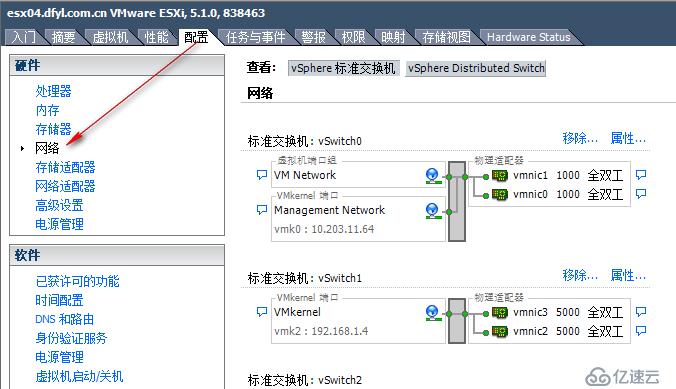
14:16 检查逻辑上的网络接口是否存在异常
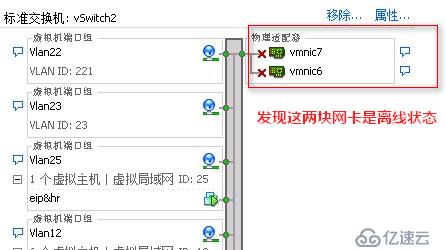
如下图所示,发现有两块网卡处于离线状态
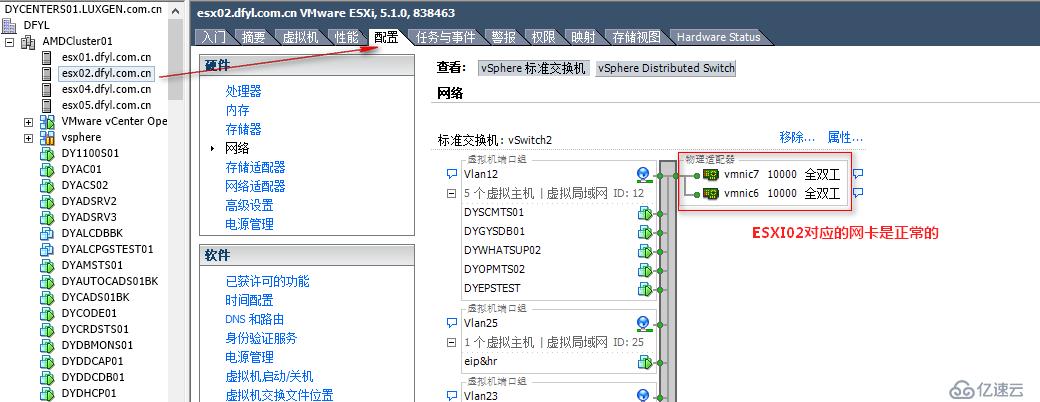
14:18 检查其它刀片,发现ESXI02对应的网卡,发现为正常的
14:20 登录HP刀片管理控制台查看,未发现服务器告警信息。
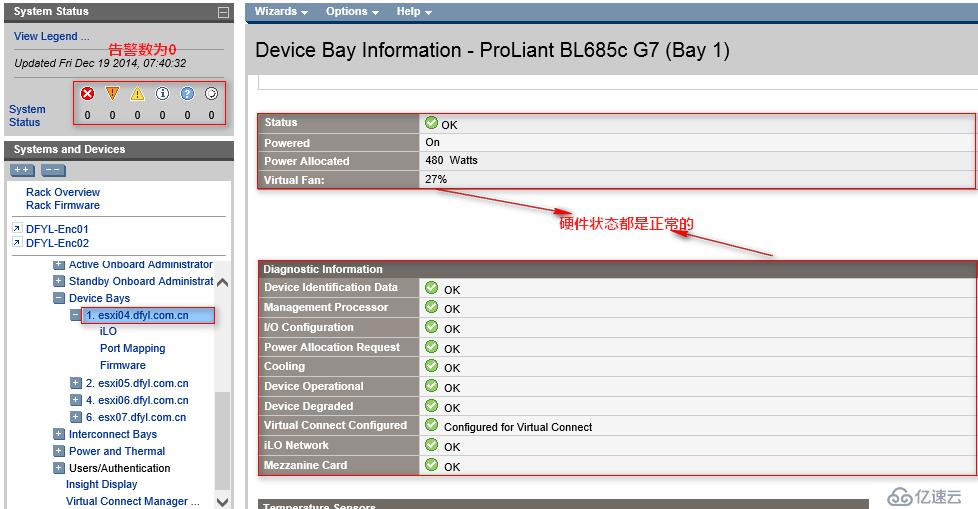
14:19 参照其它EXSI,尝试更改vmnic6、vmnic7两块网卡模式,该操作无法生效
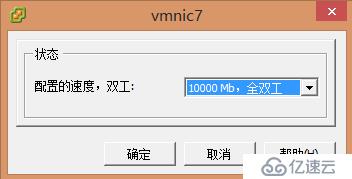
更改网卡模式无法生效
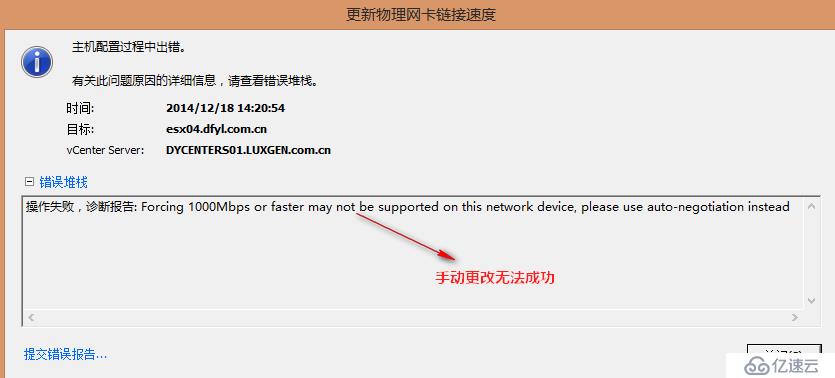
14:27 在ESX04进行手动迁移虚拟机到其他主机上,迁移失败。
14:58 将ESX04主机上的虚拟机全部关机

15:20 重启ESXI主机,HA 自动将开着的虚拟机迁移到其他EXSI主机上启动
15:30 ESX04主机启动成功后,vsphereHA尝试自动将虚拟机迁移回ESX04主机失败,
15:50 手动迁移部分虚拟机回ESX04主机,观察运行状态。
二、日志分析
1、远程登录到ESXI的命令行,查看vmkernel的日志:
说明:由于esxi4采用的是utc时间,日志中显示的较时间时间会慢8小时
/var/log # cat /var/log/vmkernel.log | grep '2014-12-18' 2014-12-18T03:27:49.106Zcpu46:6396479)WARNING: ScsiDeviceIO: 1211: Devicenaa.60014380064900f30000800000e40000 performance hasdeteriorated. I/O latency increased from average value of 3303 microseconds to68755 microseconds. 2014-12-18T03:31:54.595Zcpu8:16392)ScsiDeviceIO: 1191: Device naa.60014380064900f30000800000e40000performance has improved. I/O latency reduced from 68755 microseconds to 13691microseconds. 2014-12-18T03:32:32.643Zcpu12:17017)MigrateNet: vm 17017: 2061: Accepted connection from <10.203.11.100> 2014-12-18T03:32:32.643Zcpu12:17017)MigrateNet: vm 17017: 2131: dataSocket 0x4100253292f0 receivebuffer size is 563560 2014-12-18T03:32:32.644Z cpu12:17017)WARNING:Migrate: 262: Invalid message type for new connection: 542393671. Expecting message
如上面的日志显示:13:27,主机的性能开始下降,I/O延迟变的较大
2、查看10.203.11.100是否有相关告警:
 如上图所示,提示esx04主机的网卡状态出现错误
如上图所示,提示esx04主机的网卡状态出现错误

3、收集的其它日志如下,暂未发现异常

整个处理过程到此基本完成,所有的刀片服务器中,也就这台偶尔抽风,也没有明显的特征
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





