这篇文章运用简单易懂的例子给大家介绍一文带读懂zookeeper的选举机制,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
zookeeper集群
配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的。

这篇主要分析leader的选择机制,zookeeper提供了三种方式:
默认的算法是FastLeaderElection,所以这篇主要分析它的选举机制。
选择机制中的概念
服务器ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
数据ID
服务器中存放的最大数据ID.
值越大说明数据越新,在选举算法中数据越新权重越大。
逻辑时钟
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
选举状态
选举消息内容
在投票完成后,需要将投票信息发送给集群中的所有服务器,它包含如下内容。
选举流程图
因为每个服务器都是独立的,在启动时均从初始状态开始参与选举,下面是简易流程图。

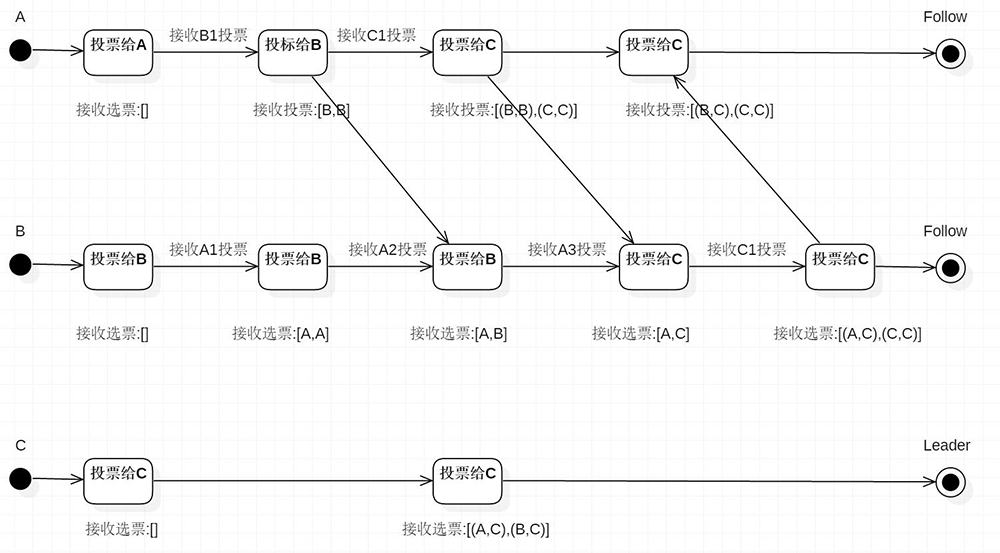
选举状态图
描述Leader选择过程中的状态变化,这是假设全部实例中均没有数据,假设服务器启动顺序分别为:A,B,C。
源码分析
QuorumPeer
主要看这个类,只有LOOKING状态才会去执行选举算法。每个服务器在启动时都会选择自己做为领导,然后将投票信息发送出去,循环一直到选举出领导为止。
public void run() {
//.......
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
//...
try {
//投票给自己...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
} finally {
//...
}
} else {
try {
//...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
}
}
break;
case OBSERVING:
//...
break;
case FOLLOWING:
//...
break;
case LEADING:
//...
break;
}
}
} finally {
//...
}
}FastLeaderElection
它是zookeeper默认提供的选举算法,核心方法如下:具体的可以与本文上面的流程图对照。
public Vote lookForLeader() throws InterruptedException {
//...
try {
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized(this){
//给自己投票
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
//将投票信息发送给集群中的每个服务器
sendNotifications();
//循环,如果是竞选状态一直到选举出结果
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
//没有收到投票信息
if(n == null){
if(manager.haveDelivered()){
sendNotifications();
} else {
manager.connectAll();
}
//...
}
//收到投票信息
else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) {
switch (n.state) {
case LOOKING:
// 判断投票是否过时,如果过时就清除之前已经接收到的信息
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
//更新投票信息
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
//发送投票信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//忽略
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//更新投票信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
if (n == null) {
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid, proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
//忽略
break;
case FOLLOWING:
case LEADING:
//如果是同一轮投票
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if(termPredicate(recvset, new Vote(n.leader,
n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
//记录投票已经完成
outofelection.put(n.sid, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state));
if (termPredicate(outofelection, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, IGNOREVALUE)) {
synchronized(this){
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
//忽略
break;
}
} else {
LOG.warn("Ignoring notification from non-cluster member " + n.sid);
}
}
return null;
} finally {
//...
}
}判断是否已经胜出
默认是采用投票数大于半数则胜出的逻辑。
选举流程简述
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
关于一文带读懂zookeeper的选举机制就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





