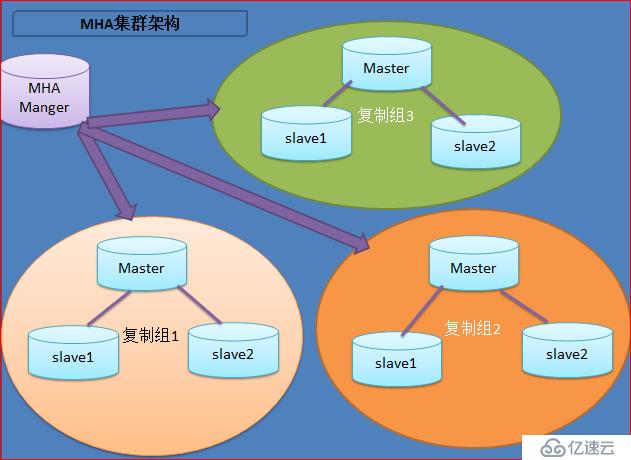
MySQL й«ҳеҸҜз”ЁйӣҶзҫӨжһ¶жһ„ MHA
MHAпјҲMaster HighAvailabilityпјүзӣ®еүҚеңЁMySQLй«ҳеҸҜз”Ёж–№йқўжҳҜдёҖдёӘзӣёеҜ№жҲҗзҶҹзҡ„и§ЈеҶіж–№жЎҲпјҢе®ғз”ұж—Ҙжң¬DeNAе…¬еҸёyoushimatonпјҲзҺ°е°ұиҒҢдәҺFacebookе…¬еҸёпјүејҖеҸ‘пјҢжҳҜдёҖеҘ—дјҳз§Җзҡ„дҪңдёәMySQLй«ҳеҸҜз”ЁжҖ§зҺҜеўғдёӢж•…йҡңеҲҮжҚўе’Ңдё»д»ҺжҸҗеҚҮзҡ„й«ҳеҸҜз”ЁиҪҜ件гҖӮеңЁMySQLж•…йҡңеҲҮжҚўиҝҮзЁӢдёӯпјҢMHAиғҪеҒҡеҲ°еңЁ0~30з§’д№ӢеҶ…иҮӘеҠЁе®ҢжҲҗж•°жҚ®еә“зҡ„ж•…йҡңеҲҮжҚўж“ҚдҪңпјҢ并且еңЁиҝӣиЎҢж•…йҡңеҲҮжҚўзҡ„иҝҮзЁӢдёӯпјҢMHAиғҪеңЁжңҖеӨ§зЁӢеәҰдёҠдҝқиҜҒж•°жҚ®зҡ„дёҖиҮҙжҖ§пјҢд»ҘиҫҫеҲ°зңҹжӯЈж„Ҹд№үдёҠзҡ„й«ҳеҸҜз”ЁгҖӮ
MHAйҮҢжңүдёӨдёӘи§’иүІдёҖдёӘжҳҜMHA NodeпјҲж•°жҚ®иҠӮзӮ№пјүеҸҰдёҖдёӘжҳҜMHA ManagerпјҲз®ЎзҗҶиҠӮзӮ№пјүгҖӮ
MHA ManagerеҸҜд»ҘеҚ•зӢ¬йғЁзҪІеңЁдёҖеҸ°зӢ¬з«Ӣзҡ„жңәеҷЁдёҠз®ЎзҗҶеӨҡдёӘmaster-slaveйӣҶзҫӨпјҢд№ҹеҸҜд»ҘйғЁзҪІеңЁдёҖеҸ°slaveиҠӮзӮ№дёҠгҖӮMHA NodeиҝҗиЎҢеңЁжҜҸеҸ°MySQLжңҚеҠЎеҷЁдёҠпјҢMHA Managerдјҡе®ҡж—¶жҺўжөӢйӣҶзҫӨдёӯзҡ„masterиҠӮзӮ№пјҢеҪ“masterеҮәзҺ°ж•…йҡңж—¶пјҢе®ғеҸҜд»ҘиҮӘеҠЁе°ҶжңҖж–°ж•°жҚ®зҡ„slaveжҸҗеҚҮдёәж–°зҡ„masterпјҢ然еҗҺе°ҶжүҖжңүе…¶д»–зҡ„slaveйҮҚж–°жҢҮеҗ‘ж–°зҡ„masterгҖӮж•ҙдёӘж•…йҡңиҪ¬з§»иҝҮзЁӢеҜ№еә”з”ЁзЁӢеәҸе®Ңе…ЁйҖҸжҳҺгҖӮ
еңЁMHAиҮӘеҠЁж•…йҡңеҲҮжҚўиҝҮзЁӢдёӯпјҢMHAиҜ•еӣҫд»Һе®•жңәзҡ„дё»жңҚеҠЎеҷЁдёҠдҝқеӯҳдәҢиҝӣеҲ¶ж—Ҙеҝ—пјҢжңҖеӨ§зЁӢеәҰзҡ„дҝқиҜҒж•°жҚ®зҡ„дёҚдёўеӨұпјҢдҪҶиҝҷ并дёҚжҖ»жҳҜеҸҜиЎҢзҡ„гҖӮдҫӢеҰӮпјҢеҰӮжһңдё»жңҚеҠЎеҷЁзЎ¬д»¶ж•…йҡңжҲ–ж— жі•йҖҡиҝҮsshи®ҝй—®пјҢMHAжІЎжі•дҝқеӯҳдәҢиҝӣеҲ¶ж—Ҙеҝ—пјҢеҸӘиҝӣиЎҢж•…йҡңиҪ¬з§»иҖҢдёўеӨұдәҶжңҖж–°зҡ„ж•°жҚ®гҖӮдҪҝз”ЁMySQL 5.5зҡ„еҚҠеҗҢжӯҘеӨҚеҲ¶пјҢеҸҜд»ҘеӨ§еӨ§йҷҚдҪҺж•°жҚ®дёўеӨұзҡ„йЈҺйҷ©гҖӮMHAеҸҜд»ҘдёҺеҚҠеҗҢжӯҘеӨҚеҲ¶з»“еҗҲиө·жқҘгҖӮеҰӮжһңеҸӘжңүдёҖдёӘslaveе·Із»Ҹ收еҲ°дәҶжңҖж–°зҡ„дәҢиҝӣеҲ¶ж—Ҙеҝ—пјҢMHAеҸҜд»Ҙе°ҶжңҖж–°зҡ„дәҢиҝӣеҲ¶ж—Ҙеҝ—еә”з”ЁдәҺе…¶д»–жүҖжңүзҡ„slaveжңҚеҠЎеҷЁдёҠпјҢеӣ жӯӨеҸҜд»ҘдҝқиҜҒжүҖжңүиҠӮзӮ№зҡ„ж•°жҚ®дёҖиҮҙжҖ§гҖӮ
жіЁпјҡд»ҺMySQL5.5ејҖе§ӢпјҢMySQLд»ҘжҸ’件зҡ„еҪўејҸж”ҜжҢҒеҚҠеҗҢжӯҘеӨҚеҲ¶гҖӮеҰӮдҪ•зҗҶи§ЈеҚҠеҗҢжӯҘе‘ўпјҹйҰ–е…ҲжҲ‘们жқҘзңӢзңӢејӮжӯҘпјҢе…ЁеҗҢжӯҘзҡ„жҰӮеҝөпјҡ
ејӮжӯҘеӨҚеҲ¶пјҲAsynchronous replicationпјү
MySQLй»ҳи®Өзҡ„еӨҚеҲ¶еҚіжҳҜејӮжӯҘзҡ„пјҢдё»еә“еңЁжү§иЎҢе®Ңе®ўжҲ·з«ҜжҸҗдәӨзҡ„дәӢеҠЎеҗҺдјҡз«ӢеҚіе°Ҷз»“жһңиҝ”з»ҷз»ҷе®ўжҲ·з«ҜпјҢ并дёҚе…іеҝғд»Һеә“жҳҜеҗҰе·Із»ҸжҺҘ收并еӨ„зҗҶпјҢиҝҷж ·е°ұдјҡжңүдёҖдёӘй—®йўҳпјҢдё»еҰӮжһңcrashжҺүдәҶпјҢжӯӨж—¶дё»дёҠе·Із»ҸжҸҗдәӨзҡ„дәӢеҠЎеҸҜиғҪ并没жңүдј еҲ°д»ҺдёҠпјҢеҰӮжһңжӯӨж—¶пјҢејәиЎҢе°Ҷд»ҺжҸҗеҚҮдёәдё»пјҢеҸҜиғҪеҜјиҮҙж–°дё»дёҠзҡ„ж•°жҚ®дёҚе®Ңж•ҙгҖӮ
е…ЁеҗҢжӯҘеӨҚеҲ¶пјҲFully synchronous replicationпјү
жҢҮеҪ“дё»еә“жү§иЎҢе®ҢдёҖдёӘдәӢеҠЎпјҢжүҖжңүзҡ„д»Һеә“йғҪжү§иЎҢдәҶиҜҘдәӢеҠЎжүҚиҝ”еӣһз»ҷе®ўжҲ·з«ҜгҖӮеӣ дёәйңҖиҰҒзӯүеҫ…жүҖжңүд»Һеә“жү§иЎҢе®ҢиҜҘдәӢеҠЎжүҚиғҪиҝ”еӣһпјҢжүҖд»Ҙе…ЁеҗҢжӯҘеӨҚеҲ¶зҡ„жҖ§иғҪеҝ…然дјҡеҸ—еҲ°дёҘйҮҚзҡ„еҪұе“ҚгҖӮ
еҚҠеҗҢжӯҘеӨҚеҲ¶пјҲSemisynchronous replicationпјү
д»ӢдәҺејӮжӯҘеӨҚеҲ¶е’Ңе…ЁеҗҢжӯҘеӨҚеҲ¶д№Ӣй—ҙпјҢдё»еә“еңЁжү§иЎҢе®Ңе®ўжҲ·з«ҜжҸҗдәӨзҡ„дәӢеҠЎеҗҺдёҚжҳҜз«ӢеҲ»иҝ”еӣһз»ҷе®ўжҲ·з«ҜпјҢиҖҢжҳҜзӯүеҫ…иҮіе°‘дёҖдёӘд»Һеә“жҺҘ收еҲ°е№¶еҶҷеҲ°relay logдёӯжүҚиҝ”еӣһз»ҷе®ўжҲ·з«ҜгҖӮзӣёеҜ№дәҺејӮжӯҘеӨҚеҲ¶пјҢеҚҠеҗҢжӯҘеӨҚеҲ¶жҸҗй«ҳдәҶж•°жҚ®зҡ„е®үе…ЁжҖ§пјҢеҗҢж—¶е®ғд№ҹйҖ жҲҗдәҶдёҖе®ҡзЁӢеәҰзҡ„延иҝҹпјҢиҝҷдёӘ延иҝҹжңҖе°‘жҳҜдёҖдёӘTCP/IPеҫҖиҝ”зҡ„ж—¶й—ҙгҖӮжүҖд»ҘпјҢеҚҠеҗҢжӯҘеӨҚеҲ¶жңҖеҘҪеңЁдҪҺ延时зҡ„зҪ‘з»ңдёӯдҪҝз”ЁгҖӮ
дёӢйқўжқҘзңӢзңӢеҚҠеҗҢжӯҘеӨҚеҲ¶зҡ„еҺҹзҗҶеӣҫпјҡ
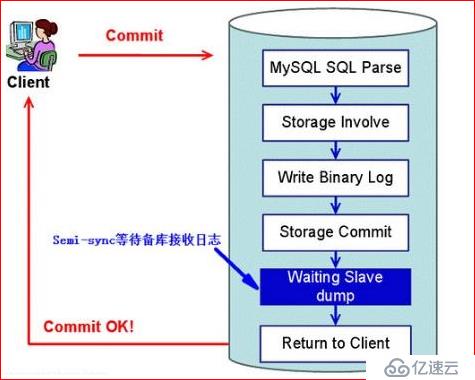
жҖ»з»“пјҡејӮжӯҘдёҺеҚҠеҗҢжӯҘејӮеҗҢ
й»ҳи®Өжғ…еҶөдёӢMySQLзҡ„еӨҚеҲ¶жҳҜејӮжӯҘзҡ„пјҢMasterдёҠжүҖжңүзҡ„жӣҙж–°ж“ҚдҪңеҶҷе…ҘBinlogд№ӢеҗҺ并дёҚзЎ®дҝқжүҖжңүзҡ„жӣҙж–°йғҪиў«еӨҚеҲ¶еҲ°Slaveд№ӢдёҠгҖӮејӮжӯҘж“ҚдҪңиҷҪ然ж•ҲзҺҮй«ҳпјҢдҪҶжҳҜеңЁMaster/SlaveеҮәзҺ°й—®йўҳзҡ„ж—¶еҖҷпјҢеӯҳеңЁеҫҲй«ҳж•°жҚ®дёҚеҗҢжӯҘзҡ„йЈҺйҷ©пјҢз”ҡиҮіеҸҜиғҪдёўеӨұж•°жҚ®гҖӮ
MySQL5.5еј•е…ҘеҚҠеҗҢжӯҘеӨҚеҲ¶еҠҹиғҪзҡ„зӣ®зҡ„жҳҜдёәдәҶдҝқиҜҒеңЁmasterеҮәй—®йўҳзҡ„ж—¶еҖҷпјҢиҮіе°‘жңүдёҖеҸ°Slaveзҡ„ж•°жҚ®жҳҜе®Ңж•ҙзҡ„гҖӮеңЁи¶…ж—¶зҡ„жғ…еҶөдёӢд№ҹеҸҜд»Ҙдёҙж—¶иҪ¬е…ҘејӮжӯҘеӨҚеҲ¶пјҢдҝқйҡңдёҡеҠЎзҡ„жӯЈеёёдҪҝз”ЁпјҢзӣҙеҲ°дёҖеҸ°salveиҝҪиө¶дёҠд№ӢеҗҺпјҢ继з»ӯеҲҮжҚўеҲ°еҚҠеҗҢжӯҘжЁЎејҸгҖӮ
е·ҘдҪңеҺҹзҗҶпјҡ
зӣёиҫғдәҺе…¶е®ғHAиҪҜ件пјҢMHAзҡ„зӣ®зҡ„еңЁдәҺз»ҙжҢҒMySQL ReplicationдёӯMasterеә“зҡ„й«ҳеҸҜз”ЁжҖ§пјҢе…¶жңҖеӨ§зү№зӮ№жҳҜеҸҜд»Ҙдҝ®еӨҚеӨҡдёӘSlaveд№Ӣй—ҙзҡ„е·®ејӮж—Ҙеҝ—пјҢжңҖз»ҲдҪҝжүҖжңүSlaveдҝқжҢҒж•°жҚ®дёҖиҮҙпјҢ然еҗҺд»ҺдёӯйҖүжӢ©дёҖдёӘе……еҪ“ж–°зҡ„MasterпјҢ并е°Ҷе…¶е®ғSlaveжҢҮеҗ‘е®ғгҖӮ
-д»Һе®•жңәеҙ©жәғзҡ„masterдҝқеӯҳдәҢиҝӣеҲ¶ж—Ҙеҝ—дәӢ件(binlogevents)гҖӮ
-иҜҶеҲ«еҗ«жңүжңҖж–°жӣҙж–°зҡ„slaveгҖӮ
-еә”з”Ёе·®ејӮзҡ„дёӯ继ж—Ҙеҝ—(relay log)еҲ°е…¶е®ғslaveгҖӮ
-еә”з”Ёд»Һmasterдҝқеӯҳзҡ„дәҢиҝӣеҲ¶ж—Ҙеҝ—дәӢ件(binlogevents)гҖӮ
-жҸҗеҚҮдёҖдёӘslaveдёәж–°masterгҖӮ
-дҪҝе…¶е®ғзҡ„slaveиҝһжҺҘж–°зҡ„masterиҝӣиЎҢеӨҚеҲ¶гҖӮ
зӣ®еүҚMHAдё»иҰҒж”ҜжҢҒдёҖдё»еӨҡд»Һзҡ„жһ¶жһ„пјҢиҰҒжҗӯе»әMHA,иҰҒжұӮдёҖдёӘеӨҚеҲ¶йӣҶзҫӨдёӯеҝ…йЎ»жңҖе°‘жңүдёүеҸ°ж•°жҚ®еә“жңҚеҠЎеҷЁпјҢдёҖдё»дәҢд»ҺпјҢеҚідёҖеҸ°е……еҪ“masterпјҢдёҖеҸ°е……еҪ“еӨҮз”ЁmasterпјҢеҸҰеӨ–дёҖеҸ°е……еҪ“д»Һеә“пјҢеӣ дёәиҮіе°‘йңҖиҰҒдёүеҸ°жңҚеҠЎеҷЁгҖӮ
йғЁзҪІзҺҜеўғеҰӮдёӢпјҡ
| и§’иүІ | Ip | дё»жңәеҗҚ | os |
| master | 192.168.137.134 | master | centos 6.5 x86_64 |
| Candidate | 192.168.137.130 | Candidate |
|
| slave+manage | 192.168.137.146 | slave |
|
е…¶дёӯmasterеҜ№еӨ–жҸҗдҫӣеҶҷжңҚеҠЎпјҢCandidateдёәеӨҮйҖүmasterпјҢз®ЎзҗҶиҠӮзӮ№ж”ҫеңЁзәҜslaveжңәеҷЁдёҠгҖӮmasterдёҖж—Ұе®•жңәпјҢCandidateжҸҗеҚҮдёәдё»еә“
дёҖгҖҒеҹәзЎҖзҺҜеўғеҮҶеӨҮ
1гҖҒеңЁ3еҸ°жңәеҷЁдёҠй…ҚзҪ®epelжәҗ
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
2гҖҒе»әз«Ӣsshж— дәӨдә’зҷ»еҪ•зҺҜеўғпјҢ
[root@master ~]#ssh-keygen -t rsa -P ''
chmod 600 .ssh/*
cat .ssh/id_rsa.pub >.ssh/authorized_keys
scp -p .ssh/id_rsa .ssh/authorized_keys 192.168.137.130:/root/.ssh
scp -p .ssh/id_rsa .ssh/authorized_keys 192.168.137.146:/root/.ssh
дәҢгҖҒй…ҚзҪ®mysqlеҚҠеҗҢжӯҘеӨҚеҲ¶
жіЁж„Ҹпјҡmysqlдё»д»ҺеӨҚеҲ¶ж“ҚдҪңжӯӨеӨ„дёҚеҒҡжј”зӨә
masterжҺҲжқғпјҡ
grant replication slave,replication client on *.* to 'repl'@'192.168.137.%' identified by '123456';
grant all on *.* to 'mhauser'@'192.168.137.%' identified by '123456';
CandidateжҺҲжқғпјҡ
grant replication slave,replication client on *.* to 'repl'@'192.168.137.%' identified by '123456';
grant all on *.* to 'mhauser'@'192.168.137.%' identified by '123456';
slaveжҺҲжқғпјҡ
grant all on *.* to 'mhauser'@'192.168.137.%' identified by '123456';
еҰӮжһңз”Ёmysqlй»ҳи®Өзҡ„ејӮжӯҘжЁЎејҸпјҢеҪ“дё»еә“硬件жҚҹеқҸе®•жңәйҖ жҲҗзҡ„ж•°жҚ®дёўеӨұпјҢеӣ жӯӨеңЁй…ҚзҪ®MHAзҡ„еҗҢж—¶е»әи®®й…ҚзҪ®жҲҗMySQLзҡ„еҚҠеҗҢжӯҘеӨҚеҲ¶гҖӮ
жіЁпјҡmysqlеҚҠеҗҢжӯҘжҸ’件жҳҜз”ұи°·жӯҢжҸҗдҫӣпјҢе…·дҪ“дҪҚзҪ®/usr/local/mysql/lib/plugin/дёӢпјҢдёҖдёӘжҳҜmasterз”Ёзҡ„semisync_master.soпјҢдёҖдёӘжҳҜslaveз”Ёзҡ„semisync_slave.soпјҢ
mysql> show variables like '%plugin_dir%';
+---------------+------------------------------+
| Variable_name | Value |
+---------------+------------------------------+
| plugin_dir | /usr/local/mysql/lib/plugin/ |
+---------------+------------------------------+
1гҖҒеҲҶеҲ«еңЁдё»д»ҺиҠӮзӮ№дёҠе®үиЈ…зӣёе…ізҡ„жҸ’件пјҲmaster,Candidate,slaveпјү
еңЁMySQLдёҠе®үиЈ…жҸ’件йңҖиҰҒж•°жҚ®еә“ж”ҜжҢҒеҠЁжҖҒиҪҪе…ҘгҖӮжЈҖжҹҘжҳҜеҗҰж”ҜжҢҒпјҢз”ЁеҰӮдёӢжЈҖжөӢпјҡ
mysql> show variables like '%have_dynamic_loading%';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| have_dynamic_loading | YES
жүҖжңүmysqlж•°жҚ®еә“жңҚеҠЎеҷЁпјҢе®үиЈ…еҚҠеҗҢжӯҘжҸ’件(semisync_master.so,semisync_slave.so)
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
жЈҖжҹҘPluginжҳҜеҗҰе·ІжӯЈзЎ®е®үиЈ…пјҡ
mysql> show plugins;
жҲ–
mysql> select * from information_schema.plugins;
жҹҘзңӢеҚҠеҗҢжӯҘзӣёе…ідҝЎжҒҜ
mysql> show variables like '%rpl_semi_sync%';
rpl_semi_sync_master_enabled | OFF |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_slave_enabled | OFF |
| rpl_semi_sync_slave_trace_level | 32
дёҠеӣҫеҸҜд»ҘзңӢеҲ°еҚҠеҗҢеӨҚеҲ¶жҸ’件已з»Ҹе®үиЈ…пјҢеҸӘжҳҜиҝҳжІЎжңүеҗҜз”ЁпјҢжүҖд»ҘжҳҜOFF
2гҖҒдҝ®ж”№my.cnfж–Ү件пјҢй…ҚзҪ®дё»д»ҺеҗҢжӯҘпјҡ
жіЁпјҡиӢҘдё»MYSQLжңҚеҠЎеҷЁе·Із»ҸеӯҳеңЁпјҢеҸӘжҳҜеҗҺжңҹжүҚжҗӯе»әд»ҺMYSQLжңҚеҠЎеҷЁпјҢеңЁзҪ®й…Қж•°жҚ®еҗҢжӯҘеүҚеә”е…Ҳе°Ҷдё»MYSQLжңҚеҠЎеҷЁзҡ„иҰҒеҗҢжӯҘзҡ„ж•°жҚ®еә“жӢ·иҙқеҲ°д»ҺMYSQLжңҚеҠЎеҷЁдёҠпјҲеҰӮе…ҲеңЁдё»MYSQLдёҠеӨҮд»Ҫж•°жҚ®еә“пјҢеҶҚз”ЁеӨҮд»ҪеңЁд»ҺMYSQLжңҚеҠЎеҷЁдёҠжҒўеӨҚпјү
master mysqlдё»жңәпјҡ
server-id = 1
log-bin=mysql-bin
binlog_format=mixed
log-bin-index=mysql-bin.index
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=10000
rpl_semi_sync_slave_enabled=1
relay_log_purge=0
relay-log= relay-bin
relay-log-index = relay-bin.index
жіЁпјҡ
rpl_semi_sync_master_enabled=1 1иЎЁжҳҜеҗҜз”ЁпјҢ0иЎЁзӨәе…ій—ӯ
rpl_semi_sync_master_timeout=10000пјҡжҜ«з§’еҚ•дҪҚпјҢиҜҘеҸӮж•°дё»жңҚеҠЎеҷЁзӯүеҫ…зЎ®и®Өж¶ҲжҒҜ10з§’еҗҺпјҢдёҚеҶҚзӯүеҫ…пјҢеҸҳдёәејӮжӯҘж–№ејҸгҖӮ
Candidate дё»жңәпјҡ
server-id = 2
log-bin=mysql-bin
binlog_format=mixed
log-bin-index=mysql-bin.index
relay_log_purge=0
relay-log= relay-bin
relay-log-index = slave-relay-bin.index
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=10000
rpl_semi_sync_slave_enabled=1
жіЁпјҡrelay_log_purge=0пјҢзҰҒжӯў SQL зәҝзЁӢеңЁжү§иЎҢе®ҢдёҖдёӘ relay log еҗҺиҮӘеҠЁе°Ҷе…¶еҲ йҷӨпјҢеҜ№дәҺMHAеңәжҷҜдёӢпјҢеҜ№дәҺжҹҗдәӣж»һеҗҺд»Һеә“зҡ„жҒўеӨҚдҫқиө–дәҺе…¶д»–д»Һеә“зҡ„relaylogпјҢеӣ жӯӨйҮҮеҸ–зҰҒз”ЁиҮӘеҠЁеҲ йҷӨеҠҹиғҪ
Slaveдё»жңәпјҡ
Server-id = 3
log-bin = mysql-bin
relay-log = relay-bin
relay-log-index = slave-relay-bin.index
read_only = 1
rpl_semi_sync_slave_enabled = 1
жҹҘзңӢеҚҠеҗҢжӯҘзӣёе…ідҝЎжҒҜ
mysql> show variables like '%rpl_semi_sync%';
жҹҘзңӢеҚҠеҗҢжӯҘзҠ¶жҖҒпјҡ
mysql> show status like '%rpl_semi_sync%';
| Rpl_semi_sync_master_clients | 2 |
йҮҚзӮ№е…іжіЁзҡ„еҸӮж•°пјҡ
rpl_semi_sync_master_status пјҡжҳҫзӨәдё»жңҚеҠЎжҳҜејӮжӯҘеӨҚеҲ¶жЁЎејҸиҝҳжҳҜеҚҠеҗҢжӯҘеӨҚеҲ¶жЁЎејҸ
rpl_semi_sync_master_clients пјҡжҳҫзӨәжңүеӨҡе°‘дёӘд»ҺжңҚеҠЎеҷЁй…ҚзҪ®дёәеҚҠеҗҢжӯҘеӨҚеҲ¶жЁЎејҸ
rpl_semi_sync_master_yes_tx пјҡжҳҫзӨәд»ҺжңҚеҠЎеҷЁзЎ®и®ӨжҲҗеҠҹжҸҗдәӨзҡ„ж•°йҮҸ
rpl_semi_sync_master_no_tx пјҡжҳҫзӨәд»ҺжңҚеҠЎеҷЁзЎ®и®ӨдёҚжҲҗеҠҹжҸҗдәӨзҡ„ж•°йҮҸ
rpl_semi_sync_master_tx_avg_wait_time пјҡдәӢеҠЎеӣ ејҖеҗҜ semi_sync пјҢе№іеқҮйңҖиҰҒйўқеӨ–зӯүеҫ…зҡ„ж—¶й—ҙ
rpl_semi_sync_master_net_avg_wait_time пјҡдәӢеҠЎиҝӣе…Ҙзӯүеҫ…йҳҹеҲ—еҗҺпјҢеҲ°зҪ‘з»ңе№іеқҮзӯүеҫ…ж—¶й—ҙ
дёүгҖҒй…ҚзҪ®mysql-mha
жүҖжңүmysqlиҠӮзӮ№е®үиЈ…
rpm -ivh perl-DBD-MySQL-4.013-3.el6.i686.rpm [yum -y install perl-DBD-MySQL]
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
2. manageйңҖе®үиЈ…дҫқиө–зҡ„perlеҢ…
rpm -ivh perl-Config-Tiny-2.12-7.1.el6.noarch.rpm
rpm -ivh perl-DBD-MySQL-4.013-3.el6.i686.rpm [yum -y install perl-DBD-MySQL]
rpm -ivh compat-db43-4.3.29-15.el6.x86_64.rpm
rpm -ivh perl-Mail-Sender-0.8.16-3.el6.noarch.rpm
rpm -ivh perl-Parallel-ForkManager-0.7.9-1.el6.noarch.rpm
rpm -ivh perl-TimeDate-1.16-11.1.el6.noarch.rpm
rpm -ivh perl-MIME-Types-1.28-2.el6.noarch.rpm
rpm -ivh perl-MailTools-2.04-4.el6.noarch.rpm
rpm -ivh perl-Email-Date-Format-1.002-5.el6.noarch.rpm
rpm -ivh perl-Params-Validate-0.92-3.el6.x86_64.rpm
rpm -ivh perl-Params-Validate-0.92-3.el6.x86_64.rpm
rpm -ivh perl-MIME-Lite-3.027-2.el6.noarch.rpm
rpm -ivh perl-Mail-Sendmail-0.79-12.el6.noarch.rpm
rpm -ivh perl-Log-Dispatch-2.27-1.el6.noarch.rpm
yum install -y perl-Time-HiRes-1.9721-144.el6.x86_64
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
3. й…ҚзҪ®mha
й…ҚзҪ®ж–Ү件дҪҚдәҺз®ЎзҗҶиҠӮзӮ№пјҢйҖҡеёёеҢ…жӢ¬жҜҸдёҖдёӘmysql serverзҡ„дё»жңәеҗҚпјҢmysqlз”ЁжҲ·еҗҚпјҢеҜҶз ҒпјҢе·ҘдҪңзӣ®еҪ•зӯүзӯүгҖӮ
mkdir /etc/masterha/
vim /etc/masterha/app1.cnf
[server default]
user=mhauser
password=123456
manager_workdir=/data/masterha/app1
manager_log=/data/masterha/app1/manager.log
remote_workdir=/data/masterha/app1
ssh_user=root
repl_user=repl
repl_password=123456
ping_interval=1
[server1]
hostname=192.168.137.134
port=3306
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server2]
hostname=192.168.137.130
port=3306
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server3]
hostname=192.168.137.146
port=3306
master_binlog_dir=/usr/local/mysql/data
no_master=1
й…Қе…ій…ҚзҪ®йЎ№зҡ„и§ЈйҮҠпјҡ
manager_workdir=/masterha/app1//и®ҫзҪ®managerзҡ„е·ҘдҪңзӣ®еҪ•
manager_log=/masterha/app1/manager.log//и®ҫзҪ®managerзҡ„ж—Ҙеҝ—
user=manager//и®ҫзҪ®зӣ‘жҺ§з”ЁжҲ·manager
password=123456 //зӣ‘жҺ§з”ЁжҲ·managerзҡ„еҜҶз Ғ
ssh_user=root //sshиҝһжҺҘз”ЁжҲ·
repl_user=mharep //дё»д»ҺеӨҚеҲ¶з”ЁжҲ·
repl_password=123.abc//дё»д»ҺеӨҚеҲ¶з”ЁжҲ·еҜҶз Ғ
ping_interval=1 //и®ҫзҪ®зӣ‘жҺ§дё»еә“пјҢеҸ‘йҖҒpingеҢ…зҡ„ж—¶й—ҙй—ҙйҡ”пјҢй»ҳи®ӨжҳҜ3з§’пјҢе°қиҜ•дёүж¬ЎжІЎжңүеӣһеә”зҡ„ж—¶еҖҷиҮӘеҠЁиҝӣиЎҢfailover
master_binlog_dir=/usr/local/mysql/data //и®ҫзҪ®master дҝқеӯҳbinlogзҡ„дҪҚзҪ®пјҢд»ҘдҫҝMHAеҸҜд»ҘжүҫеҲ°masterзҡ„ж—Ҙеҝ—пјҢжҲ‘иҝҷйҮҢзҡ„д№ҹе°ұжҳҜmysqlзҡ„ж•°жҚ®зӣ®еҪ•
candidate_master=1//и®ҫзҪ®дёәеҖҷйҖүmasterпјҢеҰӮжһңи®ҫзҪ®иҜҘеҸӮж•°д»ҘеҗҺпјҢеҸ‘з”ҹдё»д»ҺеҲҮжҚўд»ҘеҗҺе°Ҷдјҡе°ҶжӯӨд»Һеә“жҸҗеҚҮдёәдё»еә“гҖӮ
жЈҖжөӢеҗ„иҠӮзӮ№й—ҙsshдә’дҝЎйҖҡдҝЎй…ҚзҪ®жҳҜеҗҰok
masterha_check_ssh --conf=/etc/masterha/app1.cnf
з»“жһңпјҡAll SSH connection tests passed successfully.
жЈҖжөӢеҗ„иҠӮзӮ№й—ҙдё»д»ҺеӨҚеҲ¶жҳҜеҗҰok
masterha_check_repl --conf=/etc/masterha/app1.cnf
з»“жһңпјҡMySQL Replication Health is OK.
еңЁйӘҢиҜҒж—¶пјҢиӢҘйҒҮеҲ°иҝҷдёӘй”ҷиҜҜпјҡCan't exec "mysqlbinlog" ......
и§ЈеҶіж–№жі•жҳҜеңЁжүҖжңүжңҚеҠЎеҷЁдёҠжү§иЎҢпјҡ
ln -s /usr/local/mysql/bin/* /usr/local/bin/
еҗҜеҠЁmanager:
nohup /usr/bin/masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover > /etc/masterha/manager.log 2>&1 &
--remove_dead_master_conf дёәдё»д»ҺеҲҮжҚўеҗҺпјҢиҖҒзҡ„дё»еә“IPе°Ҷдјҡд»Һй…ҚзҪ®ж–Ү件дёӯ移йҷӨ
--ignore_last_failover еҝҪз•Ҙз”ҹжҲҗзҡ„еҲҮжҚўе®ҢжҲҗж–Ү件пјҢиӢҘдёҚеҝҪз•ҘпјҢеҲҷ8е°Ҹж—¶еҶ…ж— жі•еҶҚж¬ЎеҲҮжҚў
--ignore_fail_on_start
##еҪ“жңүslave иҠӮзӮ№е®•жҺүж—¶пјҢMHAй»ҳи®ӨжҳҜеҗҜеҠЁдёҚдәҶзҡ„пјҢеҠ дёҠжӯӨеҸӮж•°еҚідҪҝжңүиҠӮзӮ№е®•жҺүд№ҹиғҪеҗҜеҠЁMHAпјҢ
е…ій—ӯMHAпјҡ
masterha_stop --conf=/etc/masterha/app1.cnf
жҹҘзңӢMHAзҠ¶жҖҒпјҡ
masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:45128) is running(0:PING_OK), master:192.168.137.134
4.жЁЎжӢҹж•…йҡңиҪ¬з§»
еҒңжҺүmasterпјҢ
/etc/init.d/mysqld stop
жҹҘзңӢ MHA ж—Ҙеҝ— /data/masterha/app1/manager.log
----- Failover Report -----
app1: MySQL Master failover 192.168.137.134(192.168.137.134:3306) to 192.168.137.1
30(192.168.137.130:3306) succeeded
Master 192.168.137.134(192.168.137.134:3306) is down!
Check MHA Manager logs at zifuji:/data/masterha/app1/manager.log for details.
Started automated(non-interactive) failover.
The latest slave 192.168.137.130(192.168.137.130:3306) has all relay logs for reco
very.
Selected 192.168.137.130(192.168.137.130:3306) as a new master.
192.168.137.130(192.168.137.130:3306): OK: Applying all logs succeeded.
192.168.137.146(192.168.137.146:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.137.146(192.168.137.146:3306): OK: Applying all logs succeeded. Slave star
ted, replicating from 192.168.137.130(192.168.137.130:3306)
192.168.137.130(192.168.137.130:3306): Resetting slave info succeeded.
Master failover to 192.168.137.130(192.168.137.130:3306) completed successfully.
3. жҹҘзңӢslaveеӨҚеҲ¶зҠ¶жҖҒ
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.137.130
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
MHA Manager з«Ҝж—Ҙеёёдё»иҰҒж“ҚдҪңжӯҘйӘӨ
1пјүжЈҖжҹҘжҳҜеҗҰжңүдёӢеҲ—ж–Ү件пјҢжңүеҲҷеҲ йҷӨгҖӮ
еҸ‘з”ҹдё»д»ҺеҲҮжҚўеҗҺпјҢMHAmanagerжңҚеҠЎдјҡиҮӘеҠЁеҒңжҺүпјҢдё”еңЁmanager_workdirпјҲ/data/masterha/app1/app1.failover.completeпјүзӣ®еҪ•дёӢйқўз”ҹжҲҗж–Ү件app1.failover.completeпјҢиӢҘиҰҒеҗҜеҠЁMHAпјҢеҝ…йЎ»е…ҲзЎ®дҝқж— жӯӨж–Ү件)
find / -name 'app1.failover.complete'
rm -f /data/masterha/app1/app1.failover.complete
2пјүжЈҖжҹҘMHAеҪ“еүҚзҪ®пјҡ
# masterha_check_repl --conf=/etc/masterha/app1.cnf
3пјүеҗҜеҠЁMHAпјҡ
#nohup masterha_manager --conf=/etc/masterha/app1.cnf&>/etc/masterha/manager.log &
еҪ“жңүslave иҠӮзӮ№е®•жҺүж—¶пјҢй»ҳи®ӨжҳҜеҗҜеҠЁдёҚдәҶзҡ„пјҢеҠ дёҠ --ignore_fail_on_startеҚідҪҝжңүиҠӮзӮ№е®•жҺүд№ҹиғҪеҗҜеҠЁMHAпјҢеҰӮдёӢпјҡ
#nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_fail_on_start&>/etc/masterha/manager.log &
4пјүеҒңжӯўMHAпјҡ masterha_stop --conf=/etc/masterha/app1.cnf
5пјүжЈҖжҹҘзҠ¶жҖҒпјҡ
# masterha_check_status --conf=/etc/masterha/app1.cnf
6пјүжЈҖжҹҘж—Ҙеҝ—пјҡ
#tail -f /etc/masterha/manager.log
7пјүдё»д»ҺеҲҮжҚў,еҺҹдё»еә“еҗҺз»ӯе·ҘдҪң
vim /etc/my.cnf
read_only=ON
relay_log_purge = 0
mysql> reset slave all;
mysql> reset master;
/etc/init.d/mysqld restart
mysql> CHANGE MASTER TO MASTER_HOST='192.168.137.130',MASTER_USER='repl',MASTER_PASSWORD='123456';
##дёҺж–°дё»еә“еҒҡдё»д»ҺеӨҚеҲ¶
masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:45950) is running(0:PING_OK), master:192.168.137.130
жіЁж„ҸпјҡеҰӮжһңжӯЈеёёпјҢдјҡжҳҫзӨә"PING_OK"пјҢеҗҰеҲҷдјҡжҳҫзӨә"NOT_RUNNING"пјҢиҝҷд»ЈиЎЁMHAзӣ‘жҺ§жІЎжңүејҖеҗҜгҖӮ
е®ҡжңҹеҲ йҷӨдёӯ继ж—Ҙеҝ—
еңЁй…ҚзҪ®дё»д»ҺеӨҚеҲ¶дёӯпјҢslaveдёҠи®ҫзҪ®дәҶеҸӮж•°relay_log_purge=0пјҢжүҖд»ҘslaveиҠӮзӮ№йңҖиҰҒе®ҡжңҹеҲ йҷӨдёӯ继ж—Ҙеҝ—пјҢе»әи®®жҜҸдёӘslaveиҠӮзӮ№еҲ йҷӨдёӯ继ж—Ҙеҝ—зҡ„ж—¶й—ҙй”ҷејҖгҖӮ
corntab -e
0 5 * * * /usr/local/bin/purge_relay_logs - -user=root --password=pwd123 --port=3306 --disable_relay_log_purge >>/var/log/purge_relay.log 2>&1
5гҖҒй…ҚзҪ®VIP
ipй…ҚзҪ®еҸҜд»ҘйҮҮз”ЁдёӨз§Қж–№ејҸпјҢдёҖз§ҚйҖҡиҝҮkeepalivedзҡ„ж–№ејҸз®ЎзҗҶиҷҡжӢҹipзҡ„жө®еҠЁпјӣеҸҰеӨ–дёҖз§ҚйҖҡиҝҮи„ҡжң¬ж–№ејҸеҗҜеҠЁиҷҡжӢҹipзҡ„ж–№ејҸпјҲеҚідёҚйңҖиҰҒkeepalivedжҲ–иҖ…heartbeatзұ»дјјзҡ„иҪҜ件пјүгҖӮ
1гҖҒkeepalivedж–№ејҸз®ЎзҗҶиҷҡжӢҹipпјҢkeepalivedй…ҚзҪ®ж–№жі•еҰӮдёӢпјҡ
еңЁmasterе’ҢCandidateдё»жңәдёҠе®үиЈ…keepalived
е®үиЈ…дҫқиө–еҢ…пјҡ
[root@master ~]# yum install openssl-devel libnfnetlink-devel libnfnetlink popt-devel kernel-devel -y
wget http://www.keepalived.org/software/keepalived-1.2.20.tar.gz
ln -s /usr/src/kernels/2.6.32-642.1.1.el6.x86_64 /usr/src/linux
tar -xzf keepalived-1.2.20.tar.gz;cd keepalived-1.2.20
./configure --prefix=/usr/local/keepalived;make && make install
ln -s /usr/local/keepalived/sbin/keepalived /usr/bin/keepalived
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/keepalived
mkdir /etc/keepalived
ln -s /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf
chmod 755 /etc/init.d/keepalived
chkconfig --add keepalived
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
service keepalived restart
echo 1 > /proc/sys/net/ipv4/ip_forward
дҝ®ж”№Keepalivedзҡ„й…ҚзҪ®ж–Ү件пјҲеңЁmasterдёҠй…ҚзҪ®пјү
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
guopeng@163.com
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id mysql-ha1
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.137.100
}
}
еңЁеҖҷйҖүmasterпјҲCandidateпјүдёҠй…ҚзҪ®
[root@Candidate keepalived-1.2.20]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id mysql-ha2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.137.100
}
}
еҗҜеҠЁkeepalivedжңҚеҠЎпјҢеңЁmasterдёҠеҗҜеҠЁе№¶жҹҘзңӢж—Ҙеҝ—
/etc/init.d/keepalived start
tail -f/var/log/messages
Aug 14 01:05:25 minion Keepalived_vrrp[39720]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.137.100
[root@master ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:57:66:49 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.134/24 brd 192.168.137.255 scope global eth0
inet 192.168.137.100/32 scope global eth0
inet6 fe80::20c:29ff:fe57:6649/64 scope link
valid_lft forever preferred_lft forever
[root@Candidate ~]# ip addr show dev eth0 ##жӯӨж—¶еӨҮйҖүmasterдёҠжҳҜжІЎжңүиҷҡжӢҹipзҡ„
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:a5:b4:85 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.130/24 brd 192.168.137.255 scope global eth0
inet6 fe80::20c:29ff:fea5:b485/64 scope link
valid_lft forever preferred_lft forever
жіЁж„Ҹпјҡ
дёҠйқўдёӨеҸ°жңҚеҠЎеҷЁзҡ„keepalivedйғҪи®ҫзҪ®дёәдәҶBACKUPжЁЎејҸпјҢеңЁkeepalivedдёӯ2з§ҚжЁЎејҸпјҢеҲҶеҲ«жҳҜmaster->backupжЁЎејҸе’Ңbackup->backupжЁЎејҸгҖӮиҝҷдёӨз§ҚжЁЎејҸжңүеҫҲеӨ§еҢәеҲ«гҖӮеңЁmaster->backupжЁЎејҸдёӢпјҢдёҖж—Ұдё»еә“е®•жңәпјҢиҷҡжӢҹipдјҡиҮӘеҠЁжјӮ移еҲ°д»Һеә“пјҢеҪ“дё»еә“дҝ®еӨҚеҗҺпјҢkeepalivedеҗҜеҠЁеҗҺпјҢиҝҳдјҡжҠҠиҷҡжӢҹipжҠўеҚ иҝҮжқҘпјҢеҚідҪҝи®ҫзҪ®дәҶйқһжҠўеҚ жЁЎејҸпјҲnopreemptпјүжҠўеҚ ipзҡ„еҠЁдҪңд№ҹдјҡеҸ‘з”ҹгҖӮеңЁbackup->backupжЁЎејҸдёӢпјҢеҪ“дё»еә“е®•жңәеҗҺиҷҡжӢҹipдјҡиҮӘеҠЁжјӮ移еҲ°д»Һеә“дёҠпјҢеҪ“еҺҹдё»еә“жҒўеӨҚе’ҢkeepalivedжңҚеҠЎеҗҜеҠЁеҗҺпјҢ并дёҚдјҡжҠўеҚ ж–°дё»зҡ„иҷҡжӢҹipпјҢеҚідҪҝжҳҜдјҳе…Ҳзә§й«ҳдәҺд»Һеә“зҡ„дјҳе…Ҳзә§еҲ«пјҢд№ҹдёҚдјҡеҸ‘з”ҹжҠўеҚ гҖӮдёәдәҶеҮҸе°‘ipжјӮ移次数пјҢйҖҡеёёжҳҜжҠҠдҝ®еӨҚеҘҪзҡ„дё»еә“еҪ“еҒҡж–°зҡ„еӨҮеә“гҖӮ
2гҖҒMHAеј•е…ҘkeepalivedпјҲMySQLжңҚеҠЎиҝӣзЁӢжҢӮжҺүж—¶йҖҡиҝҮMHA еҒңжӯўkeepalivedпјү:
иҰҒжғіжҠҠkeepalivedжңҚеҠЎеј•е…ҘMHAпјҢжҲ‘们еҸӘйңҖиҰҒдҝ®ж”№еҲҮжҚўж—¶и§ҰеҸ‘зҡ„и„ҡжң¬ж–Ү件master_ip_failoverеҚіеҸҜпјҢеңЁиҜҘи„ҡжң¬дёӯж·»еҠ еңЁmasterеҸ‘з”ҹе®•жңәж—¶еҜ№keepalivedзҡ„еӨ„зҗҶгҖӮ
зј–иҫ‘и„ҡжң¬/scripts/master_ip_failoverпјҢдҝ®ж”№еҗҺеҰӮдёӢгҖӮ
managerзј–иҫ‘и„ҡжң¬ж–Ү件пјҡ
mkdir /scripts
vim /scripts/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '192.168.137.100';
my $ssh_start_vip = "/etc/init.d/keepalived start";
my $ssh_stop_vip = "/etc/init.d/keepalived stop";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n
";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_h
ost=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_
master_ip=ip --new_master_port=port\n";
}
зҺ°еңЁе·Із»Ҹдҝ®ж”№иҝҷдёӘи„ҡжң¬дәҶпјҢжҺҘдёӢжқҘжҲ‘们еңЁ/etc/masterha/app1.cnf дёӯи°ғз”Ёж•…йҡңеҲҮжҚўи„ҡжң¬
еҒңжӯўMHAпјҡ
masterha_stop --conf=/etc/masterha/app1.cnf
еңЁй…ҚзҪ®ж–Ү件/etc/masterha/app1.cnf дёӯеҗҜз”ЁдёӢйқўзҡ„еҸӮж•°(еңЁ[server defaultдёӢйқўж·»еҠ ])
master_ip_failover_script=/scripts/master_ip_failover
еҗҜеҠЁMHAпјҡ
#nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/etc/masterha/manager.log &
жЈҖжҹҘзҠ¶жҖҒпјҡ
]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:51284) is running(0:PING_OK), master:192.168.137.134
жЈҖжҹҘйӣҶзҫӨеӨҚеҲ¶зҠ¶жҖҒжҳҜеҗҰжңүжҠҘй”ҷ:
]# masterha_check_repl --conf=/etc/masterha/app1.cnf
192.168.137.134(192.168.137.134:3306) (current master)
+--192.168.137.130(192.168.137.130:3306)
+--192.168.137.146(192.168.137.146:3306)
Tue May 9 14:40:57 2017 - [info] Checking replication health on 192.168.137.130..
Tue May 9 14:40:57 2017 - [info] ok.
Tue May 9 14:40:57 2017 - [info] Checking replication health on 192.168.137.146..
Tue May 9 14:40:57 2017 - [info] ok.
Tue May 9 14:40:57 2017 - [info] Checking master_ip_failover_script status:
Tue May 9 14:40:57 2017 - [info] /scripts/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.137.134 --orig_master_ip=192.168.137.134 --orig_master_port=3306
IN SCRIPT TEST====/etc/init.d/keepalived stop==/etc/init.d/keepalived start===
Checking the Status of the script.. OK
Tue May 9 14:40:57 2017 - [info] OK.
Tue May 9 14:40:57 2017 - [warning] shutdown_script is not defined.
Tue May 9 14:40:57 2017 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
жіЁж„Ҹпјҡ /scripts/master_ip_failoverж·»еҠ жҲ–иҖ…дҝ®ж”№зҡ„еҶ…е®№ж„ҸжҖқжҳҜеҪ“дё»еә“ж•°жҚ®еә“еҸ‘з”ҹж•…йҡңж—¶пјҢдјҡи§ҰеҸ‘MHAеҲҮжҚўпјҢMHA ManagerдјҡеҒңжҺүдё»еә“дёҠзҡ„keepalivedжңҚеҠЎпјҢи§ҰеҸ‘иҷҡжӢҹipжјӮ移еҲ°еӨҮйҖүд»Һеә“пјҢд»ҺиҖҢе®ҢжҲҗеҲҮжҚўгҖӮ
еҪ“然еҸҜд»ҘеңЁkeepalivedйҮҢйқўеј•е…Ҙи„ҡжң¬пјҢиҝҷдёӘи„ҡжң¬зӣ‘жҺ§mysqlжҳҜеҗҰжӯЈеёёиҝҗиЎҢпјҢеҰӮжһңдёҚжӯЈеёёпјҢеҲҷи°ғз”ЁиҜҘи„ҡжң¬жқҖжҺүkeepalivedиҝӣзЁӢпјҲеҸӮиҖғMySQL й«ҳеҸҜз”ЁжҖ§keepalived+mysqlеҸҢдё»пјүгҖӮ
жөӢиҜ•пјҡеңЁmasterдёҠеҒңжҺүmysql
[root@master ~]# /etc/init.d/mysqld stop
Shutting down MySQL............ [ OK ]
еҲ°slave(192.168.137.146)жҹҘзңӢslaveзҡ„зҠ¶жҖҒпјҡ
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.137.130
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮәslaveжҢҮеҗ‘дәҶж–°зҡ„masterжңҚеҠЎеҷЁ192.168.137.130(еңЁж•…йҡңеҲҮжҚўеүҚжҢҮеҗ‘зҡ„жҳҜ192.168.137.134)
жҹҘзңӢvipз»‘е®ҡпјҡ
еңЁ192.168.137.134дёҠжҹҘзңӢvipз»‘е®ҡ
[root@master ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:57:66:49 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.134/24 brd 192.168.137.255 scope global eth0
inet6 fe80::20c:29ff:fe57:6649/64 scope link
valid_lft forever preferred_lft forever
еңЁ192.168.137.130дёҠжҹҘзңӢvipз»‘е®ҡ
[root@Candidate ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:a5:b4:85 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.130/24 brd 192.168.137.255 scope global eth0
inet 192.168.137.100/32 scope global eth0
д»ҺдёҠйқўзҡ„жҳҫзӨәз»“жһңеҸҜд»ҘзңӢеҮәvipең°еқҖжјӮ移еҲ°дәҶ192.168.137.130
дё»д»ҺеҲҮжҚўеҗҺз»ӯе·ҘдҪңпјҡзҺ°еңЁCandidateеҸҳжҲҗдё»пјҢйңҖеҜ№еҺҹmasterйҮҚж–°еҒҡеҸӘд»ҺеӨҚеҲ¶ж“ҚдҪң
дҝ®еӨҚжҲҗд»Һеә“
еҗҜеҠЁkeepalived
rm -fr app1.failover.complete
еҗҜеҠЁmanager
3гҖҒйҖҡиҝҮи„ҡжң¬е®һзҺ°VIPеҲҮжҚў
еҰӮжһңдҪҝз”Ёи„ҡжң¬з®ЎзҗҶvipзҡ„иҜқпјҢйңҖиҰҒжүӢеҠЁеңЁmasterжңҚеҠЎеҷЁдёҠз»‘е®ҡдёҖдёӘvip
]#/sbin/ifconfig eth0:0 192.168.137.100/24
vim /scripts/master_ip_failover
my $vip = '192.168.137.100/24';
my $key = '0';
my $ssh_start_vip = "/sbin/ifconfigeth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfigeth0:$key down";
д№ӢеҗҺзҡ„ж“ҚдҪңеҗҢдёҠиҝ°keepalivedж“ҚдҪң
дёәдәҶйҳІжӯўи„‘иЈӮеҸ‘з”ҹпјҢжҺЁиҚҗз”ҹдә§зҺҜеўғйҮҮз”Ёи„ҡжң¬зҡ„ж–№ејҸжқҘз®ЎзҗҶиҷҡжӢҹipпјҢиҖҢдёҚжҳҜдҪҝз”ЁkeepalivedжқҘе®ҢжҲҗгҖӮеҲ°жӯӨдёәжӯўпјҢеҹәжң¬MHAйӣҶзҫӨе·Із»Ҹй…ҚзҪ®е®ҢжҜ•гҖӮ





