这篇文章将为大家详细讲解有关爬取前程无忧python职位信息的方法步骤,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
爬取前程无忧python职位信息的步骤:
1、分析网页,查找需要的数据所在位置
网站地址:
https://search.51job.com/list/000000,000000,0000,00,9,99,%2520,2,1.html
(1)进入该网站,输入关键词“python”,如下:
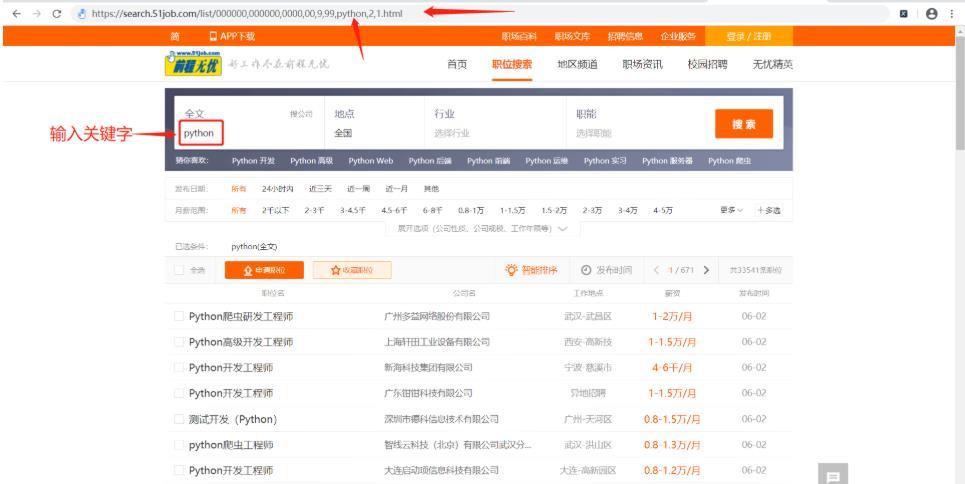
可以发现输入关键字后链接也对应出现了“python”关键字,根据这个规律可以实现进入任意搜索关键词的网页。
(2)紧接着检查网页源代码,看看网页数据是否在源代码内:
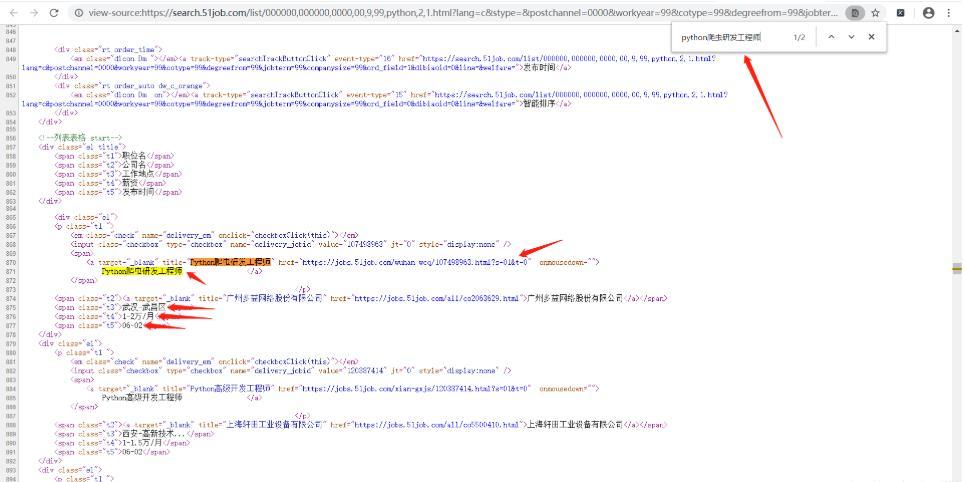
可以发现职位的详情网址、职位名称、薪资等信息都显示在网页源代码内,确定改数据为静态数据,可以使用xpath解析语法来获取。职位的详情页也可以根据此方法来判断是否存在网页源代码,结果也是存在的。
(3)我们点击第二页后发现网址也对应发生改变:
第一页:
https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html
第二页:
https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,2.html
可以发现链接的倒数第一个数字发生了变化,由1变成2,由此可以判断这个位置的数字是控制页数的。接下来可以实现代码了。
2、导入需要使用到的模块,编写爬取函数以及存储函数
(1)爬虫使用到的模块:
import requests # 网络请求库 from lxml import etree # 解析模块 import time # 时间模块 import csv # csv模块 import urllib3 # urllib3,主要用来关掉警告信息 from requests.adapters import HTTPAdapter # HTTPAdapter,主要用来重新请求
(2)__init__初始化函方法:
def __init__(self):
self.keyword = input("请输入搜索关键词:")
self.url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,{}.html' # 网页url
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'} # 设置请求头
self.requests = requests.Session() # 创建csv对象,用于保存会话
self.requests.mount('http://', HTTPAdapter(max_retries=3)) # 增加http请求次数,这里是因为有时候我们这边网络不好,导致请求出不来,或者对方没响应给我们,导致报错。添加这段代码可以重新请求
self.requests.mount('https://', HTTPAdapter(max_retries=3)) # 增加https请求次数,这里是因为有时候我们这边网络不好,导致请求出不来,或者对方没响应给我们,导致报错。添加这段代码可以重新请求
self.header = ['position', 'company', 'wages', 'place', 'education','work_experience', 'release_date', 'limit_people', 'address', 'company_type', 'company_size', 'industry', 'point_information'] # csv头部信息
self.fp = open('python招聘职位.csv', 'a', encoding='utf-8', newline='') # 创建保存csv的句柄
self.writer = csv.DictWriter(self.fp, self.header) # 创建writer,用于后面写入数据
self.writer.writeheader() # 保写入csv头部信息
urllib3.disable_warnings() # 下面的请求中移除了ssl认证会生成警告信息,所以这里取消警告输出(3)下面单独实现一个可以获取总页数的方法:
def get_end_page(self): # 该函数可以获取最后一页的页数
response = self.requests.get(self.url.format(self.keyword, str(1)), headers=self.headers, timeout=4, verify=False)
text = response.content.decode('gb18030') # 使用gb18030解码几乎适用所有网页,不适用的网页只有个别,是从其他网站加载的,解析方式不一样,直接忽略掉。
html = etree.HTML(text)
txt = "".join(html.xpath("//div[@class='dw_page']//div[@class='p_in']/span[1]/text()")) # 获取包含总页数的一段字符串txt
end_page = int(txt.split('页', 1)[0][1:]) # 从字符串txt提取总页数
return end_page(4)获取详情页信息的方法:
def parse_url(self, url):
response = self.requests.get(url=url, headers=self.headers, timeout=5, verify=False)
try: # 这里可能会出现解码错误,因为有个别很少的特殊网页结构,另类来的,不用管
text = response.content.decode('gb18030')
except Exception as e:
print("特殊网页字节解码错误:{},结束执行该函数,解析下一个详情url".format(e))
return # 直接结束函数,不解析
html = etree.HTML(text)
try: # 如果职位名获取不到会异常,因为这个详情url的网页形式也很特殊,很少会出现这种url,所以就return结束函数,进入下一个详情url
position = html.xpath("//div[@class='tHeader tHjob']//div[@class='cn']/h2/@title")[0] # 职位名
except:
return
company = "".join(html.xpath("//div[@class='tHeader tHjob']//div[@class='cn']/p[1]/a[1]//text()")) # 公司名
wages = "".join(html.xpath("//div[@class='tHeader tHjob']//div[@class='cn']/strong/text()")) # 工资
informations = html.xpath("//div[@class='tHeader tHjob']//div[@class='cn']/p[2]/text()") # 获取地点经验学历等信息
informations = [i.strip() for i in informations] # 将元素两边去除空格
place = informations[0] # 工作地点
education = "".join([i for i in informations if i in '本科大专应届生在校生硕士']) # 通过列表推导式获取学历
work_experience = "".join([i for i in informations if '经验' in i ]) # 获取工作经验
release_date = "".join([i for i in informations if '发布' in i]) # 获取发布时间
limit_people = "".join([i for i in informations if '招' in i]) # 获取招聘人数
address = "".join(html.xpath("//div[@class='tCompany_main']/div[2]/div[@class='bmsg inbox']/p/text()")) # 上班地址
company_type = "".join(html.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[1]/@title")) # 公司类型
company_size = "".join(html.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[2]/@title")) # 公司规模
industry = "".join(html.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[3]/@title")) # 所属行业
point_information = html.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]//text()')
point_information = "".join([i.strip() for i in point_information if i != '\xa0\xa0\xa0\xa0']).replace("\xa0", "") # 职位信息
if len(point_information) == 0: # 有一些详情url的职位信息的html标签有点区别,所以判断一下,长度为0就换下面的解析语法
point_information = html.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]/text()')
point_information = "".join([i.strip() for i in point_information])
if len(point_information) == 0: # 有一些详情url的职位信息的html标签有点区别,所以判断一下,长度为0就换下面的解析语法
point_information = html.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]//tbody//text()')
point_information = "".join([i.strip() for i in point_information])
if len(point_information) == 0: # 有一些详情url的职位信息的html标签有点区别,所以判断一下,长度为0就换下面的解析语法
point_information = html.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]/ol//text()')
point_information = "".join([i.strip() for i in point_information])
item = {'position':position, 'company':company, 'wages':wages, 'place':place, 'education':education, 'work_experience':work_experience, 'release_date':release_date, 'limit_people':limit_people, 'address':address, 'company_type':company_type, 'company_size':company_size, 'industry':industry,'point_information':point_information} # 把解析到的数据放入字典中
self.writer.writerow(item) # 保存数据(5)完整代码:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : xxx
# @Author : xx
# @File : 51job.py
import requests # 网络请求库
from lxml import etree # 解析模块
import time # 时间模块
import csv # csv模块
import urllib3 # urllib3,主要用来关掉警告信息
from requests.adapters import HTTPAdapter # HTTPAdapter,主要用来重新请求
class PositionSpider(object):
def __init__(self):
self.keyword = input("请输入搜索关键词:")
self.url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,{}.html' # 网页url
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'} # 设置请求头
self.requests = requests.Session() # 创建csv对象,用于保存会话
self.requests.mount('http://', HTTPAdapter(max_retries=3)) # 增加http请求次数,这里是因为有时候我们这边网络不好,导致请求出不来,或者对方没响应给我们,导致报错。添加这段代码可以重新请求
self.requests.mount('https://', HTTPAdapter(max_retries=3)) # 增加https请求次数,这里是因为有时候我们这边网络不好,导致请求出不来,或者对方没响应给我们,导致报错。添加这段代码可以重新请求
self.header = ['position', 'company', 'wages', 'place', 'education','work_experience', 'release_date', 'limit_people', 'address', 'company_type', 'company_size', 'industry', 'point_information'] # csv头部信息
self.fp = open('python招聘职位.csv', 'a', encoding='utf-8', newline='') # 创建保存csv的句柄
self.writer = csv.DictWriter(self.fp, self.header) # 创建writer,用于后面写入数据
self.writer.writeheader() # 保写入csv头部信息
urllib3.disable_warnings() # 下面的请求中移除了ssl认证会生成警告信息,所以这里取消警告输出
def get_end_page(self): # 该函数可以获取最后一页的页数
response = self.requests.get(self.url.format(self.keyword, str(1)), headers=self.headers, timeout=4, verify=False)
text = response.content.decode('gb18030') # 使用gb18030解码几乎适用所有网页,不适用的网页只有个别,是从其他网站加载的,解析方式不一样,直接忽略掉。
html = etree.HTML(text)
txt = "".join(html.xpath("//div[@class='dw_page']//div[@class='p_in']/span[1]/text()")) # 获取包含总页数的一段字符串txt
end_page = int(txt.split('页', 1)[0][1:]) # 从字符串txt提取总页数
return end_page
def get_url(self, count):
num = 0 # 用于判断是请求响应失败,还是页数到底了
while True: # 这里设置while是因为有时候请求太快,响应跟不上,会获取不到数据。也可以使用睡眠的方法。
num += 1
response = self.requests.get(url=self.url.format(self.keyword, count), headers=self.headers, timeout=4, verify=False) # 发起get请求
text = response.content.decode('gb18030')
html = etree.HTML(text)
detail_urls = html.xpath("//div[@class='dw_table']/div[@class='el']//p/span/a/@href") # 使用xpath语法提取该页所有详情url
if len(detail_urls) == 0: # 列表长度为零就重新请求,这一步是因为有时候发送请求过快,对方服务器跟不上我们速度,导致返回数据为空,所以下面睡眠一下,重新请求
time.sleep(2) # 睡眠一下
continue
else:
break
return detail_urls # 返回列表,将详情url给下一个函数进行解析获取数据
def parse_url(self, url):
response = self.requests.get(url=url, headers=self.headers, timeout=5, verify=False)
try: # 这里可能会出现解码错误,因为有个别很少的特殊网页结构,另类来的,不用管
text = response.content.decode('gb18030')
except Exception as e:
print("特殊网页字节解码错误:{},结束执行该函数,解析下一个详情url".format(e))
return # 直接结束函数,不解析
html = etree.HTML(text)
try: # 如果职位名获取不到会异常,因为这个详情url的网页形式也很特殊,很少会出现这种url,所以就return结束函数,进入下一个详情url
position = html.xpath("//div[@class='tHeader tHjob']//div[@class='cn']/h2/@title")[0] # 职位名
except:
return
company = "".join(html.xpath("//div[@class='tHeader tHjob']//div[@class='cn']/p[1]/a[1]//text()")) # 公司名
wages = "".join(html.xpath("//div[@class='tHeader tHjob']//div[@class='cn']/strong/text()")) # 工资
informations = html.xpath("//div[@class='tHeader tHjob']//div[@class='cn']/p[2]/text()") # 获取地点经验学历等信息
informations = [i.strip() for i in informations] # 将元素两边去除空格
place = informations[0] # 工作地点
education = "".join([i for i in informations if i in '本科大专应届生在校生硕士']) # 通过列表推导式获取学历
work_experience = "".join([i for i in informations if '经验' in i ]) # 获取工作经验
release_date = "".join([i for i in informations if '发布' in i]) # 获取发布时间
limit_people = "".join([i for i in informations if '招' in i]) # 获取招聘人数
address = "".join(html.xpath("//div[@class='tCompany_main']/div[2]/div[@class='bmsg inbox']/p/text()")) # 上班地址
company_type = "".join(html.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[1]/@title")) # 公司类型
company_size = "".join(html.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[2]/@title")) # 公司规模
industry = "".join(html.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[3]/@title")) # 所属行业
point_information = html.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]//text()')
point_information = "".join([i.strip() for i in point_information if i != '\xa0\xa0\xa0\xa0']).replace("\xa0", "") # 职位信息
if len(point_information) == 0: # 有一些详情url的职位信息的html标签有点区别,所以判断一下,长度为0就换下面的解析语法
point_information = html.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]/text()')
point_information = "".join([i.strip() for i in point_information])
if len(point_information) == 0: # 有一些详情url的职位信息的html标签有点区别,所以判断一下,长度为0就换下面的解析语法
point_information = html.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]//tbody//text()')
point_information = "".join([i.strip() for i in point_information])
if len(point_information) == 0: # 有一些详情url的职位信息的html标签有点区别,所以判断一下,长度为0就换下面的解析语法
point_information = html.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]/ol//text()')
point_information = "".join([i.strip() for i in point_information])
item = {'position':position, 'company':company, 'wages':wages, 'place':place, 'education':education, 'work_experience':work_experience, 'release_date':release_date, 'limit_people':limit_people, 'address':address, 'company_type':company_type, 'company_size':company_size, 'industry':industry,'point_information':point_information} # 把解析到的数据放入字典中
self.writer.writerow(item) # 保存数据
if __name__ == '__main__':
print("爬虫开始")
spider = PositionSpider() # 创建类的对象spider
end_page = spider.get_end_page() # 获取该职位的总页数
print("总页数:{}".format(str(end_page)))
for count in range(1, end_page+1): # 遍历总页数
detail_urls = spider.get_url(count) # 获取详情url方法,接收列表
for detail_url in detail_urls: # 遍历获取的详情url
time.sleep(0.2) # 稍微睡眠一下
spider.parse_url(detail_url) # 解析详情页获取数据
print("已爬取第{}页".format(count))
spider.fp.close() # 关闭句柄
print("爬取结束")采集结果:
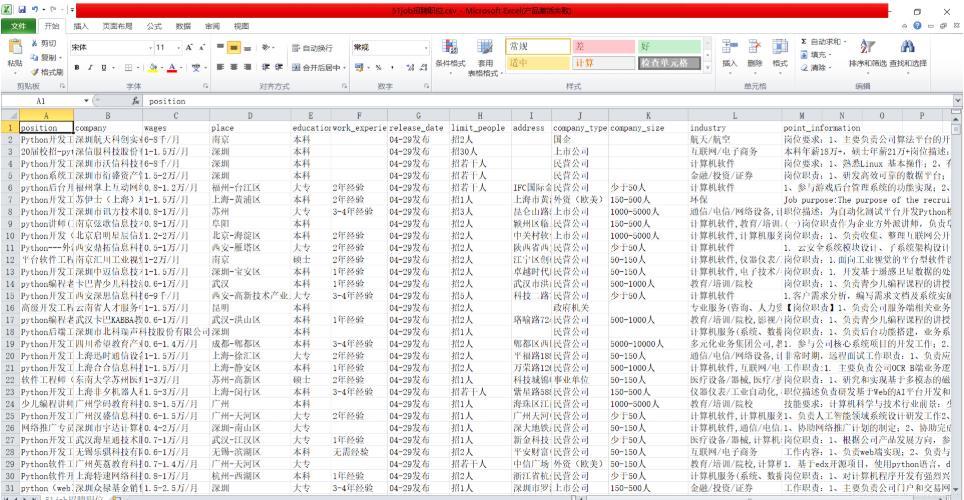
关于爬取前程无忧python职位信息的方法步骤就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





