这篇文章主要介绍python爬取简书网文章的方法,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
python爬取简书网文章的步骤:
1、准备工作,创建scrapy爬虫,建立数据库和表
# 打开 CMD 或者终端到一个指定目录 # 新建一个项目 scrapy startproject jianshu_spider cd jianshu_spider # 创建一个爬虫 scrapy genspider -t crawl jianshu "jianshu.com"
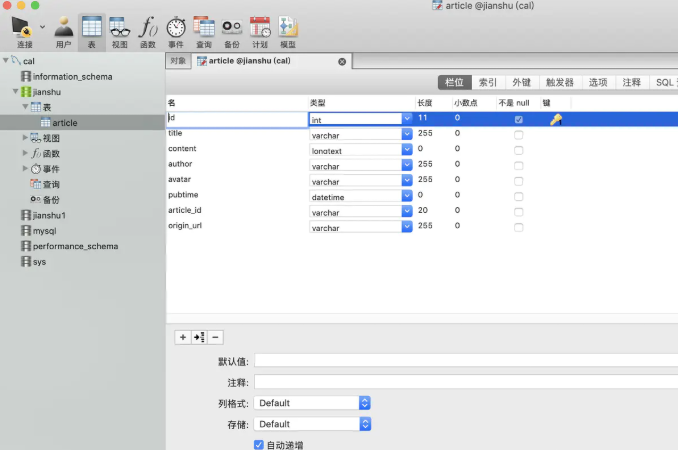
2、爬取思路,检查网页的所有href属性,获取文章链接地址
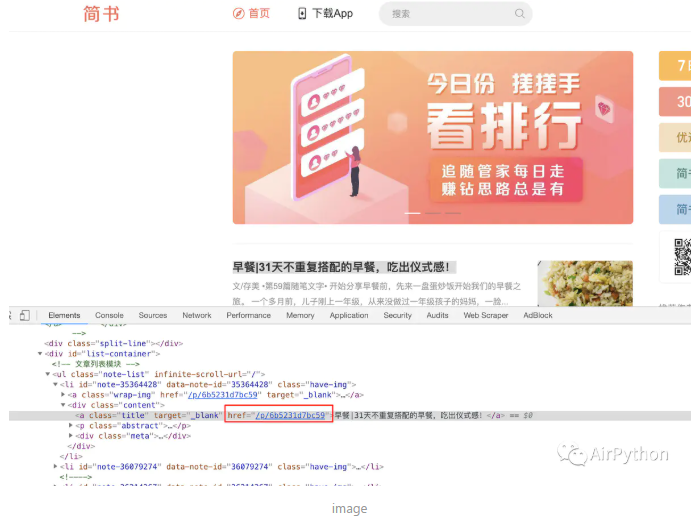
3、代码实现,解析主页网址获取文章链接,构建item模型保存数据,将获取的数据保存到数据库中
第一步是指定开始爬取的地址和爬取规则。
allowed_domains = ['jianshu.com']
start_urls = ['https://www.jianshu.com/']
rules = ( # 文章id是有12位小写字母或者数字0-9构成
Rule(LinkExtractor(allow=r'.*/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True), )第二步是拿到下载器下载后的数据 Response,利用 Xpath 语法获取有用的数据。这里可以使用「 Scrapy shell url 」去测试数据是否获取正确。
# 获取需要的数据
title = response.xpath('//h2[@class="title"]/text()').get()
author = response.xpath('//div[@class="info"]/span/a/text()').get()
avatar = self.HTTPS + response.xpath('//div[@class="author"]/a/img/@src').get()
pub_time = response.xpath('//span[@class="publish-time"]/text()').get().replace("*", "")
current_url = response.url real_url = current_url.split(r"?")[0]
article_id = real_url.split(r'/')[-1]
content = response.xpath('//div[@class="show-content"]').get()然后构建 Item 模型用来保存数据。
import scrapy # 文章详情Itemclass ArticleItem(scrapy.Item): title = scrapy.Field() content = scrapy.Field() # 文章id article_id = scrapy.Field() # 原始的url origin_url = scrapy.Field() # 作者 author = scrapy.Field() # 头像 avatar = scrapy.Field() # 发布时间 pubtime = scrapy.Field()
第三步是将获取的数据通过 Pipline 保存到数据库中。
# 数据库连接属性
db_params = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': 'root',
'database': 'jianshu',
'charset': 'utf8'
}
# 数据库【连接对象】
self.conn = pymysql.connect(**db_params)# 执行 sql 语句 self.cursor.execute(self._sql,(item['title'],item['content'],item['author'],item['avatar'],item['pubtime'],item['article_id'],item['origin_url'])) # 插入到数据库中 self.conn.commit() # 关闭游标资源 self.cursor.close()
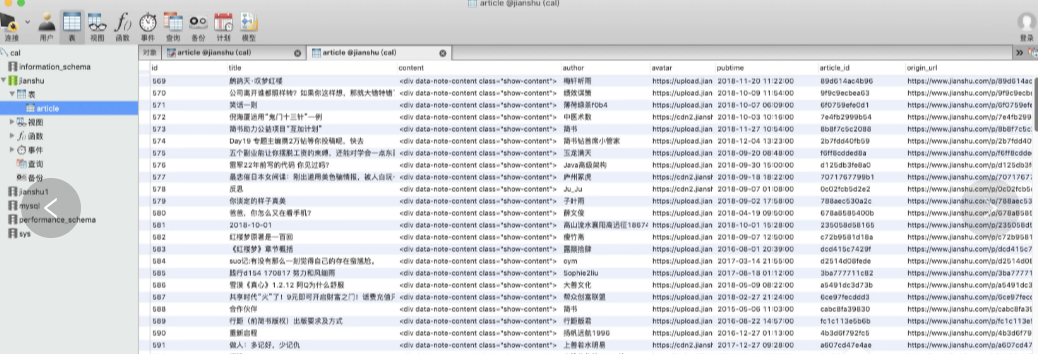
执行结果如下:
以上是python爬取简书网文章的方法的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





